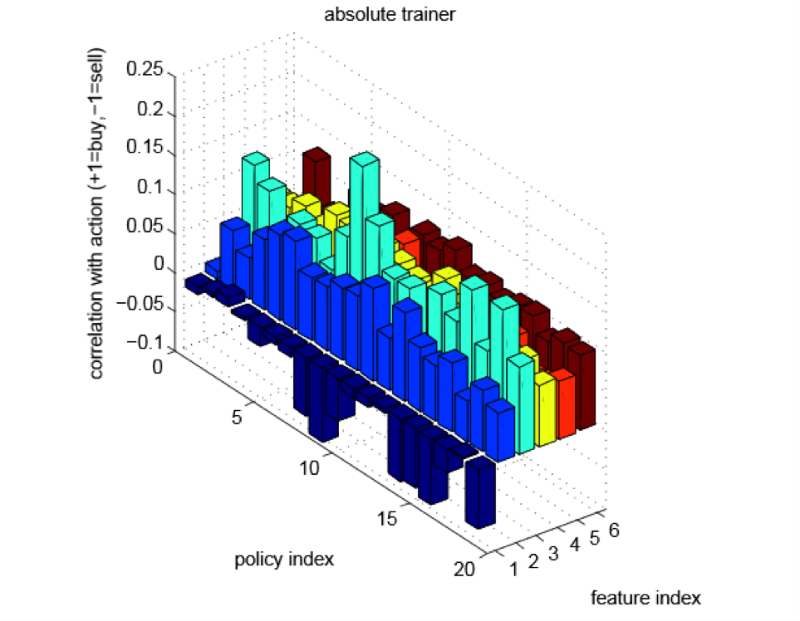
Привет, Хабр! В этой статье речь пойдет о таком не очень приятном аспекте машинного обучения, как оптимизация гиперпараметров. Две недели назад в очень известный и полезный проект Vowpal Wabbit был влит модуль vw-hyperopt.py, умеющий находить хорошие конфигурации гиперпараметров моделей Vowpal Wabbit в пространствах большой размерности. Модуль был разработан внутри DCA (Data-Centric Alliance).

Для поиска хороших конфигураций vw-hyperopt использует алгоритмы из питоновской библиотеки Hyperopt и может оптимизировать гиперпараметры адаптивно с помощью метода Tree-Structured Parzen Estimators (TPE). Это позволяет находить лучшие оптимумы, чем простой grid search, при равном количестве итераций.
Эта статья будет интересна всем, кто имеет дело с Vowpal Wabbit, и особенно тем, кто досадовал на отсутствие в исходном коде способов тюнинга многочисленных ручек моделей, и либо тюнил их вручную, либо кодил оптимизацию самостоятельно.
Для поиска хороших конфигураций vw-hyperopt использует алгоритмы из питоновской библиотеки Hyperopt и может оптимизировать гиперпараметры адаптивно с помощью метода Tree-Structured Parzen Estimators (TPE). Это позволяет находить лучшие оптимумы, чем простой grid search, при равном количестве итераций.
Эта статья будет интересна всем, кто имеет дело с Vowpal Wabbit, и особенно тем, кто досадовал на отсутствие в исходном коде способов тюнинга многочисленных ручек моделей, и либо тюнил их вручную, либо кодил оптимизацию самостоятельно.





 Как вы знаете, ABBYY занимается разработкой технологии анализа естественных языков Compreno. Сейчас система работает на английском и русском языках, и активно используется во многих проектах. Однако изначально сама технология была задумана как многоязычная, поэтому мы много внимания уделяем и «обучению» другим иностранным языкам. И тут можно провести некоторую аналогию с человеком: после изучения одного иностранного языка другие даются легче. В частности, сейчас мы добавляем в технологию немецкий язык и параллельно исследуем возможности рынка – есть ли интерес к этому направлению. Сразу оговоримся – пока речь о продуктах, поддерживающих немецкий, не идёт, мы в самом начале пути.
Как вы знаете, ABBYY занимается разработкой технологии анализа естественных языков Compreno. Сейчас система работает на английском и русском языках, и активно используется во многих проектах. Однако изначально сама технология была задумана как многоязычная, поэтому мы много внимания уделяем и «обучению» другим иностранным языкам. И тут можно провести некоторую аналогию с человеком: после изучения одного иностранного языка другие даются легче. В частности, сейчас мы добавляем в технологию немецкий язык и параллельно исследуем возможности рынка – есть ли интерес к этому направлению. Сразу оговоримся – пока речь о продуктах, поддерживающих немецкий, не идёт, мы в самом начале пути.