В мире, где только свой бизнес может сделать тебя по-настоящему богатым, люди до сих пор идут работать по найму. Во-первых, не все счастливы быть бизнесменами, а жить надо. Во-вторых, на работе все понятно и безопасно — ты выполняешь свою функцию, а большинство рисков берут на себя другие. Отсюда растут старые замусоленные конфликты: владельцы хотят, чтобы сотрудники были мотивированы, как будто работа — их собственное дело; сотрудники хотят делать то, за что им платят, и не больше.
У этих классических отношений есть вариации — опционы, проценты, бонусы, которые немного напоминают, что владельцы и сотрудники в одной лодке. Но бывают и менее типичные ситуации.
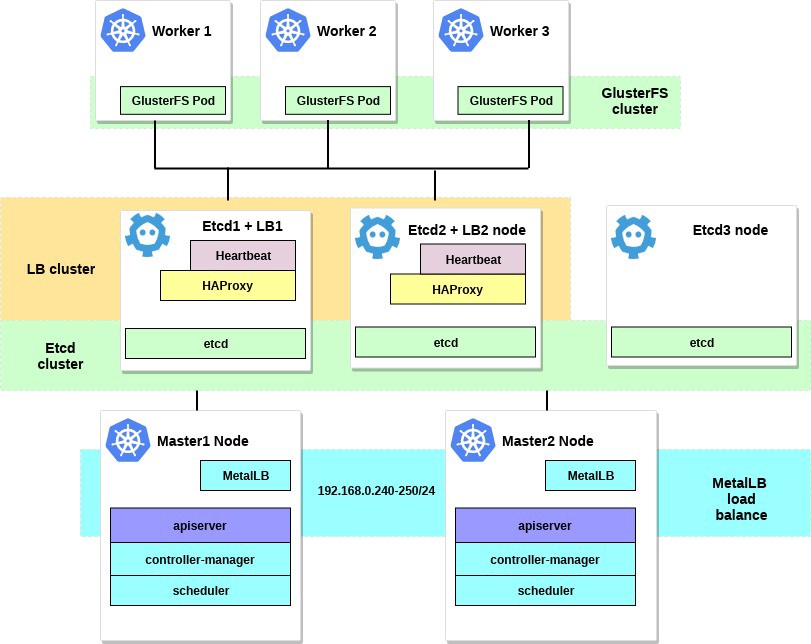
Компания Флант состоит из нескольких команд девопосов, которые обслуживают чужие продакшены под ключ. Они выросли из банды студентов-энтузиастов и фанатов Linux, а сейчас построили структуру «бизнесов внутри бизнеса», просто потому что так комфортнее и честнее. Дима Столяров и Саша Баталов рассказали нам, как это устроено.
Флант попал в рейтинг лучших ИТ-работодателей 2018 со средней оценкой 4.68. Судя по оценкам компании на «Моём круге», сотрудники верят, что компания делает мир лучше, а ещё ценят Флант за интересные задачи, хорошие отношения в коллективе, современные технологии и связь с топ-менеджментом.