Каждый год в Москве проходит конференция "
Диалог", в которой участвуют лингвисты и специалисты по анализу данных. Они обсуждают, что такое естественный язык, как научить машину его понимать и обрабатывать. В рамках конференции традиционно проводятся соревнования (дорожки)
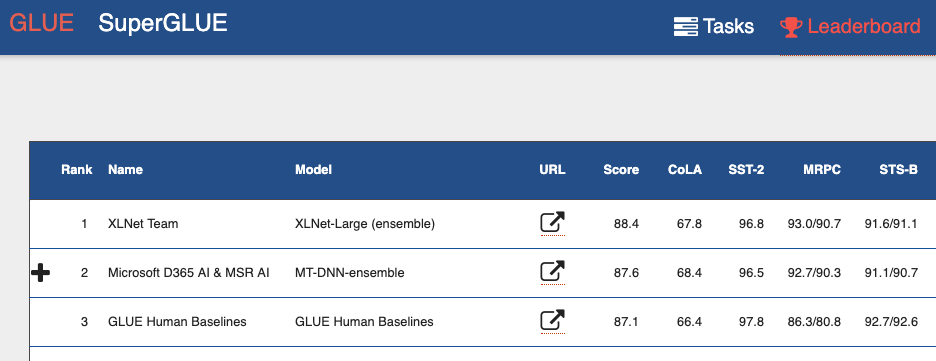
Dialogue Evaluation. В них могут участвовать как представители крупных компаний, создающих решения в области обработки естественного языка (Natural Language Processing, NLP), так и отдельные исследователи. Может показаться, что если ты простой студент, то тебе ли тягаться с системами, которые крупные специалисты больших компаний создают годами. Dialogue Evaluation — это как раз тот случай, когда в итоговой турнирной таблице простой студент может оказаться выше именитой компании.
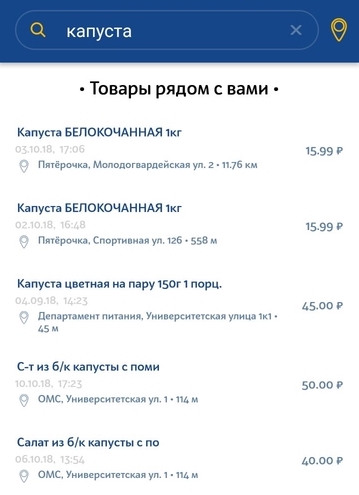
Этот год станет уже 9-ым по счету, когда на «Диалоге» проводится Dialogue Evaluation. Каждый год количество соревнований разное. Темами для дорожек уже становились такие задачи NLP, как анализ тональности (Sentiment Analysis), разрешение лексической многозначности (Word Sense Induction), нахождение опечаток (Automatic Spelling Correction), выделение сущностей (Named Entity Recognition) и другие.

В этом году четыре группы организаторов подготовили такие дорожки:
- Генерация заголовков для новостных статей.
- Разрешение анафоры и кореференции.
- Морфологический анализ на материале малоресурсных языков.
- Автоматический анализ одного из видов эллипсиса (гэппинга).
Сегодня мы расскажем про последнюю из них: что такое эллипсис и зачем учить машину восстанавливать его в тексте, как мы создавали новый корпус, на котором можно решить эту задачу, как проходили сами соревнования и каких результатов смогли добиться участники.


 С 29 мая по 1 июня в Российском государственном гуманитарном университете (РГГУ) пройдет 25-ая международная научная конференция по компьютерной лингвистике и интеллектуальным технологиям «
С 29 мая по 1 июня в Российском государственном гуманитарном университете (РГГУ) пройдет 25-ая международная научная конференция по компьютерной лингвистике и интеллектуальным технологиям «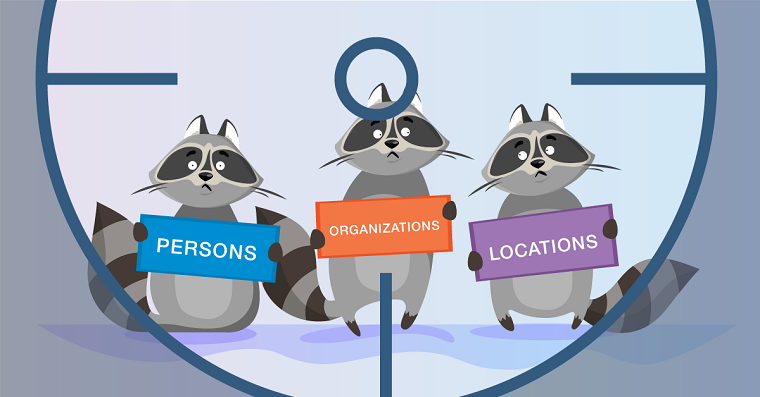








 NLP. Основы. Техники. Саморазвитие. Часть 2: NER
NLP. Основы. Техники. Саморазвитие. Часть 2: NER