
Почему так сложно извлекать текст из PDF?
7 мин
Перевод
Перевод статьи с сайта компании FilingDB, составляющей базу данных из документации европейских компаний
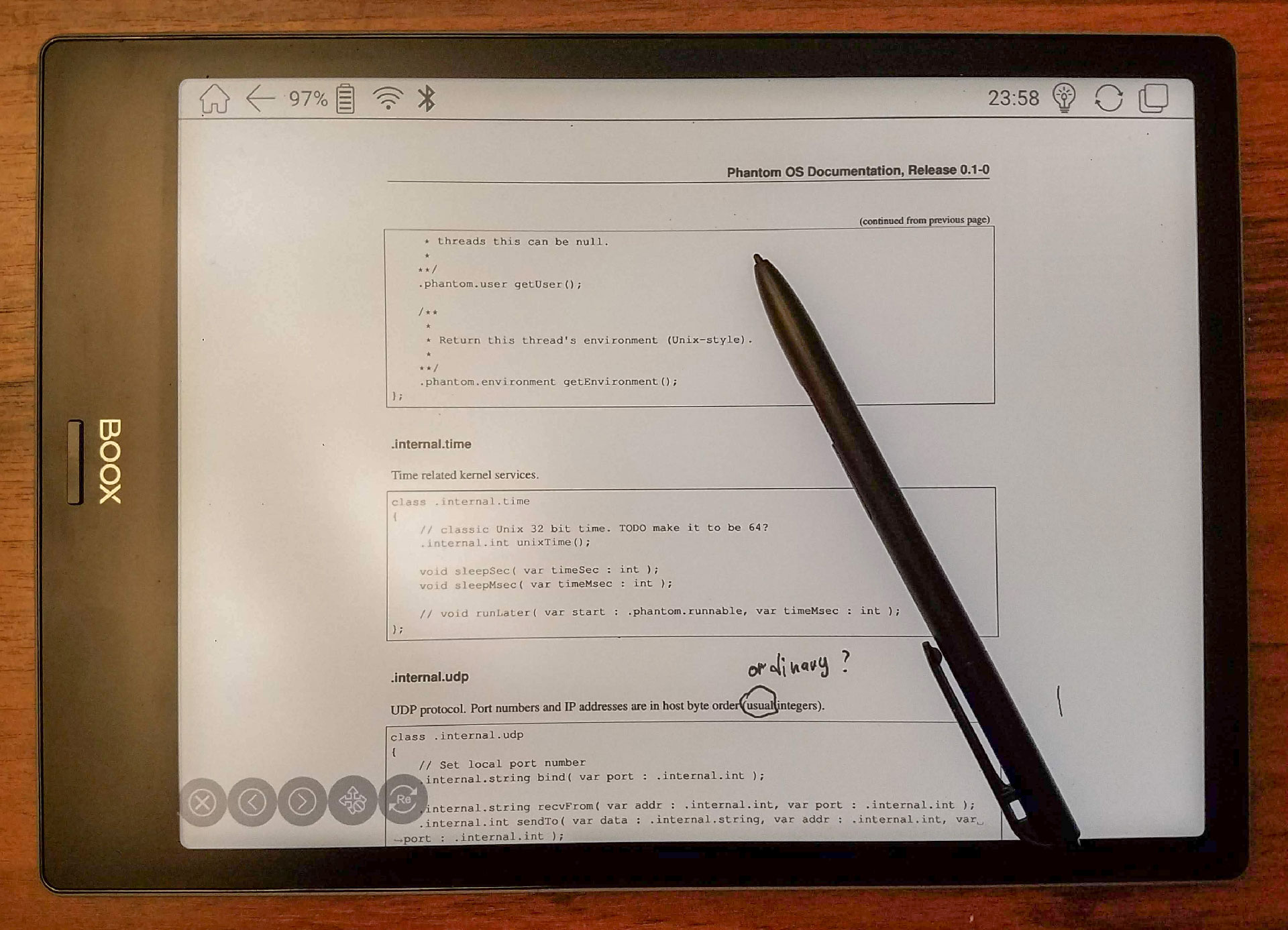
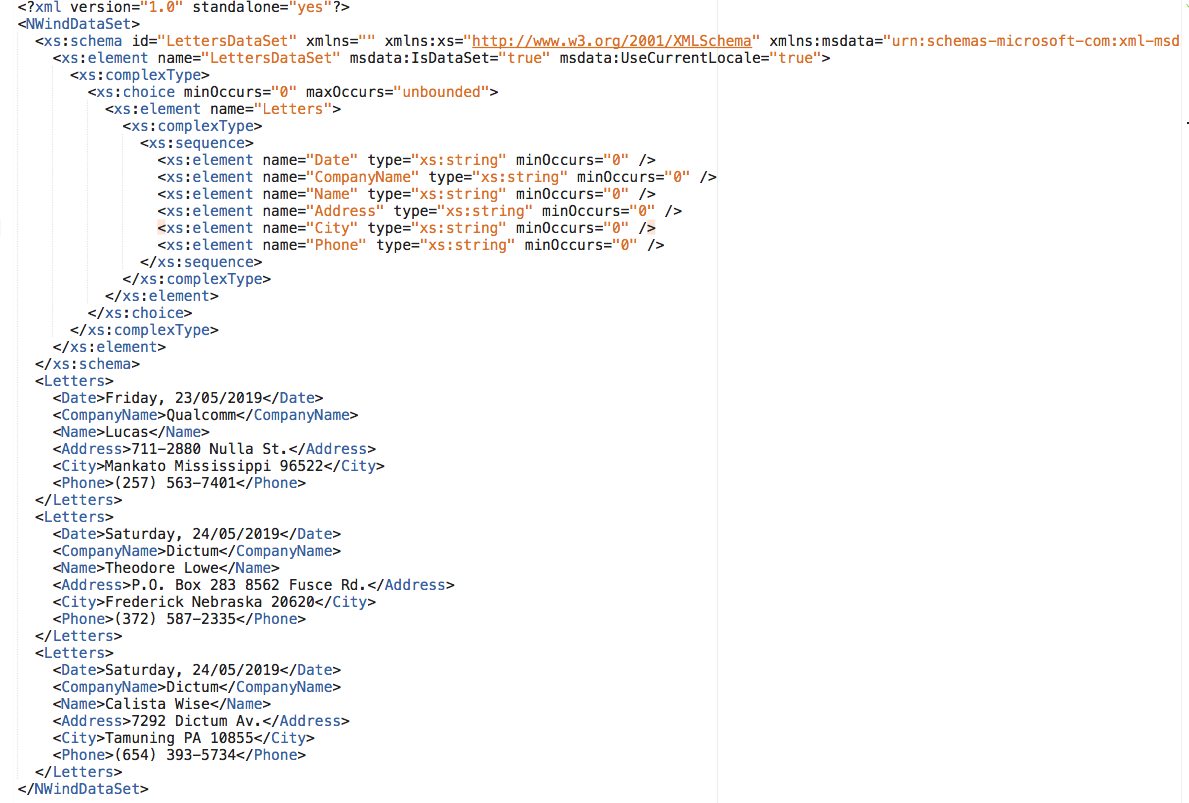
Согласно распространённым представлениям, извлечение текста из PDF не должно быть такой уж сложной задачей. Ведь вот он, текст, прямо у нас перед глазами, и люди постоянно и с большим успехом воспринимают содержимое PDF. Откуда взяться трудностям в автоматическом извлечении текста?
Оказывается, точно так же, как работа с именами людей сложна для алгоритмов из-за множества пограничных случаев и неправильных предположений, так и работа с PDF сложна из-за чрезвычайной гибкости PDF-формата.
Основная проблема в том, что PDF не предполагался как формат для ввода данных – его разрабатывали, как канал вывода, дающий возможность тонкой подстройки вида итогового документа.
Согласно распространённым представлениям, извлечение текста из PDF не должно быть такой уж сложной задачей. Ведь вот он, текст, прямо у нас перед глазами, и люди постоянно и с большим успехом воспринимают содержимое PDF. Откуда взяться трудностям в автоматическом извлечении текста?
Оказывается, точно так же, как работа с именами людей сложна для алгоритмов из-за множества пограничных случаев и неправильных предположений, так и работа с PDF сложна из-за чрезвычайной гибкости PDF-формата.
Основная проблема в том, что PDF не предполагался как формат для ввода данных – его разрабатывали, как канал вывода, дающий возможность тонкой подстройки вида итогового документа.

 Мы регулярно обучаем
Мы регулярно обучаем 











{kind=link}