

MySQL на сегодняшний день является одной из наиболее распространенных в мире. Достаточно сказать, что по рейтингам 2021 года данная СУБД лишь немного уступала Oracle.
MySQL на сегодняшний день является одной из наиболее распространенных в мире. Достаточно сказать, что по рейтингам 2021 года данная СУБД лишь немного уступала Oracle.

Оператор Join позволяет коррелировать, обогащать и фильтровать два входных набора (пакета / блока) данных (Datasets).Обычно два входных набора данных классифицируются как левый и правый на основе их расположения по отношению к пункту/оператору Join.По сути, соединение работает на основе условного оператора, который включает логическое выражение, основанное на сравнении между левым ключом, полученным из записи левого блока данных, и правым ключом, полученным из записи правого комплекса данных. Левый и правый ключи обычно называются соединительными ключами (Join Keys). Логическое выражение оценивается для каждой пары записей из двух входных наборов данных. На основе логического вывода, полученного в результате оценки выражения, условный оператор включает условие выбора — для отбора либо одной из записей (из пары), либо комбинированной записи (из записей, образующих пару).
Завершив в недавнем прошлом очередную доработку своей легковесной технологии SQL-файл, применяемой для эффективной трансляции файлового SQL-кода в базу данных, автор данной статьи решил в очередной раз представить (в этой заметке теперь, на популярном ресурсе) свои реализованные, хотя бы отчасти, идеи касательно программирования MSSQL, а также некоторые соображения относительно применения SQL вообще. Автор полагает, что несмотря на форму предлагаемой им частной реализации SQL-файл (для MSSQL), лежащая в основе подхода концепция имеет определённую силу и смысл.
Выше на картинке: SQL-трансляция исходных файлов из нескольких директорий (скрипты *.sql), запуск fill_with_data.cmd
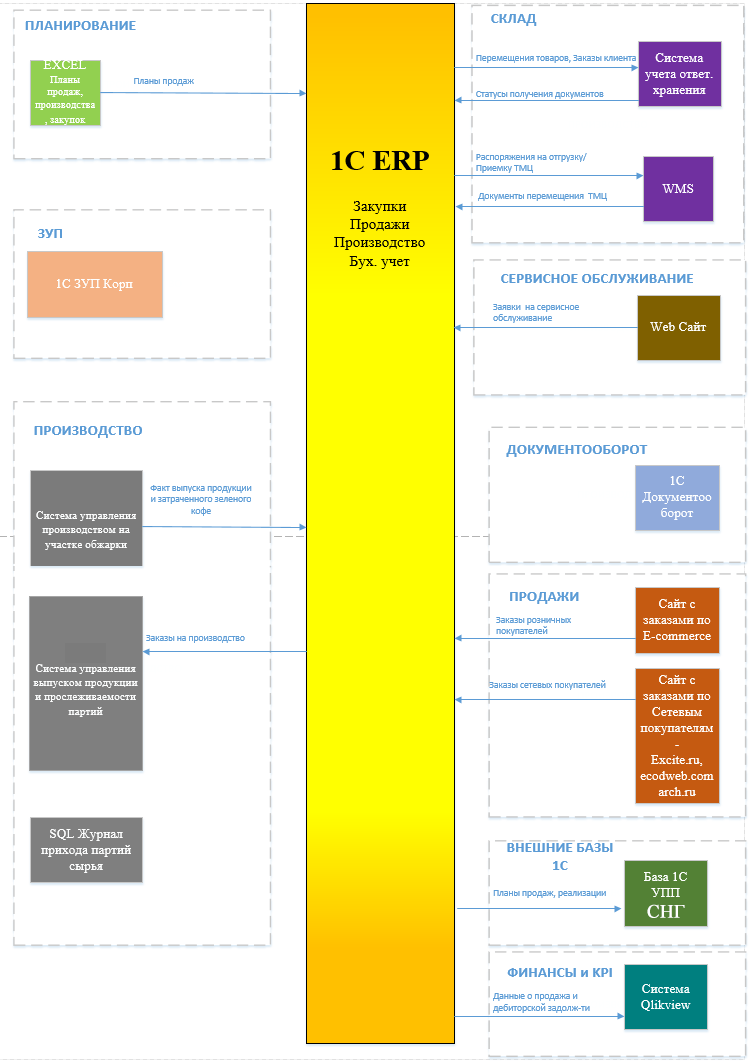
Для тех, кто не читал предыдущую статью, расскажу о сути проекта. В 2020-2021 году я участвовал в роли руководителя команды разработчиков Внедренческого центра "Раздолье" в проекте Управление продажами в международной компании на базе "1С:ERP" (ссылка на сайт 1c.ru). Проект был выбран победителем международного конкурса «1С:Проекта года» в номинации «Лучший проект с использованием технологии "Дистанционное внедрение"».
Суть проекта заключалась в переводе Заказчика с 1С:УПП на 1С:ERP. На его примере кратко опишу, какой была организационная структура и какие программы мы использовали при взаимодействии в команде и с пользователями.
Практически весь проект выполнялся удалённо. Многие сотрудники Заказчика, участвующие в проекте, в условиях карантинов и локдаунов были переведены на удалённую работу. Многие сотрудники нашей компании тоже работали удалённо, с командировками в этот период были большие проблемы. Сам Заказчик работает в режиме 24х7 и является одним из крупнейших предприятий в России по производству кофе. На начало проекта в качестве основы корпоративной системы у Заказчика была программа 1С:УПП редакции 1.2 (даже не 1.3). По завершению проекта в 2021-м перешли на ERP 2.5. К слову, когда начинали работу, в 2020-м году, когда 2.5. была ещё в бета-версии, но мы решили прислушаться к рекомендациям "Фирмы 1С" запускать новые проекты на ней, а не на 1С:ERP 2.4.

Добрый день, уважаемые читатели! Не открою для большинства секрета, если скажу, что большая часть задач в материалах к учебным курсам сформулирована шаблонно. Какие-то вопросы в принципе могут представлять интерес, но очень оторваны от реальных потребностей бизнеса. Какие-то моменты выдернуты из книг, поэтому лучше знакомиться с ними, читая первоисточник. Но есть кейсы, которые на первый взгляд хоть и кажутся простыми и стереотипными, но, если присмотреться к ним более пристально, могут дать пищу для размышления. Вот на одной из таких полезных задач мне хотелось бы заострить внимание в данной заметке. Формулируется вопрос следующим образом: «Необходимо определить количество пар товаров в продуктовых чеках. Вывести 10 самых частых сочетаний». Пример, чек 1 содержит товар 1, товар 2, товар 3, а чек 2 - товар 1, товар 2, товар 5. Следовательно, комбинация «товар 1, товар 2» встречается 2 раза, «товар 1 , товар 3» один раз и т.д.
В исходнике решать данный кейс предлагалось силами Python. Но реальная жизнь может потребовать от аналитика данных умения выполнять данное упражнение как с помощью SQL, так и Spark. Следовательно, рассмотрим три подхода, оставив за скобками разговора четвертый вариант – расчеты на платформах BI.

В этой статье мы популярно объясняем на собственном опыте как организовать массовую выгрузку, обработку и загрузку фотографий товаров из Bitrix, используя Python и минимальное количество SQL. Для прочтения будет полезно людям, выполняющим схожие задачи, не будучи при этом знакомыми с Битриксом.

Я работаю инженером в Call-центре. В круг моих обязанностей входит повышение эффективности прозвона call-листов. В этой статье речь идет о некоторых функциональных возможностях специального программного обеспечения (встроенный SQL), позволяющих существенно поднять эффективность проработки списков телефонов.

Прочитав статью и восприняв понимание продукта Oracle BI Publisher критически, а именно, на момент существовавшей тогда версии 11.1.1.7.150120, хочется заметить, что все, указанное в цитируемой статье можно было сделать на BI Publisher и доверить любому непрограммирующему пользователю. Плюс к этому, продукт имел trial и stand-alone версию. Поддерживался API на Java, уже был доделан вызов продукта как web-сервиса.
Чуть более интересный вопрос, который был получен от читателей моего блога: как в 12-й версии работать с переменными типа REF CURSOR для массовой миграции с самодельной отчетной системы на продукт Oracle BI EE 12с.
Рассмотрим код, который вернет REF CURSOR в зависимости от параметра.

Статья написана по мотивам работы "Forecasting SQL Query Cost at Twitter", 2021 («Прогнозирование стоимости SQL-запросов в Twitter»), представленной на IX Международной конференции IEEE по облачной инженерии (IC2E). Подробностями делимся, пока у нас начинается курс по Machine Learning и Deep Learning.
Всё началось с использования ML в BigQuery — оказалось это совсем не больно, и очень эффективно.
Мы в GFN.RU используем модель K-Means для поиска аномалий в работе сервиса. Ведь невозможно кожаному мешку смотреть десятки графиков по тысячам игр ежедневно. Пусть электрический болван подсказывает куда нужно глянуть.

7 октября мы провели второй митап о нюансах работы с большими объёмами данных. Под катом видео докладов наших разработчиков и приглашенного эксперта Microsoft Data Platform. Кейсы будут полезны тем, кто администрирует и разрабатывает DWH, создает аналитические запросы и работает c Microsoft SQL Server.

Всем привет, меня зовут Артём и я алкоголик долгое время не понимал базы данных. Ну, то есть я понимал концепт и как с ними работать, но всегда воспринимал их как чёрный ящик с понятным интерфейсом, который может сохранять и отдавать данные, если знать, как его об этом попросить. Механизмы, позволяющие магии случаться, были совершенно не понятны. И честно говоря, меня это особо не волновало. Бизнесу нужно, чтобы ты фичи фигачил, а не вот это вот всё.
Однако недавно я понял, что хватит это терпеть и настало время разобраться что происходит под капотом, как это происходит и зачем. Статья подойдёт тем, кто каждый день работает с базами данных и не особо вникает в подробности, людям, кто как и я заинтересовался тем, как всё работает и не знает откуда начать копать или просто тем, кто хочет немного освежить своё понимание баз данных.

Сегодня, 4 мая, в день Звездных войн мы подготовили для Вас подробный гайд по основным функциям библиотеки dplyr. Почему именно в день Звездных войн? А потому что разбирать мы все будем на примере датасета starwars.
Ну что, начнем!
IVI – кросс-платформенный сервис, а значит, мы должны анализировать метрики всюду: на вебе, телевизорах и мобильных приложениях. Продукт непрерывно развивается, чтобы стать максимально эффективным, удобным и повысить ценность и привлекательность подписки. Перед тем, как внедрить какую-то новую фичу, мы проводим a/b-тесты и исследуем, на сколько востребованным окажется нововведение и как оно повлияет на конверсию или смотрение. Одновременно у нас может проверяться до 70-ти гипотез, от которых непосредственно зависят планы по развитию продукта.
Для того, чтобы правильно оценить успешность или неуспешность теста, требовалось технологичное решение. Новая схема ETL позволила нам иметь хранилище, толерантное к дубликатам. При ошибке в коде мы всегда можем откатить consumer offset в kafka и обработать часть данных снова, не прилагая лишних усилий для движения данных. Хотим рассказать о том, как мы в IVI используем ClickHouse, чтобы посчитать метрики для решения разных продуктовых задач и понять, что мы действительно делаем продукт лучше, а не придумываем фичи, которыми никто не будет пользоваться.

Много уже говорилось о том, что SQLAlchemy - одна из самых популярных библиотек для создания схем баз данных. Сегодня рассмотрим несложный пример по созданию небольшой схемы данных для приложения по поиску цитат. В качестве СУБД будем использовать PostgreSQL.
Подход к определению моделей будем использовать декларативный, так как, на мой взгляд, он проще и понятнее классического подхода, основанного на mapper.

Сегодня я расскажу о том, как использовать функцию `UNNEST` в Google BigQuery для анализа параметров событий и свойств пользователей, которые вы получаете вместе с данными Google Analytics.
Всем привет!
То, что написано ниже относится к разряду "так делать не надо", однако, если вы считаете иначе — интересно будет услышать ваше мнение на этот счёт )
Наверное, многие из нас делали REST API, либо пользовались чьим-то готовым. Разберём в статье "невероятные" трюки, которые помогут сделать ваше API на голову выше, чем у других.

В преддверии старта нового набора на курс «Базы данных» продолжаем публиковать серию статей про шифрование в MySQL.
В предыдущей статье этой серии мы обсудили, как работает шифрование с главным ключом (Master Key). Сегодня, основываясь на полученных ранее знаниях, посмотрим на ротацию главных ключей.
Ротация главных ключей заключается в том, что генерируется новый главный ключ и этим новым ключом повторно шифруются ключи табличных пространств (которые хранятся в заголовках табличных пространств).
Давайте вспомним, как выглядит заголовок зашифрованного табличного пространства:

