Электронный словарь сегодня стал одним из основных инструментов переводчика, наряду с браузером, оцифрованными справочниками и
базами соответствий (последнее важно в основном лишь для переводчиков нехудожественных текстов).
Среди электронных словарей ABBYY Lingvo отличается одной ключевой особенностью: полнотекстовым поиском с индексацией. Что-то похожее можно реализовать при помощи индексов в Adobe Acrobat, но удобство интерфейсов именно в словарной области не подлежит сравнению.
ABBYY Lingvo давно уже превратился из обычного словаря в универсальный агрегатор источников. Вдобавок к титанической работе фирмы-создателя, энтузиастами оцифрованы в формат Lingvo сотни пособий, в том числе и основные двуязычные словари, и многотомные толковые словари серий Cambridge, Collins, Longman, Merriam-Webster, Oxford, и энциклопедические словари вроде Британики. Созданы локальные копии сетевых гигантов (Википедий, Викисловарей, Urban Dictionary и так далее). И при обычном использовании это предоставляло бы исключительные возможности. Но при полнотекстовом поиске всё это богатство превращается ещё и в языковые корпусы и базы соответствий. Значение такого поиска при переводах сложных терминов, устойчивых словосочетаний, фразеологизмов трудно переоценить.
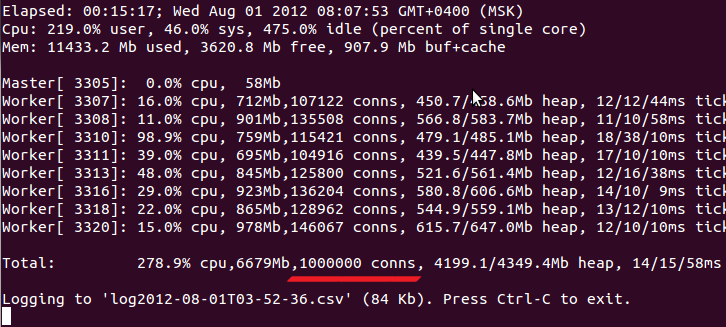
С каждым выпуском ABBYY расширяет допустимые границы компилируемых словарей и поисковых индексов. Уже сейчас можно скомпилировать словарь размером почти в 2 гигабайта исходного текста. Однако при подключении большого количества словарей индекс разрастается. И сами словари на диске, и поисковый пользовательский индекс также могут достигать гигабайтных размеров. При этом полнотекстовый поиск замедляется, на него начинает влиять скорость работы винчестеров. Эпоха развития SSD может помочь в решении этой проблемы, но пока эти механизмы ещё не используются повсеместно из-за большей цены и меньшей износоустойчивости. К счастью, есть способ, по приросту скорости выигрывающий даже у SSD.


















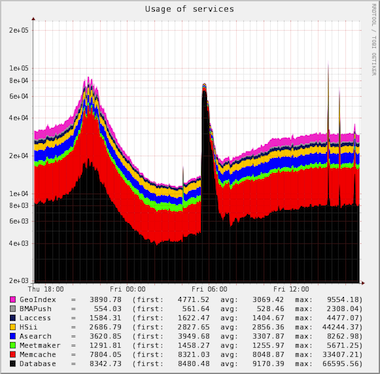 Давайте представим себе типичный, набирающий популярность стартап, использующий, например, PHP или Python. Сначала все находится на одном сервере — PHP (или Python), Apache, MySQL. Затем вы выносите MySQL на отдельный сервер, устанавливаете nginx для раздачи контента, возможно, добавляете memcached для кеширования и еще несколько серверов приложений…
Давайте представим себе типичный, набирающий популярность стартап, использующий, например, PHP или Python. Сначала все находится на одном сервере — PHP (или Python), Apache, MySQL. Затем вы выносите MySQL на отдельный сервер, устанавливаете nginx для раздачи контента, возможно, добавляете memcached для кеширования и еще несколько серверов приложений…