Я один из многих юристов, который больше года назад участвовал в подготовке обращения в ФАС с вопросом, нормально ли, что Яндекс стал лучшим поиском по сервисам Яндекса. Собственно, ответ пришёл несколько недель назад в виде «
предупреждения о прекращении действий (бездействия), которые содержат признаки нарушения антимонопольного законодательства».
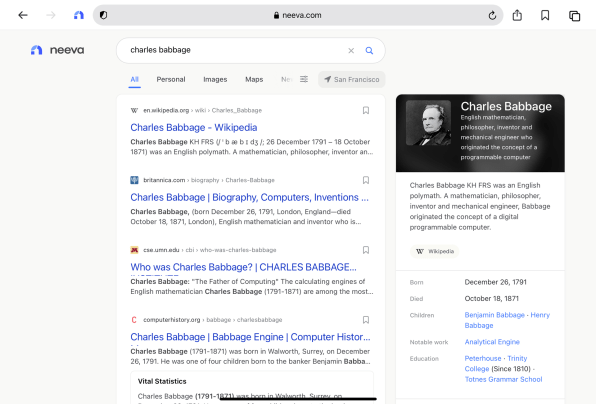
Вопрос был в том, правильно ли то, что Яндекс даёт преференции своим сервисам в поиске. Суть вопроса сводилась к тому, можно ли считать отдельным рынком рынок поиска.
Дело вот в чём: если юридически поиск в интернете — это рынок, то на нём действует антимонопольное законодательство. И тогда, цитируя сам Яндекс (точнее,
пост об иске против Google):
«это обращение — признание одного неприятного факта. У нас с вами есть все шансы попасть в страну, где только одна компания будет решать, какими сервисами будут пользоваться люди». И если
«мы всегда верили в конкуренцию и право выбора пользователя», то ФАС должна восстановить справедливость.
Если же поиск в интернете — это не отдельный рынок, то Яндекс — частная компания, которая в своём поиске может делать что хочет. Ведь это их поиск, их алгоритмы ранжирования и их ручные настройки. Частное дело частной компании.
Коротко: ФАС усмотрела признаки нарушений (пока де-юре не сами нарушения, это важно) в действиях Яндекса. И попросила, по сути, вернуть нейтральность в поиск, то есть обеспечить чуть более равные условия всем компаниям на рынке. В перспективе это может коснуться не только Яндекса, но и любого поиска в России.
Предупреждение ФАС это, по сути, предложение: «сделайте вот так, пожалуйста, или мы возбудим дело», поэтому давайте детально разберёмся, что же происходит.
В предупреждении обозначено, что рынок поиска есть, и это крайне важно для Рунета. Давайте посмотрим, почему.