I never asked for this. Как понять, на что способен аугментатор текстов
Привет, я Буянов Игорь. Разработчик в команде разметки MTS AI. Сегодня я вам расскажу о способе понять, на что способен ваш аугментатор текста и в каких случаях его лучше использовать.

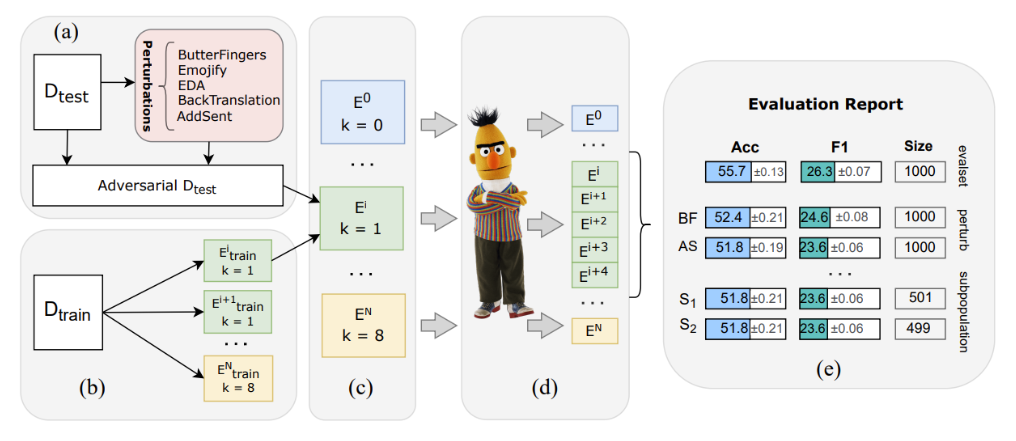
История создания этой методики началась с задачи текстовой генерации, в которой разметчики должны писать тексты под определенный класс. Такой отчаянный способ создания данных, когда их нет совсем. В раздумьях о том, как облегчить труд разметчиков, мне пришла идея:
что если разметчики будут писать не весь объем текстов, а, скажем, только некоторую часть, пусть и большую, а меньшую добивать с помощью аугментаторов. Однако, как убедиться, что тексты, полученные от аугментатора, хотя бы соответствуют тематике класса? Ко всем ли текстам можно применять аугментатор и ожидать, что все будет работать как надо? Другими словами, надо получить характеристику аугментатора, чтобы знать, чего от него можно ожидать.
В этой небольшой заметке я покажу простую и довольно быструю, хоть и ручную, методику оценки текстовых аугментаторов.