Искусство ETL. Пишем собственный движок SQL на Spark [часть 3 из 5]
В данной серии статей я подробно рассказываю о том, как написать на Java собственный интерпретатор объектно-ориентированного диалекта SQL с использованием Spark RDD API, заточенный на задачи подготовки и трансформации наборов данных.
Краткое содержание предыдущей серии, последней, посвящённой проектированию спецификации языка:
Операторы жизненного цикла наборов данных (продолжение)
Операторы контроля потока выполнения
Операторы управления контекстом исполнения
Операторы выражений
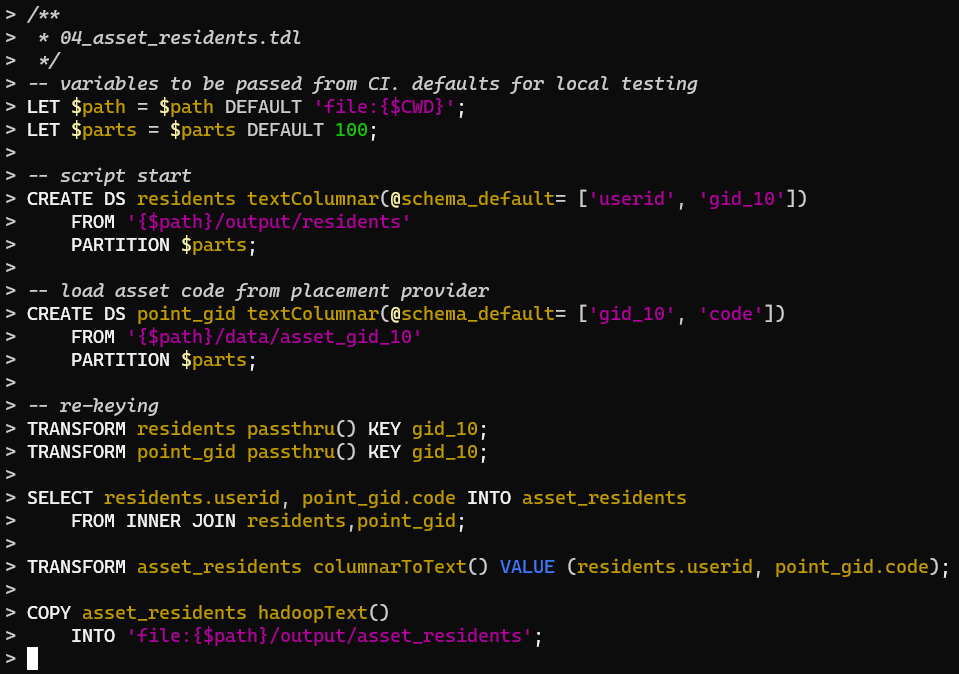
В данном эпизоде мы наконец-то перейдём к самому интересному — имплементации. Хорошо, когда есть развёрнутая постановка задачи, можно просто брать спеку, и писать код согласно плану.
Уровень сложности данной серии статей — высокий. Базовые понятия по ходу текста вообще не объясняются, да и продвинутые далеко не все. Поэтому, если вы не разработчик, уже знакомый с терминологией из области бигдаты и жаргоном из дата инжиниринга, данные статьи будут сложно читаться, и ещё хуже пониматься. Я предупредил.