
Сейчас очень много статей, рапортующих об успехах нейронных сетей, в частности, в интересующей нас области понимания естественного языка. Но для практической работы важно еще и понимание того, при каких условиях эти алгоритмы не работают, или работают плохо. Отрицательные результаты по понятным причинам часто остаются за рамками публикаций. Часто пишут так — мы использовали метод А вместе с Б и В, и получили результат. А нужен ли был Б и В остается под вопросом. Для разработчика, внедряющего известные методы в практику эти вопросы очень даже важны, поэтому сегодня поговорим об отрицательных результатах и их значении на примерах. Примеры возьмем, как известные, так и из своей практики.
Парадигма ситуационно-ориентированного программирования
5 мин
Как известно, существует три вида алгоритмов: линейные, разветвленные и циклические:
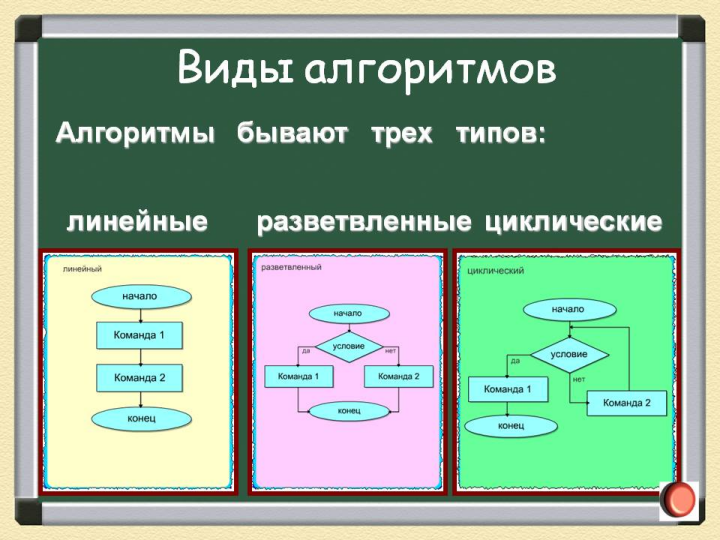
Основой всего, что сделано в методологии программирования, включая и объектное программирование стало структурное программирование, предложенное Эдсгером Дейкстрой в 1970-х годах. Одной из основных идей было введение блочных операторов ветвления (IF, THEN, ELSE) и цикличности (WHILE, FOR, DO, UNTIL и др.) вместо проблемного оператора GOTO, который приводил к получению запутанного, неудобочитаемого «спагетти-кода».
Для использования в интеллектуальных системах структурное программирование обладает серьезным недостатком.
Основой всего, что сделано в методологии программирования, включая и объектное программирование стало структурное программирование, предложенное Эдсгером Дейкстрой в 1970-х годах. Одной из основных идей было введение блочных операторов ветвления (IF, THEN, ELSE) и цикличности (WHILE, FOR, DO, UNTIL и др.) вместо проблемного оператора GOTO, который приводил к получению запутанного, неудобочитаемого «спагетти-кода».
Для использования в интеллектуальных системах структурное программирование обладает серьезным недостатком.
Зaчем мне AshleyMadison, если я не курю?
5 мин
Как вы все уже наверное знаете, недавно были выложены дампы баз AshleyMadison. Я решил не упускать возможность и проанализировать реальные данные дейтинг платформы. Попробуем предсказать платежеспособность клиента по его характиристикам таким как возраст, рост, вес, привычки и т.д.

Попробуем?
Попробуем?
Как найти алгоритм работы интеллекта
4 мин
В нашем блоге мы рассказываем о виртуализации инфраструктуры и соответствующих технологиях. Почерпнуть что-то интересное можно не только из опыта работы с инфраструктурными проектами, но и из теоретических работ, направленных далеко в будущее. Сегодня мы решили взглянуть на книгу Майкла Нилсена, рассуждающего на тему алгоритмизации интеллекта.

IBM собрала из нейроморфных чипов нового типа «мозгоподобную» систему
3 мин

Корпорация IBM работает совместно с DARPA над созданием нейроморфных чипов (Systems of Neuromorphic Adaptive Plastic Scalable Electronics, SyNAPSE) уже много лет, реализация проекта началась еще в 2008 году. Цель — создание чипов и систем, работа которых была бы организована по принципу работы нейронов мозга животных (например, грызунов). Это очень сложная задача, и специалистам пришлось потратить на ее решение немало времени. Сейчас, наконец, представлены первые значительные результаты проекта SyNAPSE.
Система TrueNorth, состоит из отдельных чипов-модулей, которые работают, как нейроны мозга. Соединяя нейроморфные чипы в систему, исследователи получают искусственную нейронную сеть. Версия, которую представила IBM, включает 48 млн соединений — это близко к числу синапсов в мозге крысы. Представленная структура состоит из 48 отдельных чипов-модулей.
Кластеризация графов и поиск сообществ. Часть 2: k-medoids и модификации
11 мин
 Привет, Хабр! В этой части мы опишем вам алгоритм, с помощью которого были получены цвета на графах из первой части. В основе алгоритма лежит k-medoids — довольно простой и прозрачный метод. Он представляет собой вариант популярного k-means, про который наверняка большинство из вас уже имеет представление.
Привет, Хабр! В этой части мы опишем вам алгоритм, с помощью которого были получены цвета на графах из первой части. В основе алгоритма лежит k-medoids — довольно простой и прозрачный метод. Он представляет собой вариант популярного k-means, про который наверняка большинство из вас уже имеет представление. В отличие от k-means, в k-medoids в качестве центроидов может выступать не любая точка, а только какие-то из имеющихся наблюдений. Так как в графе между вершинами расстояние определить можно, k-medoids годится для кластеризации графа. Главная проблема этого метода — необходимость явного задания числа кластеров, то есть это не выделение сообществ (сommunity detection), а оптимальное разбиение на заданное количество частей (graph partitioning).
С этим можно бороться двумя путями:
Новая бесплатная библиотека для аналитики данных Intel® DAAL
5 мин

Сегодня вышел в свет первый официальный релиз новой библиотеки Intel для аналитики данных — Intel Data Analytics Acceleration Library. Библиотека доступна как в составе пакетов Parallel Studio XE, так и как независимый продукт с коммерческой и бесплатной (community) лицензией. Что это за зверь и зачем она нужна? Давайте разбираться.
Кластеризация графов и поиск сообществ. Часть 1: введение, обзор инструментов и Волосяные Шары
10 мин
Привет, Хабр! В нашей работе часто возникает потребность в выделении сообществ (кластеров) разных объектов: пользователей, сайтов, продуктовых страниц интернет-магазинов. Польза от такой информации весьма многогранна – вот лишь несколько областей практического применения качественных кластеров:
С точки зрения машинного обучения получение подобных связанных групп выглядит как типичная задача кластеризации. Однако не всегда нам бывают легко доступны фичи наблюдений, в пространстве которых можно было бы искать кластеры. Контентые или семантические фичи достаточно трудоемки в получении, как и интеграция разных источников данных, откуда эти фичи можно было бы достать. Зато у нас есть DMP под названием Facetz.DCA, где на поверхности лежат факты посещений пользователями страниц. Из них легко получить количество посещений сайтов, как каждого в отдельности, так и совместных посещений для каждой пары сайтов. Этой информации уже достаточно для построения графов веб-доменов или продуктовых страниц. Теперь задачу кластеризации можно сформулировать как задачу выделения сообществ в полученных графах.
- Выделение сегментов пользователей для проведения таргетированных рекламных кампаний.
- Использование кластеров в качестве предикторов («фичей») в персональных рекомендациях (в content-based методах или как дополнительная информация в коллаборативной фильтрации).
- Снижение размерности в любой задаче машинного обучения, где в качестве фичей выступают страницы или домены, посещенные пользователем.
- Сличение товарных URL между различными интернет-магазинами с целью выявления среди них групп, соответствующих одному и тому же товару.
- Компактная визуализация — человеку будет проще воспринимать структуру данных.
С точки зрения машинного обучения получение подобных связанных групп выглядит как типичная задача кластеризации. Однако не всегда нам бывают легко доступны фичи наблюдений, в пространстве которых можно было бы искать кластеры. Контентые или семантические фичи достаточно трудоемки в получении, как и интеграция разных источников данных, откуда эти фичи можно было бы достать. Зато у нас есть DMP под названием Facetz.DCA, где на поверхности лежат факты посещений пользователями страниц. Из них легко получить количество посещений сайтов, как каждого в отдельности, так и совместных посещений для каждой пары сайтов. Этой информации уже достаточно для построения графов веб-доменов или продуктовых страниц. Теперь задачу кластеризации можно сформулировать как задачу выделения сообществ в полученных графах. C# — Моделирование «разумной» жизни на базе нейронных сетей
4 мин
Данная статья посвящена исследованию возможностей нейронных сетей при их использовании в качестве основы для индивидуального разума моделируемого объекта.
Цель: показать, способна ли нейронная сеть (или ее данная реализация) воспринимать «окружающий» мир, самостоятельно обучаться и на основе собственного опыта принимать решения, которые можно считать относительно разумными.
Цель: показать, способна ли нейронная сеть (или ее данная реализация) воспринимать «окружающий» мир, самостоятельно обучаться и на основе собственного опыта принимать решения, которые можно считать относительно разумными.
Аппаратное обеспечение для глубокого обучения
3 мин
Глубокое обучение — процесс, требующий больших вычислительных мощностей. Конечно, нет ничего хорошего в том, чтобы тратить деньги на покупку аппаратного обеспечения с обложки журнала, которое потом полетит на помойку. Нужно подходить к этому делу с умом.
Попробуем взглянуть на примеры аппаратных решений, связанные с работой по осваиванию темы deep learning'а. Ну и затронем немного теории.

Попробуем взглянуть на примеры аппаратных решений, связанные с работой по осваиванию темы deep learning'а. Ну и затронем немного теории.
Как подобрать платье с помощью метода главных компонент
3 мин
Перевод
Итак, кто не против, чтобы одежду ему подбирала программа, машина, нейросеть?
Любой набор изображений возможно проанализировать с помощью метода главных компонент. Этот метод уже довольно успешно применяется при распознавании лиц. Мы же попробуем использовать его на примере женских платьев.
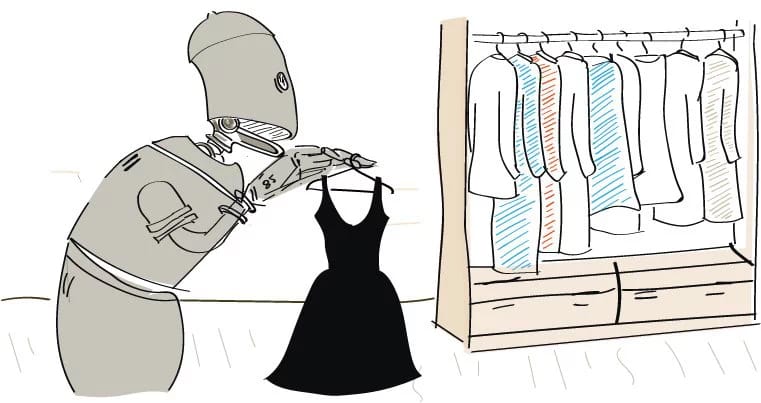
Любой набор изображений возможно проанализировать с помощью метода главных компонент. Этот метод уже довольно успешно применяется при распознавании лиц. Мы же попробуем использовать его на примере женских платьев.
Как легко понять логистическую регрессию
5 мин
Туториал
Перевод
Логистическая регрессия является одним из статистических методов классификации с использованием линейного дискриминанта Фишера. Также она входит в топ часто используемых алгоритмов в науке о данных. В этой статье суть логистической регрессии описана так, что она станет понятна даже людям не очень близким к статистике.

Методы отбора фич
10 мин
Эта статья — обзор, компиляция из нескольких источников, полный список которых я приведу в конце. Отбор фич (feature selection) — важная составляющая машинного обучения. Поэтому мне захотелось лучше разобраться со всевозможными его методами. Я получила большое удовольствие от поиска информации, чтения статей, просмотра лекций. И хочу поделиться этими материалами с вами. Я постаралась написать статью так, чтобы она требовала минимальных знаний в области и была доступна новичкам.
Ближайшие события
Deep Dream: как обучить нейронную сеть мечтать не только о собаках
5 мин
Туториал
Перевод
В июле всех порадовала статья про deep dream или инцепционизм от Google. В статье подробно рассказывалось и показывалось как нейронные сети рисуют картины и зачем их заставили это делать. Вот эта статья на хабре.
Теперь все, у кого настроена среда caffe, кому скучно и у кого есть свободное время могут сделать собственные фотки в стиле инцепционизм. Одна проблема — почти на всех фотках получаются собаки. Как же избавится от элементов с псами в изображениях deep dream и обучить свою нейронную сеть пользоваться другими картинками?

Теперь все, у кого настроена среда caffe, кому скучно и у кого есть свободное время могут сделать собственные фотки в стиле инцепционизм. Одна проблема — почти на всех фотках получаются собаки. Как же избавится от элементов с псами в изображениях deep dream и обучить свою нейронную сеть пользоваться другими картинками?
Kaggle. Предсказание продаж, в зависимости от погодных условий
16 мин

Не далее, как в прошлую пятницу у меня было интервью в одной компании в Palo Alto на позицию Data Scientist и этот многочасовой марафон из технических и не очень вопросов должен был начаться с моей презентации о каком-нибудь проекте, в котором я занимался анализом данных. Продолжительность — 20-30 минут.
Data Science — это необъятная область, которая включает в себя много всего. Поэтому, с одной стороны, есть из чего выбрать, но, с другой стороны, надо было подобрать проект, который будет правильно воcпринят публикой, то есть так, чтобы слушатели поняли поставленную задачу, поняли логику решения и при этом могли проникнуться тем, как подход, который я использовал может быть связан с тем, чем они каждый день занимаются на работе.
{kind=link}
За несколько месяцев до этого в эту же компанию пытался устроиться мой знакомый индус. Он им рассказывал про одну из своих задач, над которой работал в аспирантуре. И, навскидку, это выглядело хорошо: с одной стороны, это связано с тем, чем он занимается последние несколько лет в университете, то есть он может объяснять детали и нюансы на глубоком уровне, а с другой стороны, результаты его работы были опубликованы в рецензируемом журнале, то есть это вклад в мировую копилку знаний. Но на практике это сработало совсем по-другому. Во-первых, чтобы объяснить, что ты хочешь сделать и почему, надо кучу времени, а у него на всё про всё 20 минут. А во-вторых, его рассказ про то, как какой-то граф при каких-то параметрах разделяется на кластеры, и как это всё похоже на фазовый переход в физике, вызвал законный вопрос: «А зачем это надо нам?». Я не хотел такого же результата, так что я не стал рассказывать про: «Non linear regression as a way to get insight into the region affected by a sign problem in Quantum Monte Carlo simulations in fermionic Hubbard model.»
Я решил рассказать про одно из соревнований на kaggle.com, в котором я участвовал.
Распознавание кириллической Яндекс капчи
3 мин
Эта статья продолжает цикл об особенностях, слабых сторонах и непосредственно о распознавании популярных капчей.
В предыдущей публикации мы затронули готовое решение KCAPTCHA, которое несмотря на неплохую защищенность было распознано без сколько-нибудь серьезной предварительной обработки и сегментации, обычным многослойным персептроном.
Теперь на очереди кириллическая Яндекс капча, с которой, уверен, многие из нас отлично знакомы.
Итак, мы имеем такую капчу:

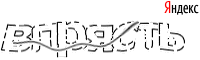
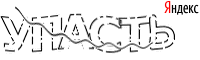
В предыдущей публикации мы затронули готовое решение KCAPTCHA, которое несмотря на неплохую защищенность было распознано без сколько-нибудь серьезной предварительной обработки и сегментации, обычным многослойным персептроном.
Теперь на очереди кириллическая Яндекс капча, с которой, уверен, многие из нас отлично знакомы.
Итак, мы имеем такую капчу:
Покупка оптимальной квартиры с R
12 мин
Многие люди сталкиваются с вопросом покупки или продажи недвижимости, и важный критерий здесь, как бы не купить дороже или не продать дешевле относительно других, сопоставимых вариантов. Простейший способ — сравнительный, ориентироваться на среднюю цену метра в конкретном месте и экспертно добавляя или снижая проценты от стоимости за достоинства и недостатки конкретной квартиры.  Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.
Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.
Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.Работа с текстовыми данными в scikit-learn (перевод документации) — часть 1
6 мин
Данная статья представляет перевод главы, обучающей работе с текстовыми данными, из официальной документации scikit-learn.
Цель этой главы — это исследование некоторых из самых важных инструментов в scikit-learn на одной частной задаче: анализ коллекции текстовых документов (новостные статьи) на 20 различных тематик.
В этой главе мы рассмотрим как:
Цель этой главы — это исследование некоторых из самых важных инструментов в scikit-learn на одной частной задаче: анализ коллекции текстовых документов (новостные статьи) на 20 различных тематик.
В этой главе мы рассмотрим как:
- загрузить содержимое файла и категории
- выделить вектора признаков, подходящих для машинного обучения
- обучить одномерную модель выполнять категоризацию
- использовать стратегию grid search, чтобы найти наилучшую конфигурацию для извлечения признаков и для классификатора
Как Microsoft Project Oxford может сделать ваши приложения умнее
8 мин
Выражаем большое спасибо за подготовку статьи Евгению Григоренко, Microsoft Student Partner, за помощь в написании данной статьи. Остальные наши статьи по теме Azure можно найти по тегу azureweek
Дайте я угадаю, Вы, как и я, уже пару месяцев горите идеей гениального приложения. Помимо своей основной функциональности, в идеальном мире оно просто обязано обладать множеством дополнительных возможностей, например, идентифицировать пользователя (или кота) по его фотографии с фронтальной камеры или понимать команды на естественном языке. Или сделать второй How-Old (который был сделан как раз на Оксфорде).
Но все мы знаем печальную истину. Многое возможно только с пользованием сложных алгоритмов машинного обучения, которых у нас совершенно нет времени изучать. И именно это останавливает от разработки, так как без таких инноваций мы совершенно затеряемся среди аналогов. Но решение этой проблемы есть, и имя ему Microsoft Project Oxford. Если вы хотите узнать, как Microsoft Project Oxford может упростить Вашу жизнь и сделать Ваши приложения по-настоящему интеллектуальными, то добро пожаловать под кат.

Введение в машинное обучение с помощью scikit-learn (перевод документации)
6 мин
Данная статья представляет собой перевод введения в машинное обучение, представленное на официальном сайте scikit-learn.
В этой части мы поговорим о терминах машинного обучения, которые мы используем для работы с scikit-learn, и приведем простой пример обучения.
В общем, задача машинного обучения сводится к получению набора выборок данных и, в последствии, к попыткам предсказать свойства неизвестных данных. Если каждый набор данных — это не одиночное число, а например, многомерная сущность (multi-dimensional entry или multivariate data), то он должен иметь несколько признаков или фич.
Машинное обчение можно разделить на несколько больших категорий:
В этой части мы поговорим о терминах машинного обучения, которые мы используем для работы с scikit-learn, и приведем простой пример обучения.
Машинное обучение: постановка вопроса
В общем, задача машинного обучения сводится к получению набора выборок данных и, в последствии, к попыткам предсказать свойства неизвестных данных. Если каждый набор данных — это не одиночное число, а например, многомерная сущность (multi-dimensional entry или multivariate data), то он должен иметь несколько признаков или фич.
Машинное обчение можно разделить на несколько больших категорий:
- обучение с учителем (или управляемое обучение). Здесь данные представлены вместе с дополнительными признаками, которые мы хотим предсказать. (Нажмите сюда, чтобы перейти к странице Scikit-Learn обучение с учителем). Это может быть любая из следующих задач:
- классификация: выборки данных принадлежат к двум или более классам и мы хотим научиться на уже размеченных данных предсказывать класс неразмеченной выборки. Примером задачи классификации может стать распознавание рукописных чисел, цель которого — присвоить каждому входному набору данных одну из конечного числа дискретных категорий. Другой способ понимания классификации — это понимание ее в качестве дискретной (как противоположность непрерывной) формы управляемого обучения, где у нас есть ограниченное количество категорий, предоставленных для N выборок; и мы пытаемся их пометить правильной категорией или классом.
- регрессионный анализ: если желаемый выходной результат состоит из одного или более непрерывных переменных, тогда мы сталкиваемся с регрессионным анализом. Примером решения такой задачи может служить предсказание длинны лосося как результата функции от его возраста и веса.
- обучение без учителя (или самообучение). В данном случае обучающая выборка состоит из набора входных данных Х без каких-либо соответствующих им значений. Целью подобных задач может быть определение групп схожих элементов внутри данных. Это называется кластеризацией или кластерным анализом. Также задачей может быть установление распределения данных внутри пространства входов, называемое густотой ожидания (density estimation). Или это может быть выделение данных из высоко размерного пространства в двумерное или трехмерное с целью визуализации данных. (Нажмите сюда, чтобы перейти к странице Scikit-Learn обучение без учителя).