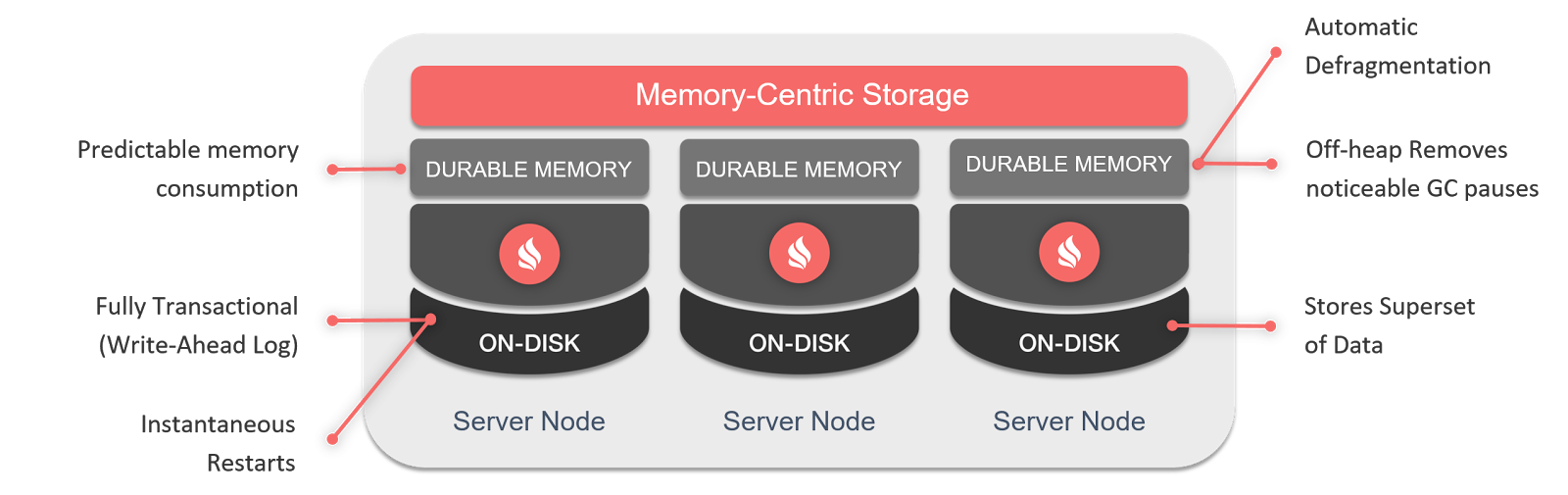
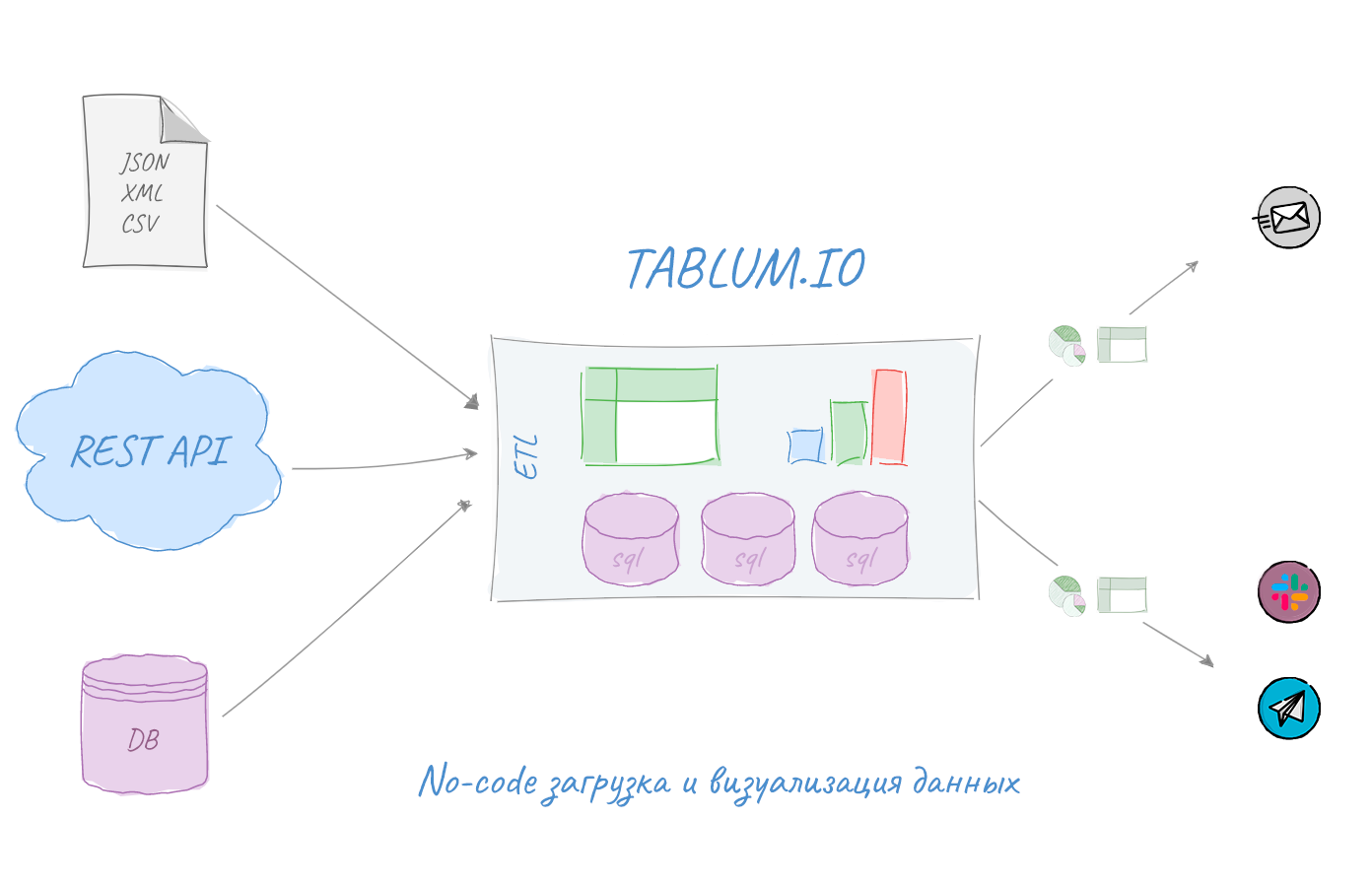
В этой статье я расскажу вам о том, как всерьез задумался об альтернативе Oracle. А как же Postgre, скажете вы? Да, но есть нюансы. Сперва разберемся с вопросом «Почему Oracle?».
Бизнес логика у нас в БД. В книге Oracle для профессионалов Том Кайт пишет
Oracle стоит дорого. Купить его и не использовать все, что в нем есть, будет ошибкой.
И еще, всегда есть фактор команды и компетенций. Если у вас команда десять лет разрабатывает все в Oracle, переучиваться на Postgre может быть болезненно.
Oracle стоит дорого. Настолько дорого, что об этом можно написать несколько раз, и не задумываться о необходимости Oracle в новом проекте будет ошибкой.
Уже несколько раз мне попадались публикации про корейский продукт Tibero, якобы создаваемый для замены Oracle. А нынче у них аттракцион невиданной щедрости — лицензии на Standard раздают для разработчиков практически бесплатно, за доллар на сокет. Итак, разбираемся: что на данный момент могут предложить корейцы. С автомобилями ведь у них, уже (почти) получилось!
Бизнес логика у нас в БД. В книге Oracle для профессионалов Том Кайт пишет
При разработке приложений баз данных я использую очень простую мантру:и в проектировании систем я следую этому правилу. Особенно радуют объектные типы в Oracle, с их помощью сложная бизнес логика красиво и удобно реализуется по всем канонам ООП.
если можно, сделай это с помощью одного оператора SQL;
если это нельзя сделать с помощью одного оператора SQL, сделай это в PL/SQL;
если это нельзя сделать в PL/SQL, попытайся использовать хранимую процедуру на языке Java;
если это нельзя сделать в Java, сделай это в виде внешней процедуры на языке C;
если это нельзя реализовать в виде внешней процедуры на языке C, надо серьезно подумать, зачем это вообще делать...
Oracle стоит дорого. Купить его и не использовать все, что в нем есть, будет ошибкой.
И еще, всегда есть фактор команды и компетенций. Если у вас команда десять лет разрабатывает все в Oracle, переучиваться на Postgre может быть болезненно.
Oracle стоит дорого. Настолько дорого, что об этом можно написать несколько раз, и не задумываться о необходимости Oracle в новом проекте будет ошибкой.
Уже несколько раз мне попадались публикации про корейский продукт Tibero, якобы создаваемый для замены Oracle. А нынче у них аттракцион невиданной щедрости — лицензии на Standard раздают для разработчиков практически бесплатно, за доллар на сокет. Итак, разбираемся: что на данный момент могут предложить корейцы. С автомобилями ведь у них, уже (почти) получилось!