Комментарии 23
То, что должно было быть упомянуто — результат чувствителен не к шуму, а к начальному выбору центров.
Да и кнему тоже.Про шум я имел ввиду то, что например при том же вычитании фона, некоторые точки из-за шума исходных изображений могут детектироваться как движущийся, а если они находиться на существенном расстоянии от кластера то граница того же кластера может сушественно исказиться.
Вы правы, чувствительность к шуму — главная «болезнь» k-means. По схожему принципу работает алгоритм k-medoids, но он менее чувствителен к шумам поскольку как центр кластера использует один из объектов кластера, а не некоторый «центр масс».
ну и то, что зачастую это неплохо «лечится» случайным выбором изначальных центров + запуском пакетом (batch), т.е. несколько раз подряд с последующим усреднением результата
А если будет две одинаковые машины, он будет считать их одной?
Странно слышать рассказ об алгоритме кластеризации, с «примерами», нарисованными ручками. На них же ничего не видно. Интереснее смотреть когда есть картинка, которую кластеризуют. А тут сухой пересказ классического алгоритма и немного кода. Не видно ни на что алгоритм способен, ни его минусов.
P.S.
А, это первый пост автора. Тогда плюс. Но в будущем пишите более развернуто, с нормальными примерами.
P.S.
А, это первый пост автора. Тогда плюс. Но в будущем пишите более развернуто, с нормальными примерами.
Да, с картинками нехрошо вышло, т.к с самой программой, которая выделяет движущиеся объекты, возникли пролемы.Пришлось ручками, хотя результат, впринципе, должен получиться приблизительно такой.
А каким алгоритмом движущиеся объекты выделяли?
В случае использования только значений RGB результат будет совсем не таким. Как минимум, наравне с синей и красной машинами в отдельный кластер будут отнесены зеленая трава и серый асфальт. Приведу пример применения алгоритма K-средних для изображения, взятого из книги Bishop, «Pattern recognition and machine learning»:

Если же использовать вместе со значениями RGB еще и координаты самой точки (как предлагает автор), то возникает вопрос соотношения и нормировки этих величин: может сложиться ситуация, когда разница в расположении точек вносит намного бОльший вес в «расстояние» (которое считается как корень из суммы квадратов разницы соответствующих значений), нежели разница в цвете, либо наоборот. К примеру, для изображения 1000х1000 px максимальная разница координат точек (x и y) составляет 1000, тогда как разница в значении красного, зеленого и синего цветов не больше 255.
Если же использовать вместе со значениями RGB еще и координаты самой точки (как предлагает автор), то возникает вопрос соотношения и нормировки этих величин: может сложиться ситуация, когда разница в расположении точек вносит намного бОльший вес в «расстояние» (которое считается как корень из суммы квадратов разницы соответствующих значений), нежели разница в цвете, либо наоборот. К примеру, для изображения 1000х1000 px максимальная разница координат точек (x и y) составляет 1000, тогда как разница в значении красного, зеленого и синего цветов не больше 255.
Вы несколько все усложняете, в данном случае трава и асфальт никогда не попадут в кластер т.к они вообще не участвуют в кластеризации. В данном посте рассматривался тот случай, когда после метода вычитания фона все объекты кроме движущихся отсекаются, и в вектор кластеризируемых точек попадают только точки двух машин.
(надо обновлять комментарии, да)Как минимум, наравне с синей и красной машинами в отдельный кластер будут отнесены зеленая трава и серый асфальт.Как я понял, они же «пропадают» при вычитании фона, то есть их пиксели в принципе не доходят до этапа кластеризации.
А про соотношение цвета/сдвига координат — можно привести всё к значениям на [0;1] и уже там шаманить с весами, не будет хотя бы зависимости от размера картинки.
А как всё это собственно запустить, т.е. как вызвать метод Start?
Создать сколько надо кластеров и во все записать цвета пикселей или как-то по другому?
Спасибо
Создать сколько надо кластеров и во все записать цвета пикселей или как-то по другому?
Спасибо
А почему этот алгоритм не реагирует на тень? Она ведь не меняется и движется с той же скоростью
Ну по идее он должен на нее реагировать, а для отсечения теней применяются другие методы. Еще при выделении движущихся объектов можно перейти из RGB в YUV или HSV. Там теням будут соответствовать изменения в данном месте компоненты яркости практически без изменений цветовых компонент. Ну и так далее.
В тиории ее надо отфильтровать перед тем как подавать в алгоритм
Координаты нового центроида можно найти описав вокруг пикселей кластера прямоугольник и тогда центроидом будет пересечение его диагоналей.
А почему не найти среднее арифметическое координат пикселей кластера для определения координат центроида?
Можно конечно и так, но в посте рассматривался именно прямоугольник для большей наглядности.
Наглядность наглядностью, конечно, но центр масс-таки и нагляднее центра некого описывающего прямоугольника, да и корректнее, имхо.
Вот, например, в таком случае:
Центр прямоугольника даст точку A, тогда как реально стоило бы брать нечто ближе к точке B. Суть же в том, чтобы взять точку, «хорошо приближающую» точки текущего кластера.
Вот, например, в таком случае:
Скрытый текст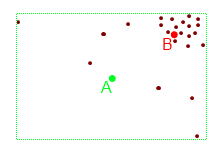
Центр прямоугольника даст точку A, тогда как реально стоило бы брать нечто ближе к точке B. Суть же в том, чтобы взять точку, «хорошо приближающую» точки текущего кластера.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Простейшая кластеризация изображени методом к-средних (k-means)