В конце июля 2016 года в корпоративном блоге Uber появилась поистине историческая статья о причинах перехода компании с PostgreSQL на MySQL. С тех пор в жарких обсуждениях этого материала было сломано немало копий, аргументы Uber были тщательно препарированы, компанию обвинили в предвзятости, технической неграмотности, неспособности эффективно взаимодействовать с сообществом и других смертных грехах, при этом по горячим следам в Postgres было внесено несколько изменений, призванных решить некоторые из описанных проблем. Список последствий на этом не заканчивается, и его можно продолжать еще очень долго.
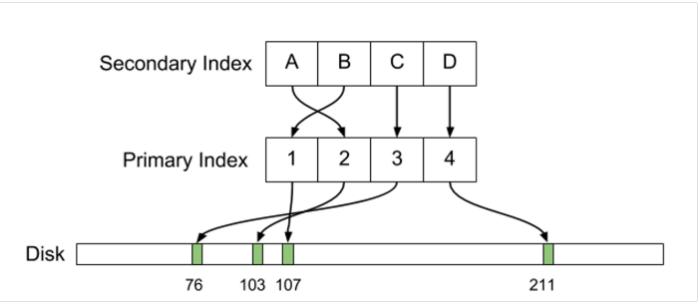
Наверное, не будет преувеличением сказать, что за последние несколько лет это стало одним из самых громких и резонансных событий, связанных с СУБД PostgreSQL, которую мы, к слову сказать, очень любим и широко используем. Эта ситуация наверняка пошла на пользу не только упомянутым системам, но и движению Free and Open Source в целом. При этом, к сожалению, русского перевода статьи так и не появилось. Ввиду значимости события, а также подробного и интересного с технической точки зрения изложения материала, в котором в стиле «Postgres vs MySQL» идет сравнение физической структуры данных на диске, организации первичных и вторичных индексов, репликации, MVCC, обновлений и поддержки большого количества соединений, мы решили восполнить этот пробел и сделать перевод оригинальной статьи. Результат вы можете найти под катом.







 Всё просто. Тут можно найти «Основы разбора запросов для чайников» в случае PostgreSQL и замечательные невыдуманные примеры из продакшена о том, как не надо писать запросы на PostgreSQL и MySQL и что бывает, если их так всё-таки писать.
Всё просто. Тут можно найти «Основы разбора запросов для чайников» в случае PostgreSQL и замечательные невыдуманные примеры из продакшена о том, как не надо писать запросы на PostgreSQL и MySQL и что бывает, если их так всё-таки писать.


