Краткая предыстория: моя прошлая заметка описывала подход к хранению и выборке данных, на котором можно построить конструктор приложений — альтернативу современным платформам разработки, но без необходимости программирования. Изобретение это потенциально может перевернуть весь мир IT, каким мы его знаем.
Я провел патентный поиск и осветил результат публично, чтобы убедиться в отсутствии архитектурных аналогов. После чего получил патент и опубликовал статью с пояснениями, которая содержала несколько смелых замечаний насчет объемов, масштабируемости, быстродействия и прочего.
Разумеется, статья вызвала большое количество вопросов, которые необходимо осветить отдельно: отличие от существующих решений и сравнительный анализ производительности и планов построения запросов к базе данных. А также ответить на вопрос: что это вообще такое и зачем?

Поскольку тема для многих больная, а заявленные преимущества весьма амбициозны, комментарии были достаточно резкими. Причина понятна — в статье все сразу видят «EAV», о которой серьезные люди до сих пор пишут исследования, при этом проблема производительности в общем случае не разрешима. Как мне любезно сообщили в комментариях, EAV имеет кучу недостатков, это общеизвестно, и любой, кто заявляет об окончательном решении проблем EAV, должен получить щедрых пинков в карму, дабы образумился.
Есть только одна тонкость: в статье представлена не EAV как таковая
Самый популярный вопрос был: «чем это отличается от EAV, KV, Magento...».
Казалось бы, отличия заключаются во всем что не укладывается в перечисленные свойства:
- Структура — в таблице 5 колонок и 3 индекса
- Способ выборки — в одной таблице описываются типы данных и их взаимосвязи (мета-данные) и сами данные
Но такой ответ не устроил многих читателей, поэтому постараюсь объяснить более развернуто.
Описанная структура использует справочник EAV, дополненный атрибутом ID, так как любой атрибут также является самостоятельной сущностью, могущей иметь свои атрибуты, равно как и использоваться в качестве справочного значения. То есть, структура предназначена не только как EAV-справочник, почему, собственно, я и не могу назвать это EAV.
Самое главное, EAV не может быть самодостаточным решением, это всего лишь справочник, один из элементов системы. Я же рассказываю о законченном, самодостаточном решении, которе не требует ничего дополнительного для создания структуры, данных и управления ими.
Чтобы объяснить, чем решение отличается от Datomic, Magento и десятков тысяч других решений и продуктов, понадобится десятки тысяч раз их сравнивать. Поэтому я рискну предложить простую методику, по которой за пару минут можно провести сравнение с любой системой и выявить разницу, если она есть.
Нужно проверить выполнение следующих условий для сравниваемой системы:
1. Все данные хранятся в одной таблице (см. также п.3.), содержащей как минимум следующие поля: ID, Parent ID, Type ID, Value
2. Для таблицы построены как минимум следующие индексы: ID; Type ID + Value; Parent ID + Type ID.
3. Таблиц может быть несколько, но все они содержат минимальную структуру из п.1 и индексы, различаясь типом поля Value
4. Таблица содержит описание типов данных
5. Таблица содержит описание реквизитов типов данных (из набора описанных в ней же типов)
6. Таблица содержит объекты данных с сылкой на их тип (из набора описанных в ней же типов)
7. Таблица содержит реквизиты объектов с сылкой на родителя и тип
8. Выборка объектов производится с обязательным указанием типа объекта
9. Выборка реквизитов объекта производится с обязательным указанием родителя и типа
10. Выборка объекта по его реквизитам производится с обязательным указанием типа реквизита
11. (необязательно) Объекты связаны через реквизиты, содержащие в качестве типа ID связываемого объекта
Если все обязательные условия выполнены, то перед вами система, попадающая под описание обсуждаемой здесь заметки.
Более существенные вопросы ставят под сомнение заявление о производительности системы с ростом объема
Для сравнительных тестов были сделаны две идентичные базы, одна из которых построена в обычных таблицах реляционной БД, а другая — с применением заявленной методики. Ниже приведены результаты тестов двух баз с текстами запросов, замерами времени и анализом планов выполнения.
В комментариях к прошлой заметке была предложена простая структура связанных данных, пригодная для тестирования. Её я и взял за основу: это список из 1048552 книг 142654 авторов, сгенерированных из случайных данных.
CREATE TABLE `author` ( `id` int(11) NOT NULL, `author` varchar(128) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `books` ( `id` int(8) NOT NULL, `name` varchar(256) NOT NULL, `author` int(8) NOT NULL, `pages` int(4) NOT NULL, `year` int(4) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; ALTER TABLE `author` ADD PRIMARY KEY (`id`), ADD KEY `author` (`author`); ALTER TABLE `books` ADD PRIMARY KEY (`id`), ADD KEY `name` (`name`(255)), ADD KEY `author` (`author`); ALTER TABLE `books` ADD CONSTRAINT `books_ibfk_1` FOREIGN KEY (`author`) REFERENCES `author` (`id`);
В конструкторе эта схема данных выглядит так:

Тестирование проводилось на самом простом сервере: 1 ядро @2.4GHz, 1GB RAM, диск SSD.
Базы с индексами занимают 207 МБ в классической базе данных и 289 МБ в таблице конструктора.

Конструктор
Для справедливости я буду делать серию запросов, поочередно в одной и другой базе, и замерять время.
Первый предложенный оппонентом тест выглядел так: выбрать все книги, имя авторов которых содержит заданный текст. Для подобного запроса не может быть использован индекс по имени автора.
Запрос к базе получился такой:
SELECT author.author, books.name, books.pages, books.year FROM books, author WHERE author.author LIKE '%aro%' AND books.author=author.id LIMIT 1000
Этот же запрос в конструкторе выглядит так (указан фильтр по автору и задано подсчитать их количество):
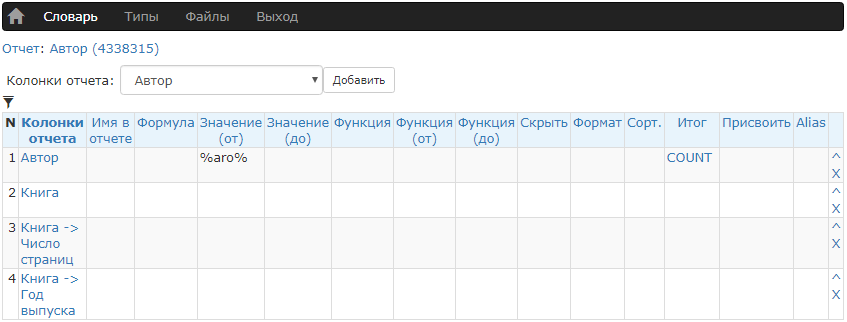
Имя автора содержит символы «aro», и под это условие попадает 465 книг в нашей базе.
Запрос к таблицам вернул такой результат за 193 мс:

План выполнения запроса получился такой:

Конструктор вернул тот же набор за 266 мс:
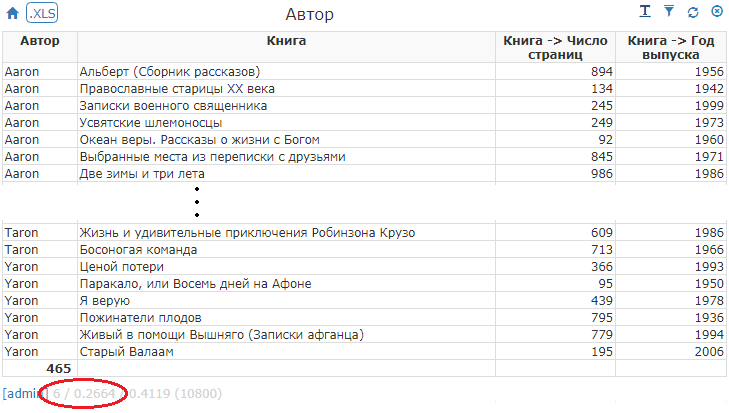
Следует заметить, что за эти 266 мс конструктор выполнил 6 запросов к своей базе (проверил токен пользователя и его права, нашел мета-данные отчета, выполнил отчет). Собственно отчет выполнился за 264 мс.
В базу был отправлен такой запрос:
SELECT a225.val v1_225,a217.val v2_217,a223.val v3_217,a219.val v4_217 FROM test a225 LEFT JOIN (test r217 JOIN test a217 USE INDEX (PRIMARY)) ON r217.up=a217.id AND a225.id=r217.t AND a217.t=217 LEFT JOIN test a223 ON a223.up=a217.id AND a223.t=223 LEFT JOIN test a219 ON a219.up=a217.id AND a219.t=219 WHERE a225.up!=0 AND a225.t=225 AND a225.val LIKE '%aro%' LIMIT 1000
Такой был его план выполнения:

База, можно сказать, «холодная», поэтому время выполнения, должно быть, преувеличено.
Выполним тот же запрос еще несколько раз, посмотрим что изменится, сведя все результаты в таблицу (время в секундах).
| Таблицы | Конструктор | Разница в разах |
|---|---|---|
| 0,1927 | 0,2643 | 1,37 |
| 0,1175 | 0,1965 | 1,67 |
| 0,0777 | 0,1268 | 1,63 |
| 0,1178 | 0,0983 | 0,83 |
| 0,0626 | 0,1131 | 1,81 |
| Среднее: 1,46 |
Видно, что разница по времени примерно в полтора раза, при этом абсолютная разница во времени не может быть заметна на глаз. Оба решения работают достаточно быстро для комфортного восприятия в пользовательском интерфейсе.
Главное, что следует уяснить: при обсуждаемом подходе ядро системы не будет производить полный скан таблицы
Поиск ограничен только той областью, где находятся данные нужного типа. Это обеспечивается описанными выше индексами и правилами выборки данных. В упомянутой Magento, например, то же самое достигается разнесением атрибутов по разным таблицам.
Проведем еще несколько тестов, учитывающие другие типовые случаи из жизни
Обычно поиск осуществляется с использованием индеска, например, по первым символам имени автора.
Перепишем запрос следующим образом:
SELECT author.author, books.name, books.pages, books.year FROM books, author WHERE author.author LIKE 'lac%' AND books.author=author.id LIMIT 1000
В традиционной базе этот запрос выполнился за 3.1 мс:

В конструкторе все запросы для генерации страницы выполнились за 8.4 мс, из которых запрос отчета занял ровно 6 мс:

Выборка происходит несравнимо быстрее, потому что используются индексы, как мы и ожидали.
В обычной базе данных:

В конструкторе:

Сделаем несколько аналогичных выборок наугад, занося результаты в таблицу (время в миллисекундах):
| Условие | Кол-во записей | Таблицы | Конструктор | Разница в разах |
|---|---|---|---|---|
| LIKE'Le%' | 1001 | 11,1 | 48,5 | 4,37 |
| LIKE 'lac%' | 108 | 3,1 | 6,0 | 1,94 |
| LIKE 'Lean%' | 66 | 2,7 | 8,2 | 3,04 |
| LIKE 'dac%' | 49 | 3,9 | 2,6 | 0,67 |
| LIKE 'rac%' | 30 | 2,5 | 3,2 | 1,28 |
| LIKE 'nac%' | 18 | 2,4 | 2,8 | 1,17 |
| = 'Волков' | 6 | 3,9 | 1,5 | 0,38 |
| = 'John' | 6 | 2,7 | 1,1 | 0,41 |
| Среднее: 1,66 |
По результатам в таблице можно сделать вывод, что чем больше записей возвращает запрос, тем больше конструктор проигрывает при сборе данных. При небольшом количестве записей конструктор начинает выигрывать, как это ни покажется странно.
Также будет интересно протестировать выборку по более многочисленной категории — книгам
Применим фильтр к названию книги: поиск подстроки. Перепишем запрос так:
SELECT author.author, books.name, books.pages, books.year FROM books, author WHERE books.name LIKE '%лые пар%' AND books.author=author.id LIMIT 50
Аналогичный запрос создадим в конструкторе:

Запустив эти два отчета увидим большую разницу во времени их выполнения: 148 мс в обычной базе и 2490 мс в конструкторе. Разница почти в 17 раз!
К счастью, мы помним рекомендацию, данную в моей прошлой статье, которая велит нам переместить одну колонку отчета и начинать выборку с книги, а не с автора. Получится такой отчет:

Перезапустим оба отчета и опять увидим большую разницу во времени выполнения: 181 мс в обычной базе и 25 мс в конструкторе. Теперь, наоборот, конструктор отработал в 7 раз быстрее.
Для чистоты эксперимента зададим порядок выборки в обычной БД:
SELECT author.author, books.name, books.pages, books.year FROM books INNER JOIN author ON books.author=author.id WHERE books.name LIKE '%лые пар%' LIMIT 50
Еще раз выполнив оба отчета я получил такой тайминг: 62 мс в обычной базе и 47 мс в конструкторе. Вполне сравнимо. Похоже, обе базы на одном сервере как бы перетягивают одеяло на себя, и в замерах есть некоторые погрешности. В отличие от конструктора, оптимизатор обычной БД вряд ли перестроил план выполнения в последней редакции запроса.
Видно, что конструктор несколько отстает по производительности, однако задача этого эксперимента доказать, что конструктор не создает критичной деградации производительности с ростом объема данных.
Логика организации данных такова, что конструктор будет исполнять запросы так же, без полного сканирования и с использованием индексов, при любом объеме данных. На действительно больших данных понадобится принимать аналогичные меры, как в традиционной БД.
Напоследок сравним достаточно типичный случай: пользователь хочет найти книги определенного года и (или) с заданным количеством страниц. Вот наш запрос для этого:
SELECT author.author, books.name, books.pages, books.year FROM books, author WHERE books.pages=150 AND books.year=1972 AND books.author=author.id LIMIT 50
А так такой запрос выглядит в конструкторе:

Результаты различаются очень сильно, более чем в 30 раз в пользу конструктора:


Когда число таких запросов будет расти, производительность обычной базы без подстройки резко упадет, перечеркивая все её небольшие преимущества в проведенных тестах. Это загонит график в красную и бордовую зоны на картинке в начале статьи.
Здесь мы плавно возвращаемся к вопросу, что это и зачем оно: это основа простого в освоении конструктора, позволяющего снизить риск лавинообразной деградации производительности.
Конструктор дает более удобное средство работы с данными: сравните обычные запросы DDL и DML в этой статье с тем как это делается в конструкторе.

