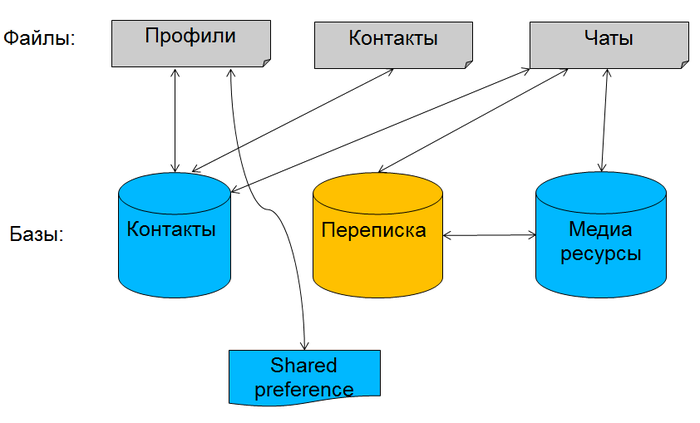
Web 2.0 победоносно шагает по виртуальному миру. Социальные сети растут как грибы после дождя. Теперь в одном месте вы можете хранить свои фото, видеозаписи, писать блоги и слушать музыку. Все это можно комментировать, класть в избранное, копировать… Возможностей много, контент социальных сетей разнородный и разнообразный, и в этом их преимущество.
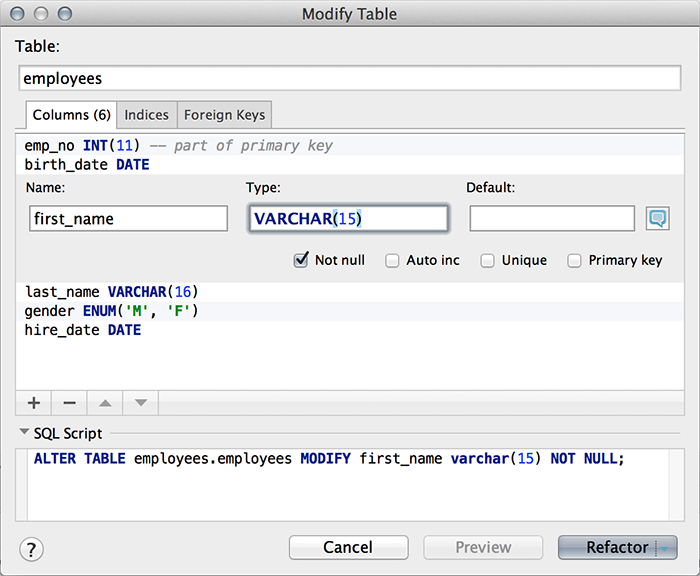
А теперь представьте себе структуру БД какого нибудь «Вконтакте». Представили? И что вы видите? Множество таблиц с данными? А что еще? Множество таблиц для связей много-ко-многим! Необходимых, с точки зрения реляционной БД, но лишних с точки зрения логики. Но это еще не все. Среди полей таблиц мы видим огромное количество «лишних» полей, являющихся всего лишь внешними ключами, служащими для связей один-ко-много, так же необходимых с точки зрения реляционной теории, но абсолютно бесполезных с точки зрения логики.
А теперь представьте себе структуру БД какого нибудь «Вконтакте». Представили? И что вы видите? Множество таблиц с данными? А что еще? Множество таблиц для связей много-ко-многим! Необходимых, с точки зрения реляционной БД, но лишних с точки зрения логики. Но это еще не все. Среди полей таблиц мы видим огромное количество «лишних» полей, являющихся всего лишь внешними ключами, служащими для связей один-ко-много, так же необходимых с точки зрения реляционной теории, но абсолютно бесполезных с точки зрения логики.








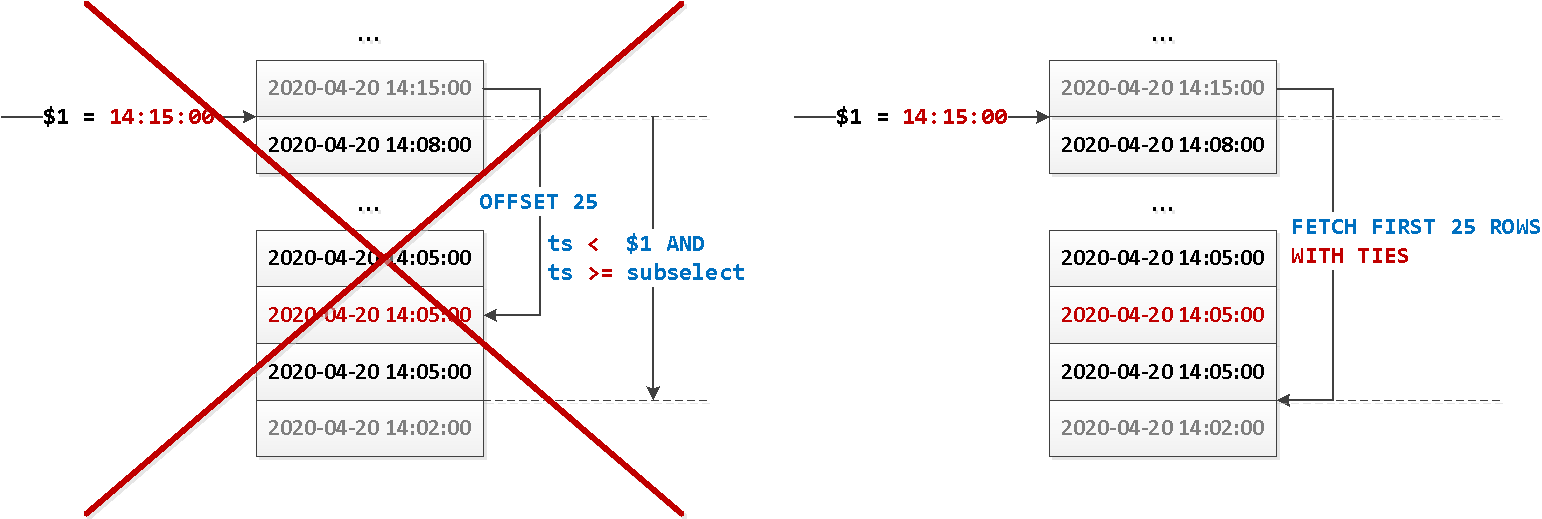
 В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.