Comments 75
Это для атомарных объектов. А теперь чуть-чуть усложните задачу — пусть нужно делать itoa(atoi(value)++). То есть взять _СТРОКУ_ (которая не укладывается в регистр), сделать с ней что-то и положить обратно.
Мне кажется, что на неатомарных объектах картинка будет совсем другой.
Мне кажется, что на неатомарных объектах картинка будет совсем другой.
Запустил на свое старом добром C2Q E6600
ждемс.
ждемс.
Впрочем нет, результаты дам с утра оставлю на ночь гонять.
Готово rghost.ru/25250751
Наверное, наибольшее значение имеют результаты для одного потока, а если в программе десяток потоков действительно постоянно борются за одну блокировку, то что-то здесь не так :-)
ARM Cortex A9 и двухпроцессорная машина с Intel Xeon E5345 (всего 8 ядер)
github.com/korisk/pinc/pull/1
github.com/korisk/pinc/pull/1
> Я честно перечитал это десять раз, но оно всё равно сломало мне мозг.
там итерируется число потоков, от 1 до N, поэтому BIG_NUMBER должно быть кратно не только N, но и N!, и оно берётся равным T!, где T > N.
там итерируется число потоков, от 1 до N, поэтому BIG_NUMBER должно быть кратно не только N, но и N!, и оно берётся равным T!, где T > N.
Изначально не было цели запускать пучки с количеством нитей большее чем число процессоров. Факториал остался с тех пор.
Далее:
1. Про графики спорить не стану. Мне так больше нравится.
1а. При измерений кол-ва операций в секунду слишком большие числа получаются, да и переносимого средства нет, чтобы эти операции считать(знаю только rdtsc) поэтому миллисекунды.
2. В каждой точке — один замер. Про доверительные интервалы — интересная идея, однако полноценный эксперимент занял бы слишком много времени.
3а. Время измерения каждой точки, указано на оси ординат. Влияние шедулера не исключается.
3б. Возможно, с какой-то точки зрения, правильнее, твердо утверждать не могу, но в этой версии сделано так.
4. 100 тредов т.к. вспомнил про 80 ядерные серверы. Ну ещё, на большом количестве нитей могла нарушаться линейность. Теперь, ясно, что до ста нитей все более-менее линейно, кроме спинлоков.
5аб. Чтобы избежать влияния асинхронности старта выбирается достаточно большое «большое число». Условие достаточности — интуиция. Да, не научно :). Где-то читал, что старт нити занимает десять микросекунд, т.к. максимальная рассинхронизация при ста нитях — 1мсек. Примерно 1 тысячная среднего замера. С процессами финализаци аналогично. Возможно вам известны другие способы борьбы с переходными процессами, рад буду узнать.
На мой взгляд, Вашим единственным серьезным доводом против теста является отсутствие статистической обработки результатов. Однако, спасибо за потраченное время.
Далее:
1. Про графики спорить не стану. Мне так больше нравится.
1а. При измерений кол-ва операций в секунду слишком большие числа получаются, да и переносимого средства нет, чтобы эти операции считать(знаю только rdtsc) поэтому миллисекунды.
2. В каждой точке — один замер. Про доверительные интервалы — интересная идея, однако полноценный эксперимент занял бы слишком много времени.
3а. Время измерения каждой точки, указано на оси ординат. Влияние шедулера не исключается.
3б. Возможно, с какой-то точки зрения, правильнее, твердо утверждать не могу, но в этой версии сделано так.
4. 100 тредов т.к. вспомнил про 80 ядерные серверы. Ну ещё, на большом количестве нитей могла нарушаться линейность. Теперь, ясно, что до ста нитей все более-менее линейно, кроме спинлоков.
5аб. Чтобы избежать влияния асинхронности старта выбирается достаточно большое «большое число». Условие достаточности — интуиция. Да, не научно :). Где-то читал, что старт нити занимает десять микросекунд, т.к. максимальная рассинхронизация при ста нитях — 1мсек. Примерно 1 тысячная среднего замера. С процессами финализаци аналогично. Возможно вам известны другие способы борьбы с переходными процессами, рад буду узнать.
На мой взгляд, Вашим единственным серьезным доводом против теста является отсутствие статистической обработки результатов. Однако, спасибо за потраченное время.
5аб. Просто пусть все рабочие потоки в самом начале блокируются на семафоре, а после запуска всех потоков main() увеличивает семафор на количество потоков. Или pthread_barrier_*
Заниматься тестом нет смысла совсем по другой, imho, причине: выводы и так очевидны, их можно сделать из особенностей реализации каждого из метода.
Да ладно… Неужели действительно не очевидно, что активное ожидание в spinlock будет менее эффективно, чем mutex, который останавливает нити, если нельзя продолжить их исполнение, который будет менее эффективен, чем compare-and-swap, который циклически будет выполнять некоторую операцию (которая похожа на ту, что нужна для организации mutex-ов); а CAS будет менее эффективен, чем просто исполнение атомрной операции добавления единички?
Хм… Даже линейный рост времени работы spinlock очень просто объясняется тем, что чем больше нитей, тем дольше они вместе впустую крутят spin-циклы.
Зачем тут хиндсайт?
Хм… Даже линейный рост времени работы spinlock очень просто объясняется тем, что чем больше нитей, тем дольше они вместе впустую крутят spin-циклы.
Зачем тут хиндсайт?
Так исходники же есть. Берём просто и смотрим… Нет? Единственным загадочным моментом (с натяжкой) можно было бы считать сравнение cmpxchg с xadd (не lock add, кстати), но там используется один и тот же механизм блокировки адреса для атомарного выполнения адресации (read-modify-write же стандартный). Если покопаться, даже патенты можно найти на эту тему.
В общем, не знаю. Интересно было бы тестировать это всё на не столь примитивном вычислении, тогда бы да, полезли бы всякие косяки и хитрости, связанные с кэшами. Но вот результаты этого теста полностью предсказуемые на любом (вменяемом) оборудовании.
В общем, не знаю. Интересно было бы тестировать это всё на не столь примитивном вычислении, тогда бы да, полезли бы всякие косяки и хитрости, связанные с кэшами. Но вот результаты этого теста полностью предсказуемые на любом (вменяемом) оборудовании.
* выполнения операции (что-то пора выспаться уже… хых)
Хардвар неплохо описан в документации, достаточно детально. Кроме этого, есть общая теория построения параллельного железа, которую надо бы знать. Конечно, тесты на разных аппаратных платформах были бы интересны. Например, для IA-64 spinlock сделан в NTPL иначе, да и железяка совсем другая по способам работы с памятью.
Но на одном и том же процессоре с широко известной архитектурой. Ну, не знаю…
Но на одном и том же процессоре с широко известной архитектурой. Ну, не знаю…
Ну, не знаю. По-моему, это не эффективно. В статье же заявлялось: давайте проясним вопрос mutex vs. X Y Z.
Но проясняется-то вопрос: как быстрее устроить коллективный атомарный инкремент на процессорах семейства x86. А это очевидно без всяких тестов, потому как напрямую следует из особенностей их работы. И тут не надо никаких мелких деталей знать. Всего лишь базовые, общеизвестные, алгоритмы и примитивы синхронизации.
Вот если бы тест был сделан хотя бы для разных машин (ARM, например) — было бы много ценнее.
Но проясняется-то вопрос: как быстрее устроить коллективный атомарный инкремент на процессорах семейства x86. А это очевидно без всяких тестов, потому как напрямую следует из особенностей их работы. И тут не надо никаких мелких деталей знать. Всего лишь базовые, общеизвестные, алгоритмы и примитивы синхронизации.
Вот если бы тест был сделан хотя бы для разных машин (ARM, например) — было бы много ценнее.
Спасибо, у меня есть работа :) И никакого ада там нет. Методика разработана и отлажена уже лет 20 как назад, просто Intel и AMD потащили это в массы только сейчас, но сами алгоритмы работы железа были известны давно, и для них были созданы структуры Крипке для верификации, и всё ОК, железячники могут накосячить только поставив неправильный транзистор, но это тоже маловероятно (у них там все транзисторы стандартные в наше время).
Ну… Вообще, так, чтобы вы имели представление — я профессионально занимаюсь разработкой высокопроизводительных приложений, поэтому понимаю о чём говорю. И нет тут никаких гаданий, вновь повторюсь: всё стандартно и задокументировано.
Косяки могут быть на архитектурах со слабой когерентностью памяти, на ранних SMP версиях ARM, например. Но там же поведение тоже хорошо задокументировано. И известно, как правильно сделать инкремент.
В общем, не понимаю Вашей озадаченности.
Ну… Вообще, так, чтобы вы имели представление — я профессионально занимаюсь разработкой высокопроизводительных приложений, поэтому понимаю о чём говорю. И нет тут никаких гаданий, вновь повторюсь: всё стандартно и задокументировано.
Косяки могут быть на архитектурах со слабой когерентностью памяти, на ранних SMP версиях ARM, например. Но там же поведение тоже хорошо задокументировано. И известно, как правильно сделать инкремент.
В общем, не понимаю Вашей озадаченности.
По-моему, вы подменяете понятия. Вопрос же идёт не о производительности, а об эффективности: какой из методов вносит наименьшее число накладных расходов.
И стандартны и задокументированы совсем не латентности операций, а способы обеспечения атомарности в многопроцессорных системах.
Ну не может цикл из cmpxchgl работать эффективнее, чем одна инструкция, требующая тех же самых операций для контроля совместного доступа к линии памяти (ну, а в данном конкретном случае даже более простая, так как результат её не востребован).
По каким, по вашему мнению, причинам такой цикл может выполняться быстрее? И по каким причинам mutex может быть эффективнее этого цикла, и почему spinlock вдруг окажется эффективнее mutex? Должны же быть какие-то основания это предполагать.
Ну, и, конечно, я совсем не утверждаю, что умею точно предсказывать IPC или там производительность в транзакциях в секунду, но эффективности методов в данном конкретном случае — очевидны. На большее я и не претендую.
А про сложные задачи я так и написал — прямым текстом, что для сложной задачи анализ мог бы представлять интерес, потому что (вы меня прямо повторяете), иерархия памяти.
И стандартны и задокументированы совсем не латентности операций, а способы обеспечения атомарности в многопроцессорных системах.
Ну не может цикл из cmpxchgl работать эффективнее, чем одна инструкция, требующая тех же самых операций для контроля совместного доступа к линии памяти (ну, а в данном конкретном случае даже более простая, так как результат её не востребован).
По каким, по вашему мнению, причинам такой цикл может выполняться быстрее? И по каким причинам mutex может быть эффективнее этого цикла, и почему spinlock вдруг окажется эффективнее mutex? Должны же быть какие-то основания это предполагать.
Ну, и, конечно, я совсем не утверждаю, что умею точно предсказывать IPC или там производительность в транзакциях в секунду, но эффективности методов в данном конкретном случае — очевидны. На большее я и не претендую.
А про сложные задачи я так и написал — прямым текстом, что для сложной задачи анализ мог бы представлять интерес, потому что (вы меня прямо повторяете), иерархия памяти.
Задокументированы-то они с функциональной точки зрения, т.е. «используйте вот это, и будет вам атомарность». Про производительность никто там не говорит. Поэтому и нескольких способов обеспечить атомарность приходится выбирать наиболее эффективный. Эта пресловутая эффективность даже зависит от модели проца, или даже степпингов. Для того бенчмаркинг и нужен, чтобы определить, какой из способов юзать.
Не согласен. Задокументированы они как раз в виде описания того, какие пакеты куда рассылаются по шине. Деталей особых нет, но автомат состояний в optimization guide есть. Этого, imho, достаточно.
Например, история с барьерами, когда в x86 ISA появились инструкции типа mfence/lfence/sfence, и «задокументировано» было мол, юзайте эти инструкции для барьеров. И чего, кто-то их использует? Хрена с два, оказалось, что «lock addl esp, $0» работает куда быстрее, и обеспечивает необходимый side effect.
Это сравниваются два разных механизма, mfence — это дождаться завершения всех операций с памятью, со всеми кэшами и объявлениями об изменениях и запросах на чтение на внешней шине. А lock-add — это запрос на атомарное исполнение инструкций. Как бы, разное. Где гарантия, что side-effect-ы будут сохранены в новых процессорах? Поэтому, если Intel сказал, пользуйтесь mfence — надо им и пользоваться.
И ничего тут нет контринтуитивного, если действительно доку читать, mfence и должен быть медленней. Просто да, у AMD такая вот архитектура работы с памятью (потому и проигрывали Intel, сейчас тоже проигрывают, но там причины пока не понятны).
Но это вообще не относится к обсуждаемому нами случаю. Используются однотипные (locked read-modify-write) инструкции, в первом варианте — одна, во втором — несколько в цикле. Почему вы думаете, что инженеры решили пустить их по разным путям исполнения в процессоре?
Например, потому, что mutex сделает удачный CAS на захвате, инкрементирует поле, и выйдет. A «lock inc [mem]» оттормозит из-за partial register stall в inc, и нагнёт тем самым конвейер.Так вы рассматриваете единичный случай, когда синхронизации редкие. Тогда да, может это всё сказываться. Но когда за ресурс конкурирует много потоков, то все эти тонкости перестают оказывать влияния: на любом участке синхронизации с конвейерами полная задница, поэтому их и рекомендуют делать как можно реже в любом случае.
Не согласен. Задокументированы они как раз в виде описания того, какие пакеты куда рассылаются по шине. Деталей особых нет, но автомат состояний в optimization guide есть. Этого, imho, достаточно.
Например, история с барьерами, когда в x86 ISA появились инструкции типа mfence/lfence/sfence, и «задокументировано» было мол, юзайте эти инструкции для барьеров. И чего, кто-то их использует? Хрена с два, оказалось, что «lock addl esp, $0» работает куда быстрее, и обеспечивает необходимый side effect.
Это сравниваются два разных механизма, mfence — это дождаться завершения всех операций с памятью, со всеми кэшами и объявлениями об изменениях и запросах на чтение на внешней шине. А lock-add — это запрос на атомарное исполнение инструкций. Как бы, разное. Где гарантия, что side-effect-ы будут сохранены в новых процессорах? Поэтому, если Intel сказал, пользуйтесь mfence — надо им и пользоваться.
И ничего тут нет контринтуитивного, если действительно доку читать, mfence и должен быть медленней. Просто да, у AMD такая вот архитектура работы с памятью (потому и проигрывали Intel, сейчас тоже проигрывают, но там причины пока не понятны).
Но это вообще не относится к обсуждаемому нами случаю. Используются однотипные (locked read-modify-write) инструкции, в первом варианте — одна, во втором — несколько в цикле. Почему вы думаете, что инженеры решили пустить их по разным путям исполнения в процессоре?
Например, потому, что mutex сделает удачный CAS на захвате, инкрементирует поле, и выйдет. A «lock inc [mem]» оттормозит из-за partial register stall в inc, и нагнёт тем самым конвейер.Так вы рассматриваете единичный случай, когда синхронизации редкие. Тогда да, может это всё сказываться. Но когда за ресурс конкурирует много потоков, то все эти тонкости перестают оказывать влияния: на любом участке синхронизации с конвейерами полная задница, поэтому их и рекомендуют делать как можно реже в любом случае.
Не знаю… Я перечитал и 8.2.2, и 7.5 из System Programming Manual от AMD, и мне кажется, тут есть тонкое различие.
lock гарантирует только порядок завершения операций, а mfence гарантирует порядок видимостей операций с памятью для внешнего мира. По-моему, здесь есть некоторая разница. И можно задаться вопросами.
Всегда ли должно быть верно, что завершение операции с памятью включает завершение всех объявлений о ней на внешних шинах?
Верно ли то, что следующие за lock-инструкцией операции не будут начаты до её завершения? (это гарантирует mfence)
И верно ли то, что lock-инструкция не будет начата до завершения всех предыдущих операций с памятью? У AMD написано, что она всего лишь не завершается до завершения предыдущих операций. Может ли быть так, что начинается LD по адресу X, а затем начинается #LOCK RMW по адресу X + cachelinesize, и они выполняются параллельно?
Не уверен я, что следует lock-инструкцию трактовать как полный барьер.
lock гарантирует только порядок завершения операций, а mfence гарантирует порядок видимостей операций с памятью для внешнего мира. По-моему, здесь есть некоторая разница. И можно задаться вопросами.
Всегда ли должно быть верно, что завершение операции с памятью включает завершение всех объявлений о ней на внешних шинах?
Верно ли то, что следующие за lock-инструкцией операции не будут начаты до её завершения? (это гарантирует mfence)
И верно ли то, что lock-инструкция не будет начата до завершения всех предыдущих операций с памятью? У AMD написано, что она всего лишь не завершается до завершения предыдущих операций. Может ли быть так, что начинается LD по адресу X, а затем начинается #LOCK RMW по адресу X + cachelinesize, и они выполняются параллельно?
Не уверен я, что следует lock-инструкцию трактовать как полный барьер.
Я просто сомнения высказываю в том, что lock — это именно то, что надо. И что даже если оно и эффективнее, то не факт, что его следует использовать без привязки к определённым моделям процессоров. И я же, наоборот, утверждаю, что mfence — это более тяжёлая по семантике инструкция, чем lock-rmw.
НО. Источник же наших баранов совсем не в этом :) Изначально я говорил: очевидно, что цикл из нескольких lock-rmw инструкций будет выполняться в среднем медленней, чем одна lock-rmw инструкция. Вот и всё. Про mfence я ничего не утверждал — это инструкция совсем другого типа, и тут действительно надо разбираться.
НО. Источник же наших баранов совсем не в этом :) Изначально я говорил: очевидно, что цикл из нескольких lock-rmw инструкций будет выполняться в среднем медленней, чем одна lock-rmw инструкция. Вот и всё. Про mfence я ничего не утверждал — это инструкция совсем другого типа, и тут действительно надо разбираться.
А про __sync_fetch_and_add, зависит от того, как используется. Когда результат не нужен, то, действительно, можно обойтись add. А когда нужен:
$ cat fadd.c
int main(int argc, char **argv)
{
volatile int field;
int x = __sync_fetch_and_add(&field, 1);
return x;
}
$ gcc -mtune=native -O3 -c fadd.c
$ objdump -S fadd.o
fadd.o: file format elf64-x86-64
Disassembly of section .text.startup:
0000000000000000 <main>:
0: b8 01 00 00 00 mov $0x1,%eax
5: f0 0f c1 44 24 fc lock xadd %eax,-0x4(%rsp)
b: c3 retq
Эмс… Логика fetch_and_add подразумевает возвращение предыдущего значения, и оно может быть реализовано при помощи lock add или lock inc только тогда, когда это значение не используется. Я вот о чём.
С точки зрения процессора fetch_and_add — это именно xadd. Комплиятор же может немного пооптимизировать.
С точки зрения процессора fetch_and_add — это именно xadd. Комплиятор же может немного пооптимизировать.
Круто завернул, товарисч. И не поспоришь и не буду.
Отмечу, что pinc — это всего лишь инструмент. Если есть идеи как сделать «правильный» на ваш взгляд тест — добро пожаловать. Новый тест легко добавить.
Хватит критиканствовать! Как правильно?
Еще раз по пункту два: «собираем результаты N запусков, формируем выборки, вычисляем характеристики распределений и доверительные интервалы, если угодно»
И спасибо за звание бенчмарка. Звучит. :)
Отмечу, что pinc — это всего лишь инструмент. Если есть идеи как сделать «правильный» на ваш взгляд тест — добро пожаловать. Новый тест легко добавить.
Хватит критиканствовать! Как правильно?
Еще раз по пункту два: «собираем результаты N запусков, формируем выборки, вычисляем характеристики распределений и доверительные интервалы, если угодно»
И спасибо за звание бенчмарка. Звучит. :)
Слишком неоднозначно выбрана имитация полезной работы. Ваш цикл нормальный компилятор развернёт в последовательность инкремент, правда тоже в цикле, но сколько именно итераций будет сделано вы не узнаете. Ну и про то что несчастный incremented висел в кэше тоже забывать нельзя.
Раскрутка цикла имеет значение только для последовательной версии. Для параллельных версий, в цикле блокировки стоят или последовательно, значение не имеет.
Также и с кэшем. Замечание правильно, только для последовательной последовательного случая и случая, когда несколько нитей выполняются на одном процессоре. Для нескольких нитей, работающих на нескольких процессорах кэш влиять не будет т.к. каждая операция с переменной потребует обращения к глобальной памяти.
Ну а вообще, влияние кэша тоже входит в измеряемы числа.
Также и с кэшем. Замечание правильно, только для последовательной последовательного случая и случая, когда несколько нитей выполняются на одном процессоре. Для нескольких нитей, работающих на нескольких процессорах кэш влиять не будет т.к. каждая операция с переменной потребует обращения к глобальной памяти.
Ну а вообще, влияние кэша тоже входит в измеряемы числа.
Да вообще зачем лочить инкремент volatile переменной? Ну а про несколько нитей и кеш вы все-таки не совсем правы. В конкретно вашем случае переключения на другой поток исполнения будет происходить по решению планировщика ОС, и вероятно выполнение нескольких итераций цикла подряд. Так что кэш тут влияет.
(б) — нет, с volatile не может.
1.9.7:
Accessing an object designated by a volatile lvalue (3.10), modifying an object, calling a library I/O function, or
calling a function that does any of those operations are all side effects, which are changes in the state of the execution
environment. Evaluation of an expression might produce side effects. At certain specified points in the execution sequence called sequence points, all side effects of previous evaluations shall be complete and no side effects of subsequent
evaluations shall have taken place.
Sequence point имеется после каждого statement.
Семантики с точки зрения видимости в других потоках у volatile может не быть, но точно есть семантика с точки зрения видимости железом. Он вообще изначально вводился для работы с портами ввода-вывода и подобными вещами, где каждая операция над ячейкой памяти наблюдается кем-то со стороны и может быть проинтерпретирована как угодно. Поэтому обращения к volatile переменным не могут быть склеены или переставлены _компилятором_ (процессором — могут быть переставлены, и поэтому он бесполезен для синхронизации потоков).
Accessing an object designated by a volatile lvalue (3.10), modifying an object, calling a library I/O function, or
calling a function that does any of those operations are all side effects, which are changes in the state of the execution
environment. Evaluation of an expression might produce side effects. At certain specified points in the execution sequence called sequence points, all side effects of previous evaluations shall be complete and no side effects of subsequent
evaluations shall have taken place.
Sequence point имеется после каждого statement.
Семантики с точки зрения видимости в других потоках у volatile может не быть, но точно есть семантика с точки зрения видимости железом. Он вообще изначально вводился для работы с портами ввода-вывода и подобными вещами, где каждая операция над ячейкой памяти наблюдается кем-то со стороны и может быть проинтерпретирована как угодно. Поэтому обращения к volatile переменным не могут быть склеены или переставлены _компилятором_ (процессором — могут быть переставлены, и поэтому он бесполезен для синхронизации потоков).
Но как вы смогли сделать PNG картинку с графиком размера 640x384 и чтобы она весила 700 кб?
Просторечие неприемлемо? Попытаюсь ответить строже:
to TheShade:
>Штука в том, что все мои доводы есть доводы в пользу несостоятельности теста. И пока не доказано обратное по каждому из доводов, тест не состоятелен.
В действительность, большинство ваших утверждений, относятся к области личных предпочтений, но ни как не к сущности теста. Переформулирую свои ответы в более понятной форме.
1.Как форма представления результатов влияет на состоятельность теста? Никак.
2.Как отсутствие статистической обработки влияет не состоятельность теста? Статистику составляют по результатам теста, а не до и не во время.
3.Этот тест не измеряет латентность, он её оценивает с позиции обычного программиста, для которого консоль любой linux машины выглядит одинаково, не зависимо от процессора.
4.В тесте, есть специальный параметр — мерь сколько хочешь. Как это влияет на состоятельность теста? Никак.
5.Абсолютная синхронизация все равно не возможна, даже с использованием барьеров или условных переменных. Так для сравнения муравейников, не нужно взвешивать каждого муравья, достаточно взвесить весь муравейник, пусть даже туда попадет дюжина сверчков. На относительных весах муравейников это мало скажется. Надеюсь, здесь понятно.
Про «не научность».
>Ваше «не научно» ломает вообще всякий повод тестом заниматься. «Научно» нужно не для того, чтобы этим гордиться, а для того, чтобы предубеждения по поводу теста, которые вы изложили в качестве доводов в ответном комментарии, отделить от объективных фактов. Пока вы это не сделаете, тестом заниматься смысла нет.
Не хотелось бы опускаться до «сам дурак», поэтому назову исходные обвинения софизмами без существенных оснований. А вообще, это не научная статья, скорее техническая, а если посмотреть ещё глубже, то это запрос к общественности предоставить интересующие меня данные. Но если для вас лично нет смысла заниматься моим тестом :) я скорее обрадуюсь, чем расстроюсь.
>Т.е. компилятор потенциально может сделать эту трансформацию, ещё больше искажая результат.
Потенциально может, но ведь не делает. Появятся оптимизаторы — придется подправить тест, если он будет ещё востребован.
to mikhanoid
> выводы и так очевидны, их можно сделать из особенностей реализации каждого из методов.
Возможно, они очевидны для опытного человека, часто имеющим дело с разными механизмами блокировки. Для того кто впервые задумался об альтернативах для mutex, все не так просто.
to TheShade:
>Штука в том, что все мои доводы есть доводы в пользу несостоятельности теста. И пока не доказано обратное по каждому из доводов, тест не состоятелен.
В действительность, большинство ваших утверждений, относятся к области личных предпочтений, но ни как не к сущности теста. Переформулирую свои ответы в более понятной форме.
1.Как форма представления результатов влияет на состоятельность теста? Никак.
2.Как отсутствие статистической обработки влияет не состоятельность теста? Статистику составляют по результатам теста, а не до и не во время.
3.Этот тест не измеряет латентность, он её оценивает с позиции обычного программиста, для которого консоль любой linux машины выглядит одинаково, не зависимо от процессора.
4.В тесте, есть специальный параметр — мерь сколько хочешь. Как это влияет на состоятельность теста? Никак.
5.Абсолютная синхронизация все равно не возможна, даже с использованием барьеров или условных переменных. Так для сравнения муравейников, не нужно взвешивать каждого муравья, достаточно взвесить весь муравейник, пусть даже туда попадет дюжина сверчков. На относительных весах муравейников это мало скажется. Надеюсь, здесь понятно.
Про «не научность».
>Ваше «не научно» ломает вообще всякий повод тестом заниматься. «Научно» нужно не для того, чтобы этим гордиться, а для того, чтобы предубеждения по поводу теста, которые вы изложили в качестве доводов в ответном комментарии, отделить от объективных фактов. Пока вы это не сделаете, тестом заниматься смысла нет.
Не хотелось бы опускаться до «сам дурак», поэтому назову исходные обвинения софизмами без существенных оснований. А вообще, это не научная статья, скорее техническая, а если посмотреть ещё глубже, то это запрос к общественности предоставить интересующие меня данные. Но если для вас лично нет смысла заниматься моим тестом :) я скорее обрадуюсь, чем расстроюсь.
>Т.е. компилятор потенциально может сделать эту трансформацию, ещё больше искажая результат.
Потенциально может, но ведь не делает. Появятся оптимизаторы — придется подправить тест, если он будет ещё востребован.
to mikhanoid
> выводы и так очевидны, их можно сделать из особенностей реализации каждого из методов.
Возможно, они очевидны для опытного человека, часто имеющим дело с разными механизмами блокировки. Для того кто впервые задумался об альтернативах для mutex, все не так просто.
>Т.е. мне дали тест, попросили его запустить, и мне же ещё надо и разбираться, чтобы он нормально запустился. У меня вот в лабе 256-ядерный сервак, и если я даже объясню себе, что неплохо этот тест прогнать, для меня затруднительно понять, что мне же его придётся и допиливать.
Тогда почему бы и не допилить — раз вы столь хороши в тестах производительности? Лицензия GPL, открытых аналогов вроде нет. Получился бы интересный инструмент.
Тогда почему бы и не допилить — раз вы столь хороши в тестах производительности? Лицензия GPL, открытых аналогов вроде нет. Получился бы интересный инструмент.
Если вы пишете тесты, также как умеете критиковать, то цены вам нет :).
Тесты — не моя рыба.
Я сделал эту работу, т.к. не нашел удовлетворяющих меня готовых программ. Видимо специалисты по тестам не создали.
Тесты — не моя рыба.
Я сделал эту работу, т.к. не нашел удовлетворяющих меня готовых программ. Видимо специалисты по тестам не создали.
Они не виноваты, они просто не сделали :).
Ну если бы в результатах приведенных тут, большое значение играла случайность, закономерностей в графиках, как вы понимаете, не было бы. А в них, проглядывается, монотонность и некоторые общие тенденции. Шум может и есть, но он не велик, а большинство графиков, так вообще почти константы. Получается, что общая оценка зависимости задержек от количества нитей вполне возможна.
Может быть получить точную оценку латентности заданного механизма и для заданной машины не получится, но она и не нужна.
В общем считаю, что поставленные перед тестом задачи он решает.
Если же вы не согласны, то какова должна быть обработка на ваш взгляд?
Ну если бы в результатах приведенных тут, большое значение играла случайность, закономерностей в графиках, как вы понимаете, не было бы. А в них, проглядывается, монотонность и некоторые общие тенденции. Шум может и есть, но он не велик, а большинство графиков, так вообще почти константы. Получается, что общая оценка зависимости задержек от количества нитей вполне возможна.
Может быть получить точную оценку латентности заданного механизма и для заданной машины не получится, но она и не нужна.
В общем считаю, что поставленные перед тестом задачи он решает.
Если же вы не согласны, то какова должна быть обработка на ваш взгляд?
Вы бы лучше не минусовали, а подсказали, какая должна быть обработка.
Замечу, что нужно разделять тест, эксперимент и результаты эксперимента. Статистическая обработка обычно проводится над результатами эксперимента. Эксперимент состоит из одного или нескольких испытаний.
Итак, доверительные интервалы. Чтобы посчитать доверительный интервал, нужно заранее знать закон распределения случайной величины и иметь результаты нескольких испытаний.
Если закон не известен, то придется подбирать распределение, которое лучше всего подходит для данного случая. И не факт, что распределения будут одинаковы для разных машин.
Т.е. чтобы посчитать доверительный интервал, придется выполнить много разнообразной работы, и не факт что получится правдоподобный результат, т.к. запутаться проще простого.
Гораздо выгоднее следовать принципу KISS и использовать закон больших чисел, который не зависит от распределения. Не нужно оценивать распределение, не нужно формировать выборки — делаете один длительный замер и всё.
Единственным слабым местом, которое я готов признать, является выбор Большого_Числа, которое проводилось «на глаз». Но опять же это недостаток эксперимента, а не теста.
Если вы и после этих доводов считаете тест несостоятельным, давайте обратимся к авторитету мировой общественности.
Вот нашел несколько тестов. Максимальная обработка которая здесь проводится — нахождения среднего:
FTQ
HPL, STREAM
На основании результатов HPL, формируется Top500. HPL формирует большую случайную систему линейных уравнений, решает её, замеряет время решения. Делит размерность задачи (ширина матрицы в кубе) на время и получает флопсы.
Говорят «получено N гигафлопс на линпаке». Всё. Никаких исключений случайных факторов типа промахов кэша или коллизий в сети. Никакой статистической обработки в тесте.
Повторю, что считаю приведенный тест решает поставленные перед ним задачи. Если же нужна особо точная обработка результатов её можно выполнить отдельно! Надеюсь, вы согласитесь с этим.
Итак, доверительные интервалы. Чтобы посчитать доверительный интервал, нужно заранее знать закон распределения случайной величины и иметь результаты нескольких испытаний.
Если закон не известен, то придется подбирать распределение, которое лучше всего подходит для данного случая. И не факт, что распределения будут одинаковы для разных машин.
Т.е. чтобы посчитать доверительный интервал, придется выполнить много разнообразной работы, и не факт что получится правдоподобный результат, т.к. запутаться проще простого.
Гораздо выгоднее следовать принципу KISS и использовать закон больших чисел, который не зависит от распределения. Не нужно оценивать распределение, не нужно формировать выборки — делаете один длительный замер и всё.
Единственным слабым местом, которое я готов признать, является выбор Большого_Числа, которое проводилось «на глаз». Но опять же это недостаток эксперимента, а не теста.
Если вы и после этих доводов считаете тест несостоятельным, давайте обратимся к авторитету мировой общественности.
Вот нашел несколько тестов. Максимальная обработка которая здесь проводится — нахождения среднего:
FTQ
HPL, STREAM
На основании результатов HPL, формируется Top500. HPL формирует большую случайную систему линейных уравнений, решает её, замеряет время решения. Делит размерность задачи (ширина матрицы в кубе) на время и получает флопсы.
Говорят «получено N гигафлопс на линпаке». Всё. Никаких исключений случайных факторов типа промахов кэша или коллизий в сети. Никакой статистической обработки в тесте.
Повторю, что считаю приведенный тест решает поставленные перед ним задачи. Если же нужна особо точная обработка результатов её можно выполнить отдельно! Надеюсь, вы согласитесь с этим.
>Про распределения — это всё отмазки.
Если быть последовательно точным, то точным до конца, и получить честные результаты. ИМХО.
>НЕЛЬЗЯ взять два сэмпла из случайной величины, и на основании только этих двух сэмплов судить об их распределениях
О том и речь, что нельзя. Если использовать закон больших чисел, то и не нужно. Если проводить измерение много раз, то среднее арифметческое будет стремиться к матожиданию независимо от закона распределения. Лишь бы он не изменялся в процессе измерений.
>Ваш же бенчмарк публичным не является
Мой тест открыт и публичен. Вот исходный код. Он оценивает зависимость времени затрачиваемого на N операций от числа нитей выполняющие эти операции. Единичный запуск теста реализует одно испытание. Статистическая обработка выборки из нескольких испытаний в пакет не входит.
>Вы бы внимательнее прочитали статейку про FTQ, особенно последний абзац про «Validating Data»
И что? Там вычисляются статистические моменты на основе результатов теста.:
«Load the FTQ time output files, process the data, and print out the statistics..»
Да, вычисляются с помощью специального сценария, но то же самое можно проделать и с результатами моего теста и с результатами линпака.
Отсутствие такого скрипта никак не влияет на сам тест.
Если быть последовательно точным, то точным до конца, и получить честные результаты. ИМХО.
>НЕЛЬЗЯ взять два сэмпла из случайной величины, и на основании только этих двух сэмплов судить об их распределениях
О том и речь, что нельзя. Если использовать закон больших чисел, то и не нужно. Если проводить измерение много раз, то среднее арифметческое будет стремиться к матожиданию независимо от закона распределения. Лишь бы он не изменялся в процессе измерений.
>Ваш же бенчмарк публичным не является
Мой тест открыт и публичен. Вот исходный код. Он оценивает зависимость времени затрачиваемого на N операций от числа нитей выполняющие эти операции. Единичный запуск теста реализует одно испытание. Статистическая обработка выборки из нескольких испытаний в пакет не входит.
>Вы бы внимательнее прочитали статейку про FTQ, особенно последний абзац про «Validating Data»
И что? Там вычисляются статистические моменты на основе результатов теста.:
«Load the FTQ time output files, process the data, and print out the statistics..»
Да, вычисляются с помощью специального сценария, но то же самое можно проделать и с результатами моего теста и с результатами линпака.
Отсутствие такого скрипта никак не влияет на сам тест.
Тада-ам! Теперь обещанные результаты тестов, в том числе на ARM.


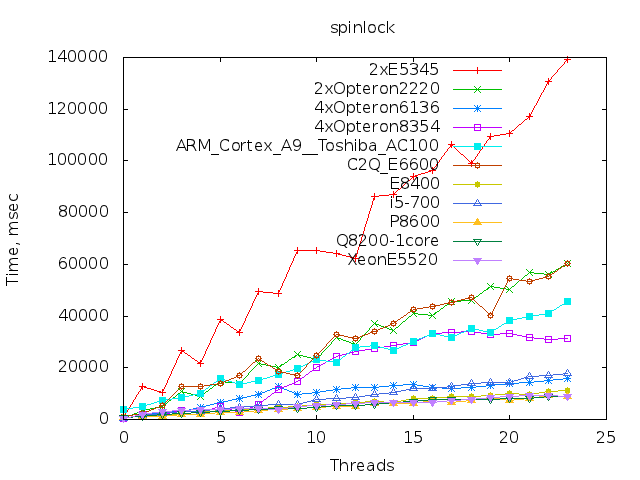
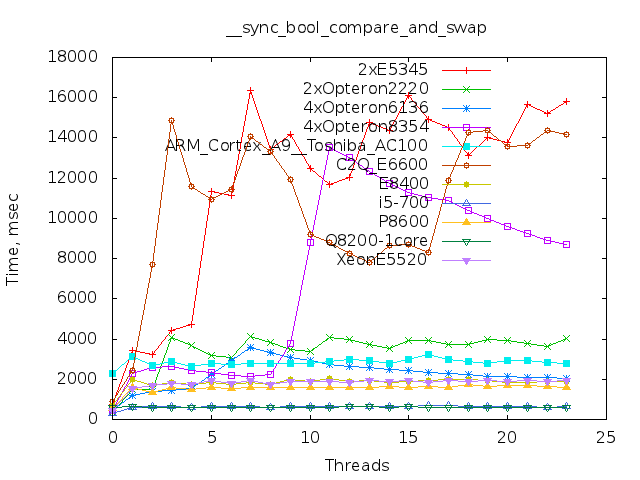
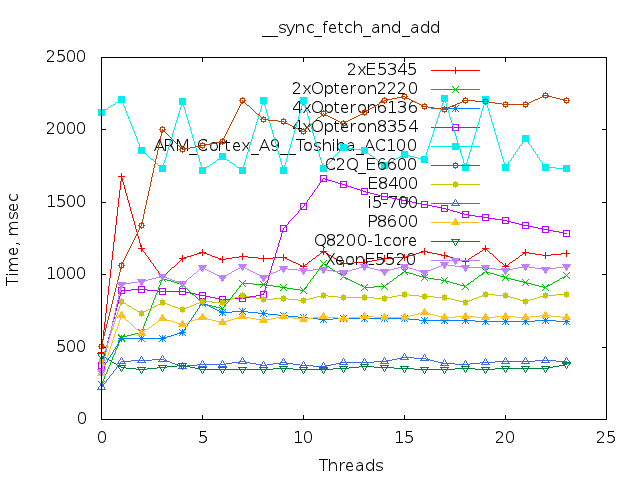
Расшифровка:
2xE5345: Intel® Xeon® CPU E5345 @ 2.33GHz 8 of 8 cores online
2xOpteron2220: Dual-Core AMD Opteron(tm) Processor 2220 4 of 4 cores online
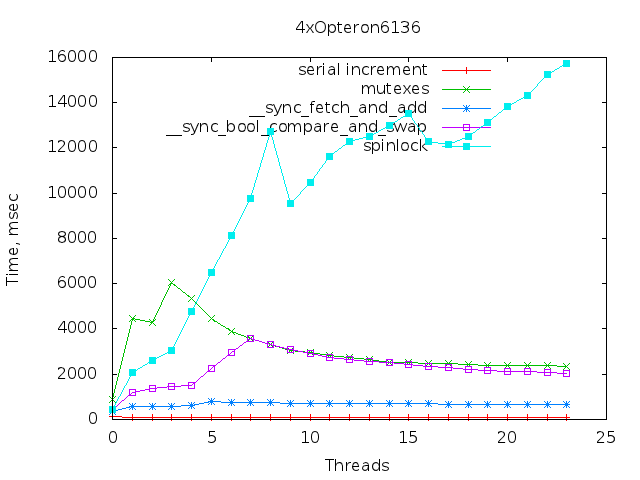
4xOpteron6136: AMD Opteron(tm) Processor 6136 32 of 32 cores online
4xOpteron8354: Quad-Core AMD Opteron(tm) Processor 8354 16 of 16 cores online
ARM_Cortex_A9__Toshiba_AC100: ARM_Cortex_A9__Toshiba_AC100 2 of 2 cores online
C2Q_E6600: Intel® Core(TM)2 Quad CPU Q6600 @ 2.40GHz 4 of 4 cores online
E8400: Intel® Core(TM)2 Duo CPU E8400 @ 3.00GHz 2 of 2 cores online
i5-700: CPU model name: Intel® Core(TM) i5 CPU 760 @ 2.80GHz 4 of 4 cores online
P8600: Intel® Core(TM)2 Duo CPU P8600 @ 2.40GHz 2 of 2 cores online
Q8200-1core: Intel® Core(TM)2 Quad CPU Q8200 @ 2.33GHz 1 of 4 cores online
XeonE5520: Intel® Xeon® CPU E5520 @ 2.27GHz 8 of 8 cores online
Матриалы предоставлены пользователями
gribozavrVassgelas
и еще один пользователь, хабраник которого я не знаю.
Огромное им спасибо и 10000 плюсов к карме.
Графики отдельных серверов можно посмотреть на гитхабе. Добавил туда, также скрипты автогенерации графиков. Комитты результатов все ещё приветствуются.
12-и и 80-и ядерных процессоров, пока нет.
Спасибо и удач.
Расшифровка:
2xE5345: Intel® Xeon® CPU E5345 @ 2.33GHz 8 of 8 cores online
2xOpteron2220: Dual-Core AMD Opteron(tm) Processor 2220 4 of 4 cores online
4xOpteron6136: AMD Opteron(tm) Processor 6136 32 of 32 cores online
4xOpteron8354: Quad-Core AMD Opteron(tm) Processor 8354 16 of 16 cores online
ARM_Cortex_A9__Toshiba_AC100: ARM_Cortex_A9__Toshiba_AC100 2 of 2 cores online
C2Q_E6600: Intel® Core(TM)2 Quad CPU Q6600 @ 2.40GHz 4 of 4 cores online
E8400: Intel® Core(TM)2 Duo CPU E8400 @ 3.00GHz 2 of 2 cores online
i5-700: CPU model name: Intel® Core(TM) i5 CPU 760 @ 2.80GHz 4 of 4 cores online
P8600: Intel® Core(TM)2 Duo CPU P8600 @ 2.40GHz 2 of 2 cores online
Q8200-1core: Intel® Core(TM)2 Quad CPU Q8200 @ 2.33GHz 1 of 4 cores online
XeonE5520: Intel® Xeon® CPU E5520 @ 2.27GHz 8 of 8 cores online
Матриалы предоставлены пользователями
gribozavrVassgelas
и еще один пользователь, хабраник которого я не знаю.
Огромное им спасибо и 10000 плюсов к карме.
Графики отдельных серверов можно посмотреть на гитхабе. Добавил туда, также скрипты автогенерации графиков. Комитты результатов все ещё приветствуются.
12-и и 80-и ядерных процессоров, пока нет.
Спасибо и удач.
Ох-хо-хо. Ну какая польза от таких табличек? Нужно сделать не по методам синхронизации, а по процессорам, чтобы видеть, как они себя ведут. Возможно ли это?
Можно, и это сделано — но уж слишком много изображений, поэтому здесь их выкладывать не стал — оставил вместе с исходниками
Могу все вывалить :)
Вот парочка интересных:

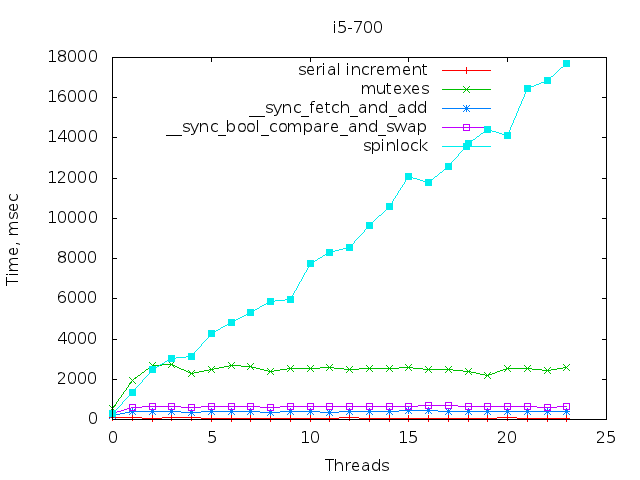
Могу все вывалить :)
Вот парочка интересных:
У оперонов несколько необычные конфигурации получились, но сходные. Т.е. опять же случайно так не получится. Явно видны особые точки, одновременно для нескольких механизмов:

Sign up to leave a comment.
mutex,spinlock,buslock. Накладные расходы