
Не далее, как в прошлую пятницу у меня было интервью в одной компании в Palo Alto на позицию Data Scientist и этот многочасовой марафон из технических и не очень вопросов должен был начаться с моей презентации о каком-нибудь проекте, в котором я занимался анализом данных. Продолжительность — 20-30 минут.
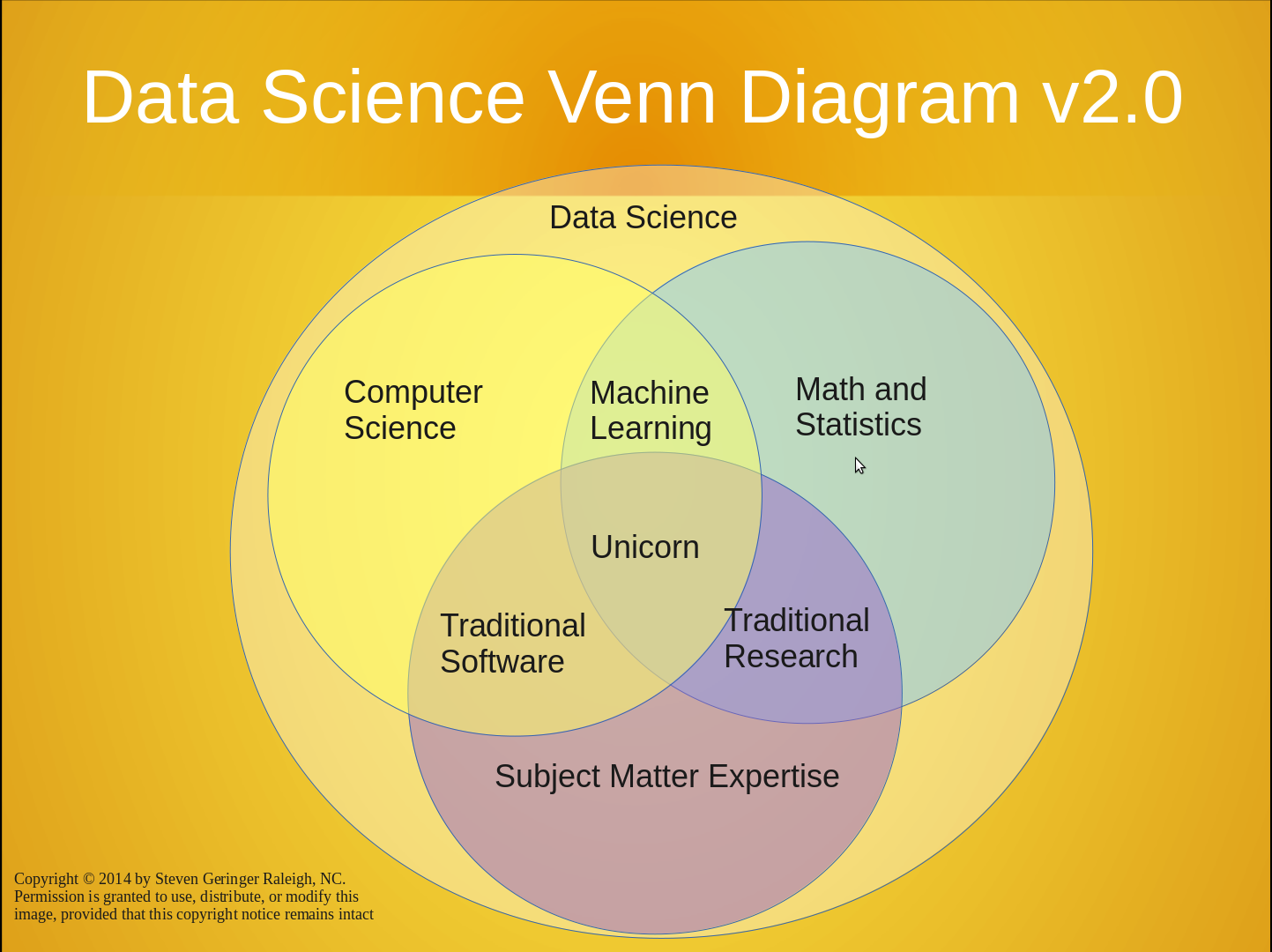
Data Science — это необъятная область, которая включает в себя
много всего. Поэтому, с одной стороны, есть из чего выбрать, но, с другой стороны, надо было подобрать проект, который будет правильно воcпринят публикой, то есть так, чтобы слушатели поняли поставленную задачу, поняли логику решения и при этом могли проникнуться тем, как подход, который я использовал может быть связан с тем, чем они каждый день занимаются на работе.
За несколько месяцев до этого в эту же компанию пытался устроиться мой знакомый индус. Он им рассказывал про одну из своих задач, над которой работал в аспирантуре. И, навскидку, это выглядело хорошо: с одной стороны, это связано с тем, чем он занимается последние несколько лет в университете, то есть он может объяснять детали и нюансы на глубоком уровне, а с другой стороны, результаты его работы были опубликованы в рецензируемом журнале, то есть это вклад в мировую копилку знаний. Но на практике это сработало совсем по-другому. Во-первых, чтобы объяснить, что ты хочешь сделать и почему, надо кучу времени, а у него на всё про всё 20 минут. А во-вторых, его рассказ про то, как какой-то граф при каких-то параметрах разделяется на кластеры, и как это всё похоже на фазовый переход в физике, вызвал законный вопрос: «А зачем это надо нам?». Я не хотел такого же результата, так что я не стал рассказывать про: «Non linear regression as a way to get insight into the region affected by a sign problem in Quantum Monte Carlo simulations in fermionic Hubbard model.»
Я решил рассказать про одно из соревнований на kaggle.com, в котором я участвовал.






 Сегодня я бы хотел рассказать о появившемся в версии 1.2 новом пакете, получившем название spark.ml. Он создан, чтобы обеспечить единый высокоуровневый API для алгоритмов машинного обучения, который поможет упростить создание и настройку, а также объединение нескольких алгоритмов в один конвейер или рабочий процесс. Сейчас на дворе у нас версия 1.4.1, и разработчики заявляют, что пакет вышел из альфы, хотя многие компоненты до сих пор помечены как Experimental или DeveloperApi.
Сегодня я бы хотел рассказать о появившемся в версии 1.2 новом пакете, получившем название spark.ml. Он создан, чтобы обеспечить единый высокоуровневый API для алгоритмов машинного обучения, который поможет упростить создание и настройку, а также объединение нескольких алгоритмов в один конвейер или рабочий процесс. Сейчас на дворе у нас версия 1.4.1, и разработчики заявляют, что пакет вышел из альфы, хотя многие компоненты до сих пор помечены как Experimental или DeveloperApi.
 Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.
Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.


{kind=link}