

Хабр, привет! Хочу пригласить всех дата-сайентистов принять участие в опросе об инструментах, которые вы используете в своей работе. Результаты опроса обязательно опубликую в отдельном посте.
Последнее время мне довольно часто стали задавать вопрос о том, насколько безопасно использовать различные готовые расширения, т.е. пакеты, написанные для языка R, есть ли вероятность того, что рекламный аккаунт попадёт в чужие руки
В этой статье я подробно расскажу о том, как устроен механизм авторизации внутри большинства пакетов и API интерфейсов рекламных сервисов, и о том, как использовать приведённые в статье пакеты максимально безопасно.


Есть такой популярный класс задач, в которых требуется проводить достаточно глубокий анализ всего объема цепочек работ, регистрируемых какой-либо информационной системой (ИС). В качестве ИС может быть документооборот, сервис деск, багтрекер, электронный журнал, складской учет и пр. Нюансы проявляются в моделях данных, API, объемах данных и иных аспектах, но принципы решения таких задач примерно одинаковы. И грабли, на которые можно наступить, тоже во многом похожи.
Для решения подобного класса задач R подходит как нельзя лучше. Но, чтобы не разводить разочарованно руками, что R может и хорош, но о-о-очень медленный, важно обращать внимание на производительность выбираемых методов обработки данных.
Является продолжением предыдущих публикаций.

Среди социальных сетей Твиттер более других подходит для добычи текстовых данных в силу жесткого ограничения на длину сообщения, в которое пользователи вынуждены поместить все самое существенное.
Предлагаю угадать, какую технологию обрамляет это облако слов?
Используя Твиттер API можно извлекать и анализировать самую разнообразную информацию. Статья о том, как это осуществить с помощью языка программирования R.
Всем привет, если вы занимаетесь интернет маркетингом наверняка вам ежедневно приходится сталкиваться со множеством рекламных сервисов и как минимум одной платформой веб аналитики, если вам требуется хотя бы раз в месяц, или может быть даже раз в неделю руками сводить данные о расходах, и прочую статистическую информацию из всех источников то это чревато не только большими временными затратами, но и вероятность ошибки при консолидации данных из множества источников в ручном режиме достаточно велика. В этой статье я подскажу готовые расширения (пакеты) для языка R, с помощью которых вы можете автоматизировать процесс сбора данных из большинства популярных рекламных систем и платформ веб аналитики.


 Глубокое обучение — Deep learning — это набор алгоритмов машинного обучения, которые моделируют высокоуровневые абстракции в данных, используя архитектуры, состоящие из множества нелинейных преобразований. Согласитесь, эта фраза звучит угрожающе. Но всё не так страшно, если о глубоком обучении рассказывает Франсуа Шолле, который создал Keras — самую мощную библиотеку для работы с нейронными сетями. Познакомьтесь с глубоким обучением на практических примерах из самых разнообразных областей. Книга делится на две части, в первой даны теоретические основы, вторая посвящена решению конкретных задач. Это позволит вам не только разобраться в основах DL, но и научиться использовать новые возможности на практике. Эта книга написана для людей с опытом программирования на R, желающих быстро познакомиться с глубоким обучением на практике, и является переложением бестселлера Франсуа Шолле «Глубокое обучение на Python», но использующим примеры на базе интерфейса R для Keras.
Глубокое обучение — Deep learning — это набор алгоритмов машинного обучения, которые моделируют высокоуровневые абстракции в данных, используя архитектуры, состоящие из множества нелинейных преобразований. Согласитесь, эта фраза звучит угрожающе. Но всё не так страшно, если о глубоком обучении рассказывает Франсуа Шолле, который создал Keras — самую мощную библиотеку для работы с нейронными сетями. Познакомьтесь с глубоким обучением на практических примерах из самых разнообразных областей. Книга делится на две части, в первой даны теоретические основы, вторая посвящена решению конкретных задач. Это позволит вам не только разобраться в основах DL, но и научиться использовать новые возможности на практике. Эта книга написана для людей с опытом программирования на R, желающих быстро познакомиться с глубоким обучением на практике, и является переложением бестселлера Франсуа Шолле «Глубокое обучение на Python», но использующим примеры на базе интерфейса R для Keras. 
Каждая уважающая себя контора регулярно проводит мониторинг заработных плат, чтобы ориентироваться в интересующем ее сегменте рынка труда. Однако несмотря на то, что задача нужная и важная, не все готовы за это платить сторонним сервисам.
В этом случае, чтобы избавить HR от необходимости регулярно перебирать вручную сотни вакансий и резюме, эффективнее один раз написать небольшое приложение, которое будет делать это самостоятельно, а на выходе предоставлять результат в виде красивого дашборда с таблицами, графиками, возможностью фильтрации и выгрузки данных. Например, такого:
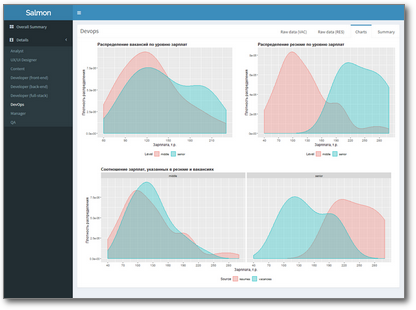
Посмотреть вживую (и даже понажимать кнопки) можно здесь.
В этой статье я расскажу о том, как писала такое приложение, и с какими подводными камнями столкнулась по пути.

В свежем номере журнала The Lancet опубликована моя статья — любопытная карта и небольшое к ней пояснение. Решил рассказать об этом на Хабре, поскольку есть надежда, что реализованный способ визуализации данных может пригодиться еще кому-то.
Kashnitsky, I., & Schöley, J. (2018). Regional population structures at a glance. The Lancet, 392(10143), 209–210. https://doi.org/10.1016/S0140-6736(18)31194-2
Собственно, вот карта в высоком разрешении (кликабельно).
Карту можно воспроизвести точь-в-точь за несколько минут, код на гитхабе.
На протяжении многих лет я слежу за снукером, как за спортом. В нем есть всё: гипнотизирующая красота интеллектуальной игры, элегантность ударов киём и психологическая напряжённость соревнования. Но есть одна вещь, которая мне не нравится — его рейтинговая система.
Её основной недостаток заключается в том, что она учитывает только факт турнирного достижения без учёта "сложности" матчей. Такого недостатка лишена модель Эло, которая следит за "силой" игроков и обновляет её в зависимости от результатов матчей и "силы" соперника. Однако, и она подходит не идеально: считается, что все матчи проходят в равных условиях, а в снукере они играются до определённого количества выигранных фреймов (партий). Для учёта этого факта, я рассмотрел другую модель, которую назвал ЭлоБета.
В данной статье изучается качество моделей Эло и ЭлоБета на результатах снукерных матчей. Важно отметить, что основными целями являются оценка "силы" игроков и создание "справедливого" рейтинга, а не построение прогностических моделей для получения выгоды.

Комментарии в последней публикации «Насколько open-source экосистема R хороша для решения бизнес-задач?» насчет выгрузок в Excel привели к мысли, что имеет смысл потратить время и описать один из апробированных возможных подходов, который можно реализовать не выходя из R.
Ситуация достаточно типична. В компании всегда есть N методик по которым менеджеры вручную стараются строить в Excel отчеты. Даже если их и втоматизировать всегда остается ситуация, когда нужно срочно сделать какой-то новый произвольный срез или сделать представление для какого-либо руководителя в специфическом виде.
А еще есть ряд вручную поддерживаемых словарей в формате excel, чтобы преобразовывать представление данных в отчетах и выборках в правильной терминологии.
В силу того, что никакого подходящего инструмента (масса доп. нюансов будет ниже) так и не удалось найти, пришлось сваять «универсальный конструктор» на Shiny+R. В силу универсальности и параметризуемости настроек, такой конструктор можно легко сажать почти на любую систему в любой предметной области.
Является продолжением предыдущих публикаций.
Поводом для публикации послужила запись в блоге Rstudio: «Shiny 1.1.0: Scaling Shiny with async», которая может очень легко пройти мимо, но которая добавляет очень весомый кирпичик в задаче применения R для задач бизнеса. На самом деле, в dev версии shiny асинхронность появилась примерно год назад, но это было как бы несерьезно и «понарошку» — это же dev версия. Перенос в основную ветку и публикация на CRAN является важным подтверждением, что многие принципиальные вопросы продуманы, решены и протестированы, можно спокойно переносить в продуктив и пользоваться.
А что еще есть в R, кроме «бриллианта», что позволяет превратить его в универсальный аналитический инструмент для практических задач?
Является продолжением предыдущих публикаций.

Тем, кто работает с R, хорошо известно, что изначально язык разрабатывался как инструмент для интерактивной работы. Естественно, что методы удобные для консольного пошагового применения человеком, который глубоко в теме, оказываются малопригодными для создания приложения для конечного пользователя. Возможность получить развернутую диагностику сразу по факту ошибки, проглядеть все переменные и трейсы, выполнить вручную элементы кода (возможно, частично изменив переменные) — все это будет недоступно при автономной работе R приложения в enterprise среде. (говорим R, подразумеваем, в основном, Shiny web приложения).
Однако, не все так плохо. Среда R (пакеты и подходы) настолько сильно эволюционировали, что ряд весьма нехитрых трюков позволяет элегантно решать задачу обеспечения стабильности и надежности работы пользовательских приложений. Ряд из них будет описан ниже.
Является продолжением предыдущих публикаций.
"Исследование рынка вакансий аналитиков" — так звучала вполне реальная задача одного вполне реального ведущего аналитика одной ни большой, ни маленькой фирмы. Рисерчер парсил десятки описаний вакансий с hh вручную, раскидывая их по запрашиваемым скиллам и увеличивая счетчик в соответствующей колонке спредшита.
Я увидела в этой задаче неплохое поле для автоматизации и решила попытаться справиться с ней меньшей кровью, легко и просто.
Меня интересовали следующие вопросы, затронутые в данном исследовании:
Спойлер: легко и просто не получилось.