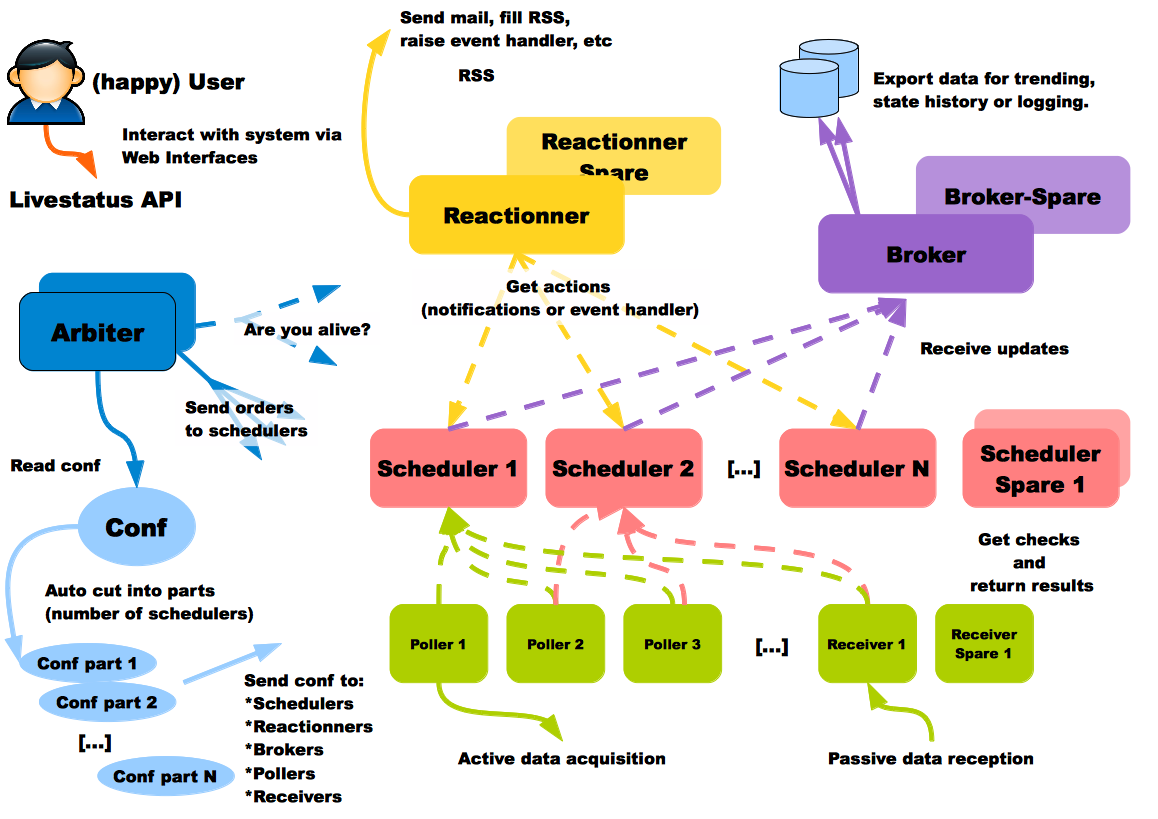
Как создать в большой компании удобное рабочее место для распределённых команд?
8 мин
Последнее время многие крупные компании пытаются внедрить у себя практики DevOps, чтобы ускорить процесс доставки ценности до клиента. Работающие над продуктом люди собираются в одну команду, работают в едином информационном поле. Что же делать большой компании, если сотрудники её команд не могут собраться в одной комнате, а разбросаны по разным офисам, возможно, даже в разных городах и часовых поясах?
Напрашивается ответ — зарегистрироваться в интернет-сервисах для ведения совместной разработки (GitHub, Slack, Evernote, Wunderlist...). Но что делать, если в твоя большая компания работает, например, с клиентскими данными или финансовой информацией, и не может доверить её интернет-сервисам? Единственный выход — развернуть у себя внутри сети инфраструктуру распределённой разработки.
Но как это сделать, чтобы обеспечить безопасность данных и процессов, при этом не потерять в скорости и удобстве работы? На этот вопрос я и постараюсь ответить в данной статье.

Напрашивается ответ — зарегистрироваться в интернет-сервисах для ведения совместной разработки (GitHub, Slack, Evernote, Wunderlist...). Но что делать, если в твоя большая компания работает, например, с клиентскими данными или финансовой информацией, и не может доверить её интернет-сервисам? Единственный выход — развернуть у себя внутри сети инфраструктуру распределённой разработки.
Но как это сделать, чтобы обеспечить безопасность данных и процессов, при этом не потерять в скорости и удобстве работы? На этот вопрос я и постараюсь ответить в данной статье.
 Новогодние праздники закончились, на CES анонсировали все что можно и нельзя, Atlassian купила Trello, а все крупные производители смартфонов запатентовали раскладушку из WestWorld. И даже Шерлока слили, посмотрели и обсудили. Все проснулись, приступили к работе, а некоторые даже нашли в себе силы организовать весенние конференции. Под катом я хочу немного рассказать вам про
Новогодние праздники закончились, на CES анонсировали все что можно и нельзя, Atlassian купила Trello, а все крупные производители смартфонов запатентовали раскладушку из WestWorld. И даже Шерлока слили, посмотрели и обсудили. Все проснулись, приступили к работе, а некоторые даже нашли в себе силы организовать весенние конференции. Под катом я хочу немного рассказать вам про