
Привет! Рассказываем о том, что мы сделали в DataGrip за четыре месяца. Если вы используете поддержку баз данных в других наших IDE, этот пост для вас тоже.

Сбор, хранение, преобразование и презентация данных — основные задачи, стоящие перед инженерами данных (англ. data engineer). Отдел Business Intelligence Badoo в сутки принимает и обрабатывает больше 20 млрд событий, отправляемых с пользовательских устройств, или 2 Тб входящих данных.
Исследование и интерпретация всех этих данных — не всегда тривиальные задачи, иногда возникает необходимость выйти за рамки возможностей готовых баз данных. И если вы набрались смелости и решили делать что-то новое, то следует сначала ознакомиться с принципами работы существующих решений.
Словом, любопытствующим и сильным духом разработчикам и адресована эта статья. В ней вы найдёте описание традиционной модели исполнения запросов в реляционных базах данных на примере демонстрационного языка PigletQL.


Фреймворки становятся лучше, языки немного умнее, но в основном мы делаем то же самое.В данной статье будет рассказано о языке, построенном на подходе, принципиально отличающемся от подходов, используемых во всех существующих языках, в том числе вышеперечисленных. По большому счету, этот язык можно считать языком общего назначения, хотя некоторые его возможности и текущая реализация платформы, построенной на нем, все же, наверное, ограничивают его применение немного более узкой областью – разработкой информационных систем.
Читайте и другие серии.
Индексы:
- Механизм индексирования;
- Интерфейс метода доступа, классы и семейства операторов;
- Hash;
- B-tree;
- GiST;
- SP-GiST;
- GIN;
- RUM;
- BRIN;
- Bloom.
Изоляция и многоверсионность:
- Изоляция, как ее понимают стандарт и PostgreSQL;
- Слои, файлы, страницы — что творится на физическом уровне;
- Версии строк, виртуальные и вложенные транзакции;
- Снимки данных и видимость версий строк, горизонт событий;
- Внутристраничная очистка и HOT-обновления;
- Обычная очистка (vacuum);
- Автоматическая очистка (autovacuum);
- Переполнение счетчика транзакций и заморозка.
Блокировки:
- Блокировки отношений;
- Блокировки строк;
- Блокировки других объектов и предикатные блокировки;
- Блокировки в оперативной памяти.
=> SELECT version();
version
------------------------------------------------------------------------------------------------------------------
PostgreSQL 12beta1 on i686-pc-linux-gnu, compiled by gcc (Ubuntu 5.4.0-6ubuntu1~16.04.10) 5.4.0 20160609, 32-bit
(1 row)Многие из вас читали предыдущую статью про то, как неправильная визуализация для объяснения работы JOIN-ов в некоторых случаях может запутать. Круги Венна не могут полноценно проиллюстрировать некоторые моменты, например, если значения в таблице повторяются.
При подготовке к записи шестого выпуска подкаста "Цинковый прод" (где мы договорились обсудить статью) кажется удалось нащупать один интересный вариант визуализации. Кроме того, в комментариях к изначальной статье тоже предлагали похожий вариант.
Все желающие приглашаются под кат

Так получилось, что я провожу довольно много собеседований на должность веб-программиста. Один из обязательных вопросов, который я задаю — это чем отличается INNER JOIN от LEFT JOIN.
Чаще всего ответ примерно такой: "inner join — это как бы пересечение множеств, т.е. остается только то, что есть в обеих таблицах, а left join — это когда левая таблица остается без изменений, а от правой добавляется пересечение множеств. Для всех остальных строк добавляется null". Еще, бывает, рисуют пересекающиеся круги.
Я так устал от этих ответов с пересечениями множеств и кругов, что даже перестал поправлять людей.
Дело в том, что этот ответ в общем случае неверен. Ну или, как минимум, не точен.
WITH w AS NOT MATERIALIZED (
SELECT *
FROM very_very_big_table
)
SELECT *
FROM w AS w1
JOIN w AS w2
ON w1.key = w2.ref
WHERE w2.key = 123;Сегодня в репозиторий PostgreSQL упал комит, позволяющий управлять поведением обработки подзапросов CTE, а именно: теперь можно явно указывать, будет ли подзапрос материализовываться отдельно или же выполняться как часть одного большого запроса.
Это войдет в PostgreSQL 12, и это big deal. Давайте рассмотрим, почему
TL;DR: GitHub://PastorGL/AQLSelectEx.
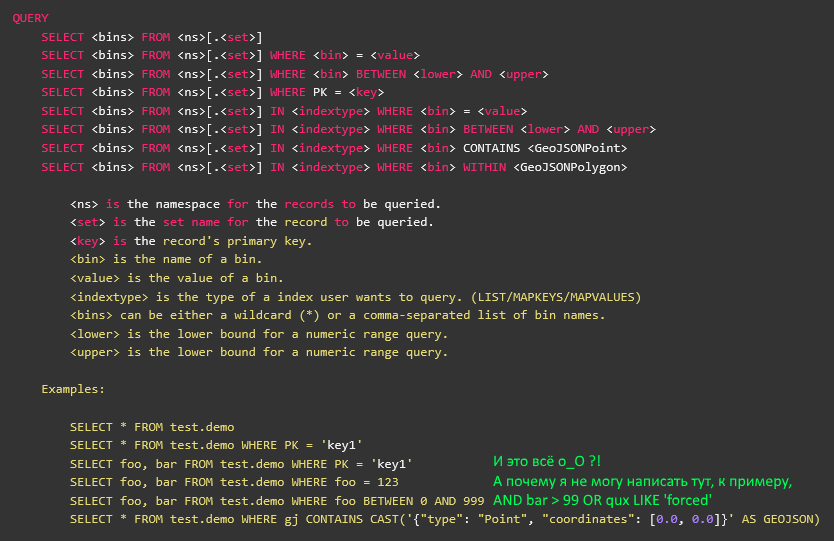
Однажды, ещё не в студёную, но уже зимнюю пору, а конкретно пару месяцев назад, для проекта, над которым я работаю (нечто Geospatial на основе Big Data), потребовалось быстрое NoSQL / Key-Value хранилище.
Терабайты исходников мы вполне успешно прожёвываем при помощи Apache Spark, но схлопнутый до смешного объёма (всего лишь миллионы записей) конечный результат расчётов надо где-то хранить. И очень желательно хранить таким образом, чтобы его можно было по ассоциированным с каждой строкой результата (это одна цифра) метаданным (а вот их довольно много) быстро найти и отдать наружу.