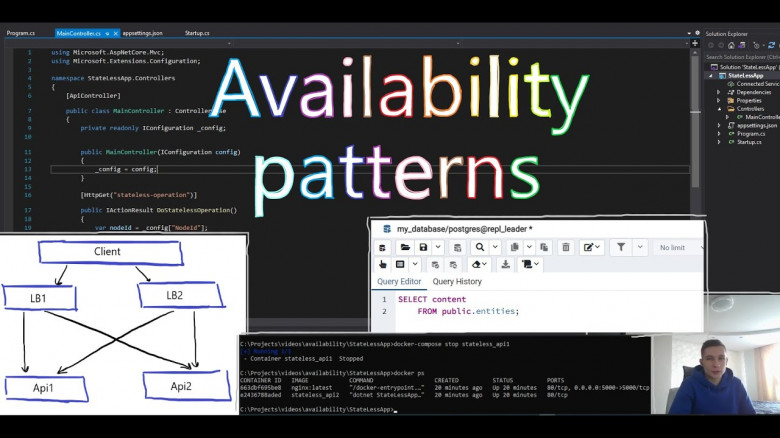
Databaser. Возвращение легкости стартапа
7 мин

Всем привет, меня зовут Александр Даниленко, я – ведущий разработчик отдела «Бюджет-Online». В компании «БАРС Груп» работаю уже 5 лет. За это время нам удалось успешно исправить некоторые сложности процесса разработки. Первая проблема, с который мы столкнулись – развороты больших баз данных (БД) у разработчиков на локальных машинах. Сегодня мы расскажем об инструменте «Databaser», который на 100% позволяет ее решить.