На Хабре уже как минимум дважды упоминался новый отечественный стандарт блочного шифрования ГОСТ Р 34.12 2015 «Кузнечик», ru_crypt в своем посте рассмотрел основные механизмы и преобразования нового стандарта, а sebastian_mg занимался пошаговой трассировкой базового преобразования. Но многие вопросы остались без ответа. Насколько быстр новый ГОСТ? Можно ли его оптимизировать, эффективно реализовать, ускорить аппаратно?

О стандарте ГОСТ Р 34.12 '15
Приказом от 19 июня 2015 года №749 в качестве нового стандарта блочного шифрования утвержден ГОСТ Р 34.12 2015. Стандарт разработан Центром защиты информации и специальной связи ФСБ России с участием ОАО «ИнфоТеКС», внесен Техническим комитетом по стандартизации ТК 26 «Криптографическая защита информации», и вступил в действие с 1 января 2016 года.
Официальное pdf-издание стандарта качаем здесь, а эталонную реализацию — здесь (обе ссылки ведут на официальный сайт ТК 26).
Этот стандарт содержит описания двух блочных шифров: «Магмы» с длиной блока в 64 бита и «Кузнечика» с длиной блока в 128 бит; при этом «Магма» — всего лишь новое название для старого, всем хорошо известного блочного шифра ГОСТ 28147 '89 (на самом деле, не совсем новое, именно под этим кодовым названием разрабатывался прежний стандарт блочного шифрования вплоть до 1994 года) с зафиксированными узлами замены. «Наконец–то, история нас чему–то научила», — скажете вы, и будете правы.
В этой статье пойдет речь про другой шифр, имеющий длину блока 128 бит, и носящий кодовое имя «Кузнечик». По городской ленде, имя шифра вовсе не связано с зеленым насекомым, а образовано первыми слогами фамилий авторов этого шифра: Кузьмин, Нечаев и компания.
Описание «Кузнечика»
Отличия «Кузнечика» от «Магмы»
Новый шифр существенно отличается от старого, среди его основных достоинств можно выделить
- вдвое увеличенную длину блока (128 бит, или 16 байт, против
64 бит, или 8 байт), - нетривиальное ключевое расписание (сеть Фейстеля как ключевое расписание против
использования частей секретного ключа в качестве цикловых ключей), - сокращенное число циклов (10 циклов против
32 циклов), - принципиально иное устройство самого шифра (LSX-шифр против
сети Фейстеля).
Базовое преобразование
Шифр принадлежит к классу LSX-шифров: его базовое преобразование (функция шифрования блока) представляется десятью циклами последовательных преобразований L (линейное преобразование), S (подстановка) и X (смешивание с цикловым ключом):
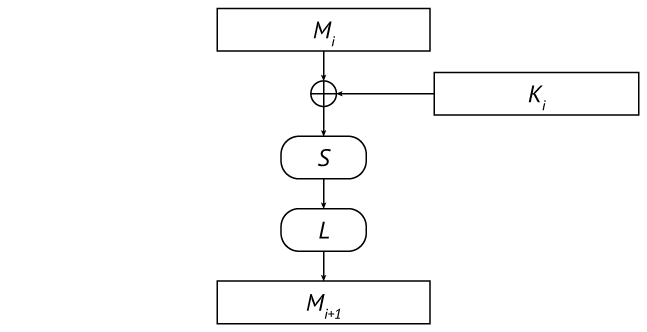
Полный цикл базового преобразования
Алгебраически шифртекст C зависит от открытого текста P следующим образом:
то есть за девятью полными циклами следует последний неполный (только смешивание с ключом). Преобразование X смешивает промежуточный текст очередного цикла с соответствующим цикловым ключом простым сложением по модулю 2:
Преобразование S применяет одну и ту же фиксированную подстановку к каждому байту промежуточного текста:
Преобразование L представимо линейной формой над полем GF(256), построенным с помощью неприводимого многочлена
и сводится к умножению вектора–строки промежуточного текста на некоторую матрицу над этим полем (каждый байт текста и матрицы является многочленом поля, представленным своими коэффициентами):
/* Применяет S-преобразование к блоку. */ static void applySTransformation( uint8_t *block ) { for (int byteIndex = 0; byteIndex < BlockLengthInBytes; byteIndex += 8) { block[byteIndex + 0] = Pi[block[byteIndex + 0]]; block[byteIndex + 1] = Pi[block[byteIndex + 1]]; block[byteIndex + 2] = Pi[block[byteIndex + 2]]; block[byteIndex + 3] = Pi[block[byteIndex + 3]]; block[byteIndex + 4] = Pi[block[byteIndex + 4]]; block[byteIndex + 5] = Pi[block[byteIndex + 5]]; block[byteIndex + 6] = Pi[block[byteIndex + 6]]; block[byteIndex + 7] = Pi[block[byteIndex + 7]]; } } /* Применяет L-преобразование к блоку. */ static void applyLTransformation( const uint8_t *input, uint8_t *output ) { for (int byteIndex = 0; byteIndex < BlockLengthInBytes; ++byteIndex) { uint8_t cache = 0; for (int addendIndex = 0; addendIndex < BlockLengthInBytes; ++addendIndex) { cache ^= multiplyInGF256(LTransformationMatrix[addendIndex][byteIndex], input[addendIndex]); } output[byteIndex] = cache; } } /* Полный цикл шифрования блока. */ static void applyXSLTransformation( const uint8_t *key, uint8_t *block, uint8_t *temporary ) { applyXTransformation(key, block, temporary); applySTransformation(temporary); applyLTransformation(temporary, block); } /* Базовое преобразование (шифрование блока). */ void encryptBlock( uint8_t *restrict block, const uint8_t *restrict roundKeys ) { uint8_t cache[BlockLengthInBytes] = {0}; int round = 0; for (; round < NumberOfRounds - 1; ++round) { applyXSLTransformation(&roundKeys[BlockLengthInBytes * round], block, cache); } applyXTransformation(&roundKeys[BlockLengthInBytes * round], block, block); }
/* Матрица преобразования L. */ const uint8_t LTransformationMatrix[16][16] = { 0xcf, 0x6e, 0xa2, 0x76, 0x72, 0x6c, 0x48, 0x7a, 0xb8, 0x5d, 0x27, 0xbd, 0x10, 0xdd, 0x84, 0x94, 0x98, 0x20, 0xc8, 0x33, 0xf2, 0x76, 0xd5, 0xe6, 0x49, 0xd4, 0x9f, 0x95, 0xe9, 0x99, 0x2d, 0x20, 0x74, 0xc6, 0x87, 0x10, 0x6b, 0xec, 0x62, 0x4e, 0x87, 0xb8, 0xbe, 0x5e, 0xd0, 0x75, 0x74, 0x85, 0xbf, 0xda, 0x70, 0x0c, 0xca, 0x0c, 0x17, 0x1a, 0x14, 0x2f, 0x68, 0x30, 0xd9, 0xca, 0x96, 0x10, 0x93, 0x90, 0x68, 0x1c, 0x20, 0xc5, 0x06, 0xbb, 0xcb, 0x8d, 0x1a, 0xe9, 0xf3, 0x97, 0x5d, 0xc2, 0x8e, 0x48, 0x43, 0x11, 0xeb, 0xbc, 0x2d, 0x2e, 0x8d, 0x12, 0x7c, 0x60, 0x94, 0x44, 0x77, 0xc0, 0xf2, 0x89, 0x1c, 0xd6, 0x02, 0xaf, 0xc4, 0xf1, 0xab, 0xee, 0xad, 0xbf, 0x3d, 0x5a, 0x6f, 0x01, 0xf3, 0x9c, 0x2b, 0x6a, 0xa4, 0x6e, 0xe7, 0xbe, 0x49, 0xf6, 0xc9, 0x10, 0xaf, 0xe0, 0xde, 0xfb, 0x0a, 0xc1, 0xa1, 0xa6, 0x8d, 0xa3, 0xd5, 0xd4, 0x09, 0x08, 0x84, 0xef, 0x7b, 0x30, 0x54, 0x01, 0xbf, 0x64, 0x63, 0xd7, 0xd4, 0xe1, 0xeb, 0xaf, 0x6c, 0x54, 0x2f, 0x39, 0xff, 0xa6, 0xb4, 0xc0, 0xf6, 0xb8, 0x30, 0xf6, 0xc4, 0x90, 0x99, 0x37, 0x2a, 0x0f, 0xeb, 0xec, 0x64, 0x31, 0x8d, 0xc2, 0xa9, 0x2d, 0x6b, 0x49, 0x01, 0x58, 0x78, 0xb1, 0x01, 0xf3, 0xfe, 0x91, 0x91, 0xd3, 0xd1, 0x10, 0xea, 0x86, 0x9f, 0x07, 0x65, 0x0e, 0x52, 0xd4, 0x60, 0x98, 0xc6, 0x7f, 0x52, 0xdf, 0x44, 0x85, 0x8e, 0x44, 0x30, 0x14, 0xdd, 0x02, 0xf5, 0x2a, 0x8e, 0xc8, 0x48, 0x48, 0xf8, 0x48, 0x3c, 0x20, 0x4d, 0xd0, 0xe3, 0xe8, 0x4c, 0xc3, 0x16, 0x6e, 0x4b, 0x7f, 0xa2, 0x89, 0x0d, 0x64, 0xa5, 0x94, 0x6e, 0xa2, 0x76, 0x72, 0x6c, 0x48, 0x7a, 0xb8, 0x5d, 0x27, 0xbd, 0x10, 0xdd, 0x84, 0x94, 0x01, }; /* Матрица, обратная к матрице преобразования L. */ const uint8_t inversedLTransformationMatrix[16][16] = { 0x01, 0x94, 0x84, 0xdd, 0x10, 0xbd, 0x27, 0x5d, 0xb8, 0x7a, 0x48, 0x6c, 0x72, 0x76, 0xa2, 0x6e, 0x94, 0xa5, 0x64, 0x0d, 0x89, 0xa2, 0x7f, 0x4b, 0x6e, 0x16, 0xc3, 0x4c, 0xe8, 0xe3, 0xd0, 0x4d, 0x20, 0x3c, 0x48, 0xf8, 0x48, 0x48, 0xc8, 0x8e, 0x2a, 0xf5, 0x02, 0xdd, 0x14, 0x30, 0x44, 0x8e, 0x85, 0x44, 0xdf, 0x52, 0x7f, 0xc6, 0x98, 0x60, 0xd4, 0x52, 0x0e, 0x65, 0x07, 0x9f, 0x86, 0xea, 0x10, 0xd1, 0xd3, 0x91, 0x91, 0xfe, 0xf3, 0x01, 0xb1, 0x78, 0x58, 0x01, 0x49, 0x6b, 0x2d, 0xa9, 0xc2, 0x8d, 0x31, 0x64, 0xec, 0xeb, 0x0f, 0x2a, 0x37, 0x99, 0x90, 0xc4, 0xf6, 0x30, 0xb8, 0xf6, 0xc0, 0xb4, 0xa6, 0xff, 0x39, 0x2f, 0x54, 0x6c, 0xaf, 0xeb, 0xe1, 0xd4, 0xd7, 0x63, 0x64, 0xbf, 0x01, 0x54, 0x30, 0x7b, 0xef, 0x84, 0x08, 0x09, 0xd4, 0xd5, 0xa3, 0x8d, 0xa6, 0xa1, 0xc1, 0x0a, 0xfb, 0xde, 0xe0, 0xaf, 0x10, 0xc9, 0xf6, 0x49, 0xbe, 0xe7, 0x6e, 0xa4, 0x6a, 0x2b, 0x9c, 0xf3, 0x01, 0x6f, 0x5a, 0x3d, 0xbf, 0xad, 0xee, 0xab, 0xf1, 0xc4, 0xaf, 0x02, 0xd6, 0x1c, 0x89, 0xf2, 0xc0, 0x77, 0x44, 0x94, 0x60, 0x7c, 0x12, 0x8d, 0x2e, 0x2d, 0xbc, 0xeb, 0x11, 0x43, 0x48, 0x8e, 0xc2, 0x5d, 0x97, 0xf3, 0xe9, 0x1a, 0x8d, 0xcb, 0xbb, 0x06, 0xc5, 0x20, 0x1c, 0x68, 0x90, 0x93, 0x10, 0x96, 0xca, 0xd9, 0x30, 0x68, 0x2f, 0x14, 0x1a, 0x17, 0x0c, 0xca, 0x0c, 0x70, 0xda, 0xbf, 0x85, 0x74, 0x75, 0xd0, 0x5e, 0xbe, 0xb8, 0x87, 0x4e, 0x62, 0xec, 0x6b, 0x10, 0x87, 0xc6, 0x74, 0x20, 0x2d, 0x99, 0xe9, 0x95, 0x9f, 0xd4, 0x49, 0xe6, 0xd5, 0x76, 0xf2, 0x33, 0xc8, 0x20, 0x98, 0x94, 0x84, 0xdd, 0x10, 0xbd, 0x27, 0x5d, 0xb8, 0x7a, 0x48, 0x6c, 0x72, 0x76, 0xa2, 0x6e, 0xcf, };
Ключевое расписание
Действительно, многие ошибки, допущенные при разработке старшего шифра, были исправлены, в том числе уязвимое ключевое расписание. Напомню читателю, что в шифре ГОСТ 28147 '89 в качестве цикловых ключей использовались восемь 32-битных частей 256-битного секретного ключа в прямом порядке на циклах шифрования с первого по восьмой, с девятого по шестнадцатый, с семнадцатого по двадцать четвертый; и в обратном порядке на циклах с двадцать пятого по тридцать второй:
И именно такое слабое ключевое расписание позволило осуществить атаку с отражением на полный ГОСТ, снизив его стойкость с 256 бит до 225 бит (при любых узлах замены, с 2^32 материала на одном ключе; почитать про эту атаку можно здесь).
В новом стандарте выработка цикловых ключей осуществляется по схеме Фейстеля, при этом первыми двумя цикловыми ключами являются половины 256-битного секретного ключа, а каждая следующая пара цикловых ключей получается в результате применения восьми циклов преобразования Фейстеля к предыдущей паре цикловых ключей, где в качестве цикловой функции используется то же LSX преобразование, что и в базовом преобразовании, а в качестве цикловых ключей в схеме используется фиксированный набор констант:
/* Вырабатывает цикловые ключи для шифрования по ГОСТ Р 34.12 '15. */ static void scheduleRoundKeys( uint8_t *restrict roundKeys, const void *restrict key, uint8_t *restrict memory ) { /* Копирование первой пары цикловых ключей. */ memcpy(&roundKeys[0], key, BlockLengthInBytes * 2); for (int nextKeyIndex = 2, constantIndex = 0; nextKeyIndex != NumberOfRounds; nextKeyIndex += 2) { /* Копирование предыдущей пары цикловых ключей. */ memcpy(&roundKeys[BlockLengthInBytes * (nextKeyIndex)], &roundKeys[BlockLengthInBytes * (nextKeyIndex - 2)], BlockLengthInBytes * 2); /* Применение преобразований Фейстеля. */ for (int feistelRoundIndex = 0; feistelRoundIndex < NumberOfRoundsInKeySchedule; ++feistelRoundIndex) { applyFTransformation(&roundConstants[BlockLengthInBytes * constantIndex++], &roundKeys[BlockLengthInBytes * (nextKeyIndex)], &roundKeys[BlockLengthInBytes * (nextKeyIndex + 1)], &memory[0], &memory[BlockLengthInBytes]); } } }
Примечания
256 бит вспомогательной памяти для циклового преобразования здесь передаются по указателю memory, но их можно выделять и на стеке.
Явная индексация массива с цикловыми ключами roundKeys произведена для наглядности и простоты, и может быть легко заменена на арифметику указателей.
Функция applyFTransformation применяет цикловое преобразование к полублокам схемы и производит своп этих полублоков, например, так:
/* Применяет цикловое преобразование схемы Фейстеля ключевого расписания. */ static void applyFTransformation( const uint8_t *restrict key, uint8_t *restrict left, uint8_t *restrict right, uint8_t *restrict temporary1, uint8_t *restrict temporary2 ) { memcpy(temporary1, left, BlockLengthInBytes); applyXSLTransformation(key, temporary1, temporary2); applyXTransformation(temporary1, right, right); swapBlocks(left, right, temporary2); }
const uint8_t roundConstants[512] = { 0x6e, 0xa2, 0x76, 0x72, 0x6c, 0x48, 0x7a, 0xb8, 0x5d, 0x27, 0xbd, 0x10, 0xdd, 0x84, 0x94, 0x01, 0xdc, 0x87, 0xec, 0xe4, 0xd8, 0x90, 0xf4, 0xb3, 0xba, 0x4e, 0xb9, 0x20, 0x79, 0xcb, 0xeb, 0x02, 0xb2, 0x25, 0x9a, 0x96, 0xb4, 0xd8, 0x8e, 0x0b, 0xe7, 0x69, 0x04, 0x30, 0xa4, 0x4f, 0x7f, 0x03, 0x7b, 0xcd, 0x1b, 0x0b, 0x73, 0xe3, 0x2b, 0xa5, 0xb7, 0x9c, 0xb1, 0x40, 0xf2, 0x55, 0x15, 0x04, 0x15, 0x6f, 0x6d, 0x79, 0x1f, 0xab, 0x51, 0x1d, 0xea, 0xbb, 0x0c, 0x50, 0x2f, 0xd1, 0x81, 0x05, 0xa7, 0x4a, 0xf7, 0xef, 0xab, 0x73, 0xdf, 0x16, 0x0d, 0xd2, 0x08, 0x60, 0x8b, 0x9e, 0xfe, 0x06, 0xc9, 0xe8, 0x81, 0x9d, 0xc7, 0x3b, 0xa5, 0xae, 0x50, 0xf5, 0xb5, 0x70, 0x56, 0x1a, 0x6a, 0x07, 0xf6, 0x59, 0x36, 0x16, 0xe6, 0x05, 0x56, 0x89, 0xad, 0xfb, 0xa1, 0x80, 0x27, 0xaa, 0x2a, 0x08, 0x98, 0xfb, 0x40, 0x64, 0x8a, 0x4d, 0x2c, 0x31, 0xf0, 0xdc, 0x1c, 0x90, 0xfa, 0x2e, 0xbe, 0x09, 0x2a, 0xde, 0xda, 0xf2, 0x3e, 0x95, 0xa2, 0x3a, 0x17, 0xb5, 0x18, 0xa0, 0x5e, 0x61, 0xc1, 0x0a, 0x44, 0x7c, 0xac, 0x80, 0x52, 0xdd, 0xd8, 0x82, 0x4a, 0x92, 0xa5, 0xb0, 0x83, 0xe5, 0x55, 0x0b, 0x8d, 0x94, 0x2d, 0x1d, 0x95, 0xe6, 0x7d, 0x2c, 0x1a, 0x67, 0x10, 0xc0, 0xd5, 0xff, 0x3f, 0x0c, 0xe3, 0x36, 0x5b, 0x6f, 0xf9, 0xae, 0x07, 0x94, 0x47, 0x40, 0xad, 0xd0, 0x08, 0x7b, 0xab, 0x0d, 0x51, 0x13, 0xc1, 0xf9, 0x4d, 0x76, 0x89, 0x9f, 0xa0, 0x29, 0xa9, 0xe0, 0xac, 0x34, 0xd4, 0x0e, 0x3f, 0xb1, 0xb7, 0x8b, 0x21, 0x3e, 0xf3, 0x27, 0xfd, 0x0e, 0x14, 0xf0, 0x71, 0xb0, 0x40, 0x0f, 0x2f, 0xb2, 0x6c, 0x2c, 0x0f, 0x0a, 0xac, 0xd1, 0x99, 0x35, 0x81, 0xc3, 0x4e, 0x97, 0x54, 0x10, 0x41, 0x10, 0x1a, 0x5e, 0x63, 0x42, 0xd6, 0x69, 0xc4, 0x12, 0x3c, 0xd3, 0x93, 0x13, 0xc0, 0x11, 0xf3, 0x35, 0x80, 0xc8, 0xd7, 0x9a, 0x58, 0x62, 0x23, 0x7b, 0x38, 0xe3, 0x37, 0x5c, 0xbf, 0x12, 0x9d, 0x97, 0xf6, 0xba, 0xbb, 0xd2, 0x22, 0xda, 0x7e, 0x5c, 0x85, 0xf3, 0xea, 0xd8, 0x2b, 0x13, 0x54, 0x7f, 0x77, 0x27, 0x7c, 0xe9, 0x87, 0x74, 0x2e, 0xa9, 0x30, 0x83, 0xbc, 0xc2, 0x41, 0x14, 0x3a, 0xdd, 0x01, 0x55, 0x10, 0xa1, 0xfd, 0xcc, 0x73, 0x8e, 0x8d, 0x93, 0x61, 0x46, 0xd5, 0x15, 0x88, 0xf8, 0x9b, 0xc3, 0xa4, 0x79, 0x73, 0xc7, 0x94, 0xe7, 0x89, 0xa3, 0xc5, 0x09, 0xaa, 0x16, 0xe6, 0x5a, 0xed, 0xb1, 0xc8, 0x31, 0x09, 0x7f, 0xc9, 0xc0, 0x34, 0xb3, 0x18, 0x8d, 0x3e, 0x17, 0xd9, 0xeb, 0x5a, 0x3a, 0xe9, 0x0f, 0xfa, 0x58, 0x34, 0xce, 0x20, 0x43, 0x69, 0x3d, 0x7e, 0x18, 0xb7, 0x49, 0x2c, 0x48, 0x85, 0x47, 0x80, 0xe0, 0x69, 0xe9, 0x9d, 0x53, 0xb4, 0xb9, 0xea, 0x19, 0x05, 0x6c, 0xb6, 0xde, 0x31, 0x9f, 0x0e, 0xeb, 0x8e, 0x80, 0x99, 0x63, 0x10, 0xf6, 0x95, 0x1a, 0x6b, 0xce, 0xc0, 0xac, 0x5d, 0xd7, 0x74, 0x53, 0xd3, 0xa7, 0x24, 0x73, 0xcd, 0x72, 0x01, 0x1b, 0xa2, 0x26, 0x41, 0x31, 0x9a, 0xec, 0xd1, 0xfd, 0x83, 0x52, 0x91, 0x03, 0x9b, 0x68, 0x6b, 0x1c, 0xcc, 0x84, 0x37, 0x43, 0xf6, 0xa4, 0xab, 0x45, 0xde, 0x75, 0x2c, 0x13, 0x46, 0xec, 0xff, 0x1d, 0x7e, 0xa1, 0xad, 0xd5, 0x42, 0x7c, 0x25, 0x4e, 0x39, 0x1c, 0x28, 0x23, 0xe2, 0xa3, 0x80, 0x1e, 0x10, 0x03, 0xdb, 0xa7, 0x2e, 0x34, 0x5f, 0xf6, 0x64, 0x3b, 0x95, 0x33, 0x3f, 0x27, 0x14, 0x1f, 0x5e, 0xa7, 0xd8, 0x58, 0x1e, 0x14, 0x9b, 0x61, 0xf1, 0x6a, 0xc1, 0x45, 0x9c, 0xed, 0xa8, 0x20, };
Устройство узла замены
В стандарте узел замены задан таблицей значений; разработчики шифра утверждают, что эта таблица получена в результате перебора случайных таблиц значений с учетом требований к линейным и разностным свойствам.
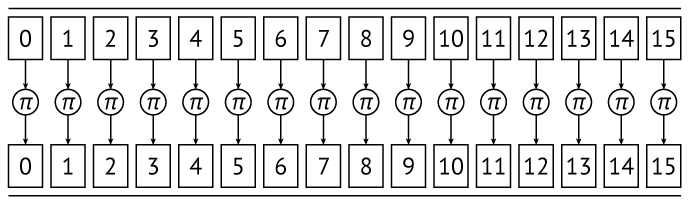
Слой подстановок, S-преобразование
/* Узел замены pi стандарта шифрования ГОСТ 34.12 Р 2015. */ const uint8_t Pi[256] = { 0xfc, 0xee, 0xdd, 0x11, 0xcf, 0x6e, 0x31, 0x16, 0xfb, 0xc4, 0xfa, 0xda, 0x23, 0xc5, 0x04, 0x4d, 0xe9, 0x77, 0xf0, 0xdb, 0x93, 0x2e, 0x99, 0xba, 0x17, 0x36, 0xf1, 0xbb, 0x14, 0xcd, 0x5f, 0xc1, 0xf9, 0x18, 0x65, 0x5a, 0xe2, 0x5c, 0xef, 0x21, 0x81, 0x1c, 0x3c, 0x42, 0x8b, 0x01, 0x8e, 0x4f, 0x05, 0x84, 0x02, 0xae, 0xe3, 0x6a, 0x8f, 0xa0, 0x06, 0x0b, 0xed, 0x98, 0x7f, 0xd4, 0xd3, 0x1f, 0xeb, 0x34, 0x2c, 0x51, 0xea, 0xc8, 0x48, 0xab, 0xf2, 0x2a, 0x68, 0xa2, 0xfd, 0x3a, 0xce, 0xcc, 0xb5, 0x70, 0x0e, 0x56, 0x08, 0x0c, 0x76, 0x12, 0xbf, 0x72, 0x13, 0x47, 0x9c, 0xb7, 0x5d, 0x87, 0x15, 0xa1, 0x96, 0x29, 0x10, 0x7b, 0x9a, 0xc7, 0xf3, 0x91, 0x78, 0x6f, 0x9d, 0x9e, 0xb2, 0xb1, 0x32, 0x75, 0x19, 0x3d, 0xff, 0x35, 0x8a, 0x7e, 0x6d, 0x54, 0xc6, 0x80, 0xc3, 0xbd, 0x0d, 0x57, 0xdf, 0xf5, 0x24, 0xa9, 0x3e, 0xa8, 0x43, 0xc9, 0xd7, 0x79, 0xd6, 0xf6, 0x7c, 0x22, 0xb9, 0x03, 0xe0, 0x0f, 0xec, 0xde, 0x7a, 0x94, 0xb0, 0xbc, 0xdc, 0xe8, 0x28, 0x50, 0x4e, 0x33, 0x0a, 0x4a, 0xa7, 0x97, 0x60, 0x73, 0x1e, 0x00, 0x62, 0x44, 0x1a, 0xb8, 0x38, 0x82, 0x64, 0x9f, 0x26, 0x41, 0xad, 0x45, 0x46, 0x92, 0x27, 0x5e, 0x55, 0x2f, 0x8c, 0xa3, 0xa5, 0x7d, 0x69, 0xd5, 0x95, 0x3b, 0x07, 0x58, 0xb3, 0x40, 0x86, 0xac, 0x1d, 0xf7, 0x30, 0x37, 0x6b, 0xe4, 0x88, 0xd9, 0xe7, 0x89, 0xe1, 0x1b, 0x83, 0x49, 0x4c, 0x3f, 0xf8, 0xfe, 0x8d, 0x53, 0xaa, 0x90, 0xca, 0xd8, 0x85, 0x61, 0x20, 0x71, 0x67, 0xa4, 0x2d, 0x2b, 0x09, 0x5b, 0xcb, 0x9b, 0x25, 0xd0, 0xbe, 0xe5, 0x6c, 0x52, 0x59, 0xa6, 0x74, 0xd2, 0xe6, 0xf4, 0xb4, 0xc0, 0xd1, 0x66, 0xaf, 0xc2, 0x39, 0x4b, 0x63, 0xb6, }; /* Узел замены, обратный к pi, стандарта шифрования ГОСТ 34.12 Р 2015. */ const uint8_t InversedPi[256] = { 0xa5, 0x2d, 0x32, 0x8f, 0x0e, 0x30, 0x38, 0xc0, 0x54, 0xe6, 0x9e, 0x39, 0x55, 0x7e, 0x52, 0x91, 0x64, 0x03, 0x57, 0x5a, 0x1c, 0x60, 0x07, 0x18, 0x21, 0x72, 0xa8, 0xd1, 0x29, 0xc6, 0xa4, 0x3f, 0xe0, 0x27, 0x8d, 0x0c, 0x82, 0xea, 0xae, 0xb4, 0x9a, 0x63, 0x49, 0xe5, 0x42, 0xe4, 0x15, 0xb7, 0xc8, 0x06, 0x70, 0x9d, 0x41, 0x75, 0x19, 0xc9, 0xaa, 0xfc, 0x4d, 0xbf, 0x2a, 0x73, 0x84, 0xd5, 0xc3, 0xaf, 0x2b, 0x86, 0xa7, 0xb1, 0xb2, 0x5b, 0x46, 0xd3, 0x9f, 0xfd, 0xd4, 0x0f, 0x9c, 0x2f, 0x9b, 0x43, 0xef, 0xd9, 0x79, 0xb6, 0x53, 0x7f, 0xc1, 0xf0, 0x23, 0xe7, 0x25, 0x5e, 0xb5, 0x1e, 0xa2, 0xdf, 0xa6, 0xfe, 0xac, 0x22, 0xf9, 0xe2, 0x4a, 0xbc, 0x35, 0xca, 0xee, 0x78, 0x05, 0x6b, 0x51, 0xe1, 0x59, 0xa3, 0xf2, 0x71, 0x56, 0x11, 0x6a, 0x89, 0x94, 0x65, 0x8c, 0xbb, 0x77, 0x3c, 0x7b, 0x28, 0xab, 0xd2, 0x31, 0xde, 0xc4, 0x5f, 0xcc, 0xcf, 0x76, 0x2c, 0xb8, 0xd8, 0x2e, 0x36, 0xdb, 0x69, 0xb3, 0x14, 0x95, 0xbe, 0x62, 0xa1, 0x3b, 0x16, 0x66, 0xe9, 0x5c, 0x6c, 0x6d, 0xad, 0x37, 0x61, 0x4b, 0xb9, 0xe3, 0xba, 0xf1, 0xa0, 0x85, 0x83, 0xda, 0x47, 0xc5, 0xb0, 0x33, 0xfa, 0x96, 0x6f, 0x6e, 0xc2, 0xf6, 0x50, 0xff, 0x5d, 0xa9, 0x8e, 0x17, 0x1b, 0x97, 0x7d, 0xec, 0x58, 0xf7, 0x1f, 0xfb, 0x7c, 0x09, 0x0d, 0x7a, 0x67, 0x45, 0x87, 0xdc, 0xe8, 0x4f, 0x1d, 0x4e, 0x04, 0xeb, 0xf8, 0xf3, 0x3e, 0x3d, 0xbd, 0x8a, 0x88, 0xdd, 0xcd, 0x0b, 0x13, 0x98, 0x02, 0x93, 0x80, 0x90, 0xd0, 0x24, 0x34, 0xcb, 0xed, 0xf4, 0xce, 0x99, 0x10, 0x44, 0x40, 0x92, 0x3a, 0x01, 0x26, 0x12, 0x1a, 0x48, 0x68, 0xf5, 0x81, 0x8b, 0xc7, 0xd6, 0x20, 0x0a, 0x08, 0x00, 0x4c, 0xd7, 0x74, };
Однако, все тайное рано, или поздно, становится явным, и способ выбора узла замены не исключение. Команде криптографов из Люксембурга, возглавляемой Алексом Бирюковым, удалось обнаружить определенного рода закономерности в статистических характеристиках узла замены, что, в свою очередь, позволило им восстановить способ его получения. Подробнее об этом способе можно почитать в их статье, опубликованной на iacr.org.
Секретная структура узла замены
Алгоритмическая оптимизация
Команде исследователей из ОАО «ИнфоТеКС», а конкретно Михаилу Бородину и Андрею Рыбкину, удалось позаимствовать алгоритмическую оптимизацию умножения вектора на столбец у скоростных реализаций шифра AES (Rijndael), которая позволяет заменить классическую реализацию умножения за O(n^2) умножений в поле на O(n) сложений по модулю два векторов длины O(n) с использованием предвычисленных таблиц, и о которой было доложено на конференции РусКрипто, если мне не изменяет память, в 2014 году.
Вкратце, оптимизация заключается в следующем: допустим, в результате произведения некоторого вектора U
на матрицу A
получился вектор V:
Традиционный способ вычисления компонент этого вектора заключается в последовательном скалярном умножении строки вектора U на столбцы матрицы A:
Вычисление каждой из n компонент вектора V подразумевает n операций умножения в поле и n-1 операцию сложения по модулю 2, так трудоемкость вычисления всех компонент составляет O(n^2). Да, конечно, можно не умножать в поле каждый раз, можно заранее вычислить таблицы логарифма и экспоненты; можно даже заранее вычислить произведения всех возможных байт на элементы матрицы (матрица ведь фиксирована и не меняется в процессе шифрования), и хранить ~256 таблиц по 256 байт-произведений. В матрице есть одинаковые элементы? Отлично, число таблиц можно сократить, но асимптотическая сложность не изменится.
А можно пойти другим путем. Вместо того, чтобы вычислять каждую компоненту вектора-произведения как сумму n однобайтовых прозведений, воспользуемся особенностью умножения вектора на матрицу и будем вычислять сразу все компоненты вектора как сумму n векторов:
Казалось бы, что изменилось? Те же операции, но в другом порядке. Замечу, однако, что, во-первых, повысилась разрядность слагаемых с одного байта до n байт, и такие суммы можно (и нужно) вычислять в длинных регистрах, а, во-вторых, каждое слагаемое является покомпонентным произведением одного (!) байта вектора на фиксированную строку матрицу.
Вот здесь поподробнее: можно заранее вычислить произведения вида
то есть умножить известную строку i матрицы A на все возможные значения байта i вектора U, и вместо умножения очередного байта на эту строку просто считывать произведение из таблицы. Тогда умножение вектора на матрицу сводится к считыванию n строк-произведений из заранее вычисленной таблицы и побитовое сложение этих строк для получения результирующего вектора V. Вот так, достаточно просто, можно сильно упростить умножение вектора на матрицу до O(n), если сложение векторов считать элементарными операциями.
В случае ГОСТ Р 34.12 '15 n = 16, так, вектора имеют длины в 16 байт, или 128 бит, и очень здорово помещаются в длинные XMM регистры, а для их сложения предусмотрены дополнительные процессорные инструкции, например, pxor.
Все очень здорово, но как быть с узлом замены? Читатель наверняка заметит, что при наличии побайтовых узлов замены, которые в общем случае не векторизуются, все алгоритмические прелести такого вычисления L-преобразования нивелируются стоимостью загрузки векторов в регистры до преобразования и их выгрузки после преобразования. Хороший вопрос.
Хороший, и очень изящно решаемый. Оказывается, узлы замены можно просто «склеить» с L-преобразованием, заменив вычисляемые заранее строки произведения с
на
Тогда один полный цикл шифрования сводится к
- смешиванию с ключом (
pxor), - применению склеенного преобразования LS (в наилучшем случае это 16 загрузок 128-битных векторов из кэша и 15 сложений
pxor).
Конечно, такие оптимизации не бесплатны, для их использования потребуется, во-первых, вычислить и хранить в кэше единовременну одну из двух таблиц со строками-произведениями, каждая из которых содержит 256 * 16 * 16 байт, или 64 КБ. Почему таблиц две? Потому что обратное преобразование, используемое при расшифровании, потребует умножения на обратную к L матрицу, и повлечет за собой новые произведения.
Во-вторых, склеивание узлов замены с умножением на матрицу возможно только в том случае, если к блоку сначала применяют подстановку, а потом умножение, поэтому алгоритм расшифрования придется немного изменить. Открытый текст получается из шифртекста простым обращением всей схемы (все преобразования обратимы):
Заметим, что при расшифровании «в лоб» к промежуточному тексту сначала применяют умножение на обратную матрицу, а потом уже действие подстановкой, поэтому, чтобы склеить эти перобразования и тут, придется переупорядочить алгоритм расшифрования.
Замечу, что композиция преобразований
тождественна композиции
в силу линейности преобразования L. Тогда расшифрование можно осуществить следующим образом:
Здесь каждое из преобразований, обратных к SL, можно осуществлять по схеме, аналогичной к рассмотренной. Вычисленные таблицы строк-произведений постить не буду, — они слишком большие даже для спойлеров; их можно найти, например, здесь.
Оптимизация с использованием SSE2
В принципе, с базовыми преобразованиями все понятно, осталось все эти оптимизации положить на asm.
Для работы с блоками предлагаю использовать набор инструкций SSE2, будем использовать инструкции movdqu и movdqa для загрузки и выгрузки данных в регистры, инструкции pxor, pand, pandn для булевых операций, инструкции psrlw и psllw для побитовых сдвигов, pextrw для выгрузки байт регистра.
Да, есть еще одна тонкость реализации ГОСТ Р 34.12 '15. Кроме общеалгоритмических оптимизаций вроде описанных выше, для дальнейшего ускорения производительности нужно учитывать особенности ассемблера и особенности планировщика, который инструкции может поставить на параллельное исполнение на разных исполняющих устройствах.
Учет особенностей адресной арифметики
Первая особенность реализации алгоритма связана с тем, что, если не учитывать устройство предвычисленной таблицы и косвенной индексной адресации со смещением, то при компиляции можно получить примерно следующий выхлоп сложения с очередной строкой-произведением:
pextrb xmmX, eax, i ; выделение байта i (SSE 4.1) в 32--битный регистр eax movzxd rcx, eax ; перемещение выделенного байта в 64--битный регистр rcx add rcx, rcx ; удвоение значения байта pxor xmmY, [rbx + 8*rcx + 0xi000] ; вычисление смещения по таблице
В регистрах при этом хранятся:
rbxсодержит адрес базового смещения таблицы,xmmXсодержит входной блок,xmmYсодержит выходной блок (аккумулятор, сумму),eaxиrcxиспользуются для выделения и удвоения байта смещения.
Следует иметь в виду, что предвычисленная таблица устроена следующим образом:
uint8_t table[16][256][16],
то есть значения строк-произведений хранятся в этой таблице непрерывно, друг за другом, внешний индекс i соответствует i-ой строке матрице L-преобразования, средний индекс j равен i-ому байту входного блока, а внутренний индекс k соответствует индексу байта очередного слагаемого:
Xi = table[i][input[i]][0] ... [16]
Таким образом, адрес первого байта очередного слагаемого Xi выражается следующим образом:
[Xi] = rbx + (0x1000 * i) + (16 * input[i]),
где
(0x1000 * i)соответсвует смещению текущей строки (table[i]),(16 * input[i])соответсвует смещению текущего слагаемогоXi(table[i][input[i]]).
Так, значение текущего байта приходится умножать на 16, но адресная арифметика позволяет использовать максимальное значение коэффициента-множителя равное восьми. Поэтому компилятору приходится перекладывать значение байта в rcx, удваивать его, и только затем вычислять адрес Xi.
Для того, чтобы избежать подобных излишеств, можно воспользоваться идеологией SIMD, и вычислить приведенные смещения заранее, а не посредством адресной арифметики.
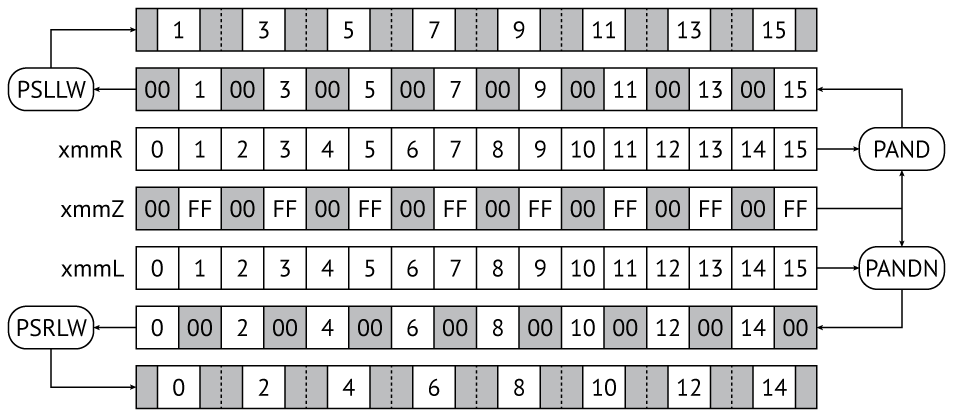
Предварительное вычисление приведенных смещений (слагаемые в адресе очередного Xi)
Здесь числами 0..15 обозначены соответствующие байты входного блока, а 00 и FF соответствуют нулевому байту и его инверсии.
С помощью маски 00FF 00FF 00FF 00FF 00FF 00FF 00FF 00FF и инструкций pand и pandn четные и нечетные байты входного блока выделяются в регистры левых и правых смещений соответственно; затем c помощью инструкций psrlw и psllw смещения приводятся (домножаются на 16) к значениям, пригодным для использования в адресной арифметике.
Так, каждое L-преобразование дополняется следующими строками:
pand xmmR, xmmZ ; выделение правых смещений pandn xmmL, xmmZ ; выделение левых смещений psllw xmmR, 4 ; приведение правых смещений psrlw xmmL, 4 ; приведение левых смещений
и предварительной загрузкой маски в регистр xmmZ. Зато вычисление адресов слагаемых Xi теперь может быть осуществлено всего за две инструкции:
pextrw eax, i ; выделение приведенного смещения i pxor xmmY, [rbx + rax + 0xi000] ; вычисление смещения по таблице с помощью адресной арифметики
Учет специфики микроархитектуры
Большинство современных процессоров Intel и AMD имеют два, или более, исполняющих АЛУ, способных одновременно производить арифметические действия с различными регистрами, и планировщик, способный распределить блок выполняемых инструкций по различным АЛУ для параллельного выполнения с целью экономии процессорного времени.
Так, чередуя команды, использующие различные регистры, можно помочь процессору выполнять код параллельно. Склеенное LS-преобразование является двоичной суммой шестнадцати различных 128-битных чисел Xi, и, скорее всего, на современных процессорах может быть осуществлена в два параллельных потока (на одном ядре) с использованием двух аккумуляторов: левого и правого кэшей.
.code extern bitmask:xmmword extern precomputedLSTable:xmmword encrypt_block proc initialising: movdqu xmm0, [rcx] ; [unaligned] loading block lea r8, [precomputedLSTable + 01000h] ; [aligned] aliasing table base with offset lea r11, [precomputedLSTable] ; [aligned] aliasing table base movdqa xmm4, [bitmask] ; [aligned] loading bitmask mov r10d, 9 ; number of rounds, base 0 round: pxor xmm0, [rdx] ; [aligned] mixing with round key movaps xmm1, xmm4 ; securing bitmask from @xmm4 movaps xmm2, xmm4 ; securing bitmask from @xmm4 pand xmm2, xmm0 ; calculating offsets pandn xmm1, xmm0 psrlw xmm2, 4 psllw xmm1, 4 pextrw eax, xmm1, 0h ; accumulating caches movdqa xmm0, [r11 + rax + 00000h] pextrw eax, xmm2, 0h movdqa xmm3, [r8 + rax + 00000h] pextrw eax, xmm1, 1h pxor xmm0, [r11 + rax + 02000h] pextrw eax, xmm2, 1h pxor xmm3, [r8 + rax + 02000h] pextrw eax, xmm1, 2h pxor xmm0, [r11 + rax + 04000h] pextrw eax, xmm2, 2h pxor xmm3, [r8 + rax + 04000h] pextrw eax, xmm1, 3h pxor xmm0, [r11 + rax + 06000h] pextrw eax, xmm2, 3h pxor xmm3, [r8 + rax + 06000h] pextrw eax, xmm1, 4h pxor xmm0, [r11 + rax + 08000h] pextrw eax, xmm2, 4h pxor xmm3, [r8 + rax + 08000h] pextrw eax, xmm1, 5h pxor xmm0, [r11 + rax + 0a000h] pextrw eax, xmm2, 5h pxor xmm3, [r8 + rax + 0a000h] pextrw eax, xmm1, 6h pxor xmm0, [r11 + rax + 0c000h] pextrw eax, xmm2, 6h pxor xmm3, [r8 + rax + 0c000h] pextrw eax, xmm1, 7h pxor xmm0, [r11 + rax + 0e000h] pextrw eax, xmm2, 7h pxor xmm3, [r8 + rax + 0e000h] pxor xmm0, xmm3 ; mixing caches add rdx, 10h ; advancing to next round key dec r10 ; decrementing round index jnz round last_round: pxor xmm0, [rdx] ; [aligned] mixing with round key movdqu [rcx], xmm0 ; [unaligned] storing block ret encrypt_block endp end
Заключение
Все описанные техники ускорения базового преобразования позволяют существенно повысить производительность шифра; в качестве конкретного примера могу привести числа, полученные на одном ядре Intel Core i7-2677M Sandy Bridge @ 1.80 GHz, это 120 МБ/с в версии с SSE инструкциями против 1.3 МБ/с в неоптимизированной версии.
Дальше — больше, ГОСТу можно придать дополнительное ускорение:
- наличие регистров большей длины позволяет еще больше оптимизировать пакетное шифрование (только в режимах, которые допускают параллельную обработку блоков);
- теоретически, замена вычисления подстановки по таблице значений вычислением с использованием секретной структуры узла замены, может дать небольшой прирост производительности при расшифровании.
Поиграть с различными реализациями базового преобразования ГОСТ Р 34.12 '15 можно, собрав у себя этот проект. Написан он на C99, на совершенство кода и абсолютную оптимальность он не претендует, но автор будет рад любой конструктивной критике. Для сборки потребуется CMake 3.2.1+ и компилятор, поддерживающий C99. Шифр реализован в трех версиях, по стандарту без существенных оптимизаций (compact), с предвычислениями, но без SIMD инструкций (optimised) и с использованием инструкций SSE2 (SIMD).
Непосредственные шаги сборки можно посмотреть в скрипте Travis CI в корне проекта, в комплект входят модульные тесты на контрольные примеры из стандарта (ключевое расписание, шифрование и расшифрование блока) на CTest и примитивный способ измерять производительность с использованием std::chrono на C++11.

