Большинство современных систем распознавания речи человека основаны на методах, которые разбивают запись голоса на фонемы и анализируют их амплитудно-частотные характеристики с целью поиска фонем отдельных букв на основе классификации их по определенным наборам частотных характеристик. Такие методы рассматривают каждую фонему, как единую неделимую единицу звукового сигнала с квазистационарными частотными характеристиками. При таком подходе не учитываются характеристики фонемы, динамически изменяющиеся во времени.

Но такие подходы к анализу речи можно применять не только для ее распознавания, но и для обучения аналитического описания фонем, построения математической модели по полученным данным и синтез звука, практический аналогичный оригиналу.
Всем со школы еще известно, что слово состоит из одного или нескольких слогов, которые в свою очередь состоят из одной или нескольких фонем. А фонема – это такая минимальная единица языка (самое главное, что она смыслоразличительная), она не имеет какого-либо лексического или грамматического значения, но служит для того, чтобы мы могли понимать элементарные единицы языка – слова.
Вот так выглядит амплитудно-временная характеристика фонемы буквы «О».
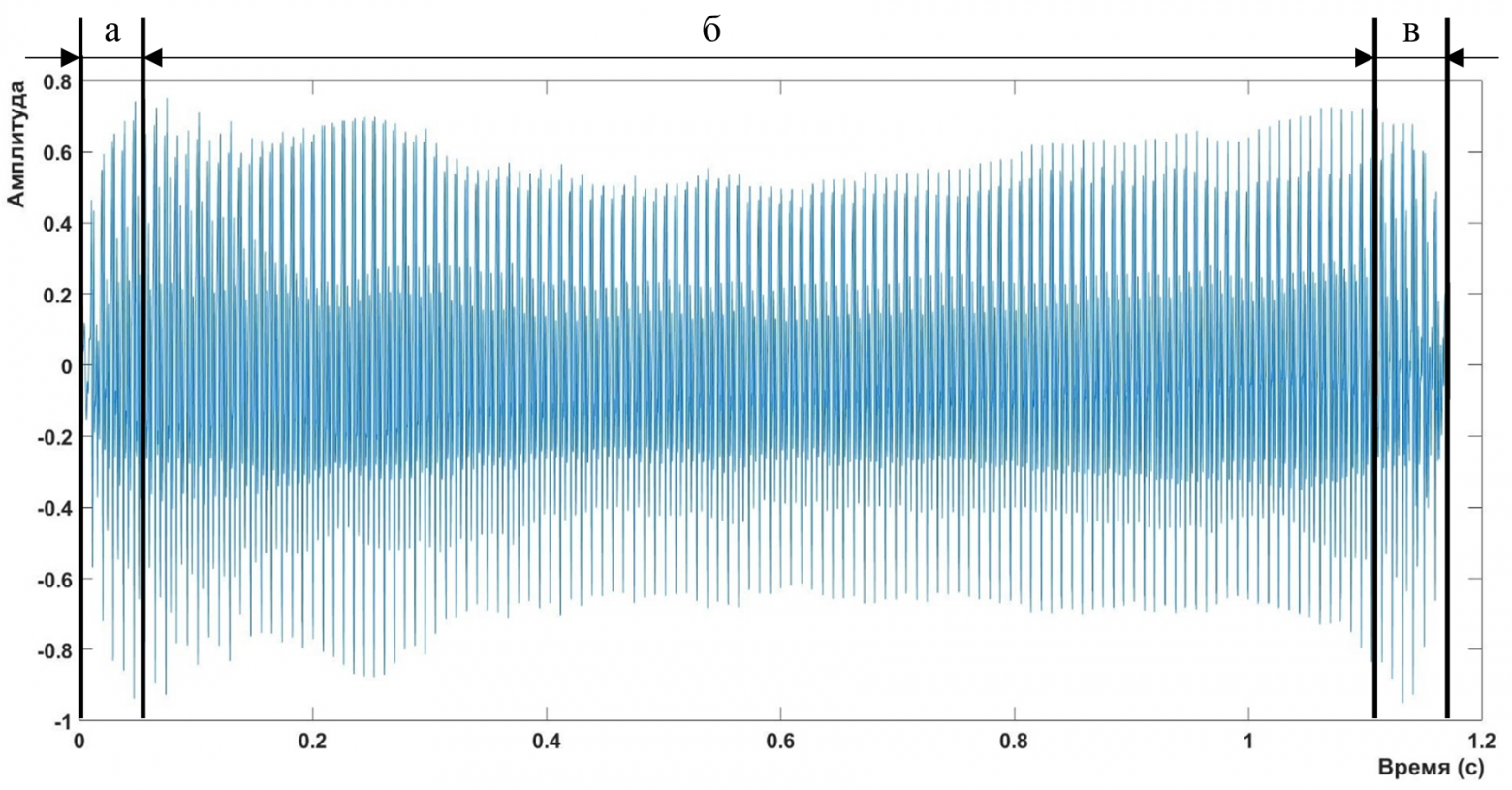
Для удобства я отметил здесь три разных временных промежутка:
Я проводил анализ отрезка времени, в течение которого фонема (ее амплитудно-временная характеристика) остается в квазистационарном состоянии. Здесь же можно предположить, что именно в этот момент времени неизменны (почти) составляющие спектра звука.
Для дальнейшего анализа и описания, нужно декомпозировать звук выдержки в спектральные составляющие.
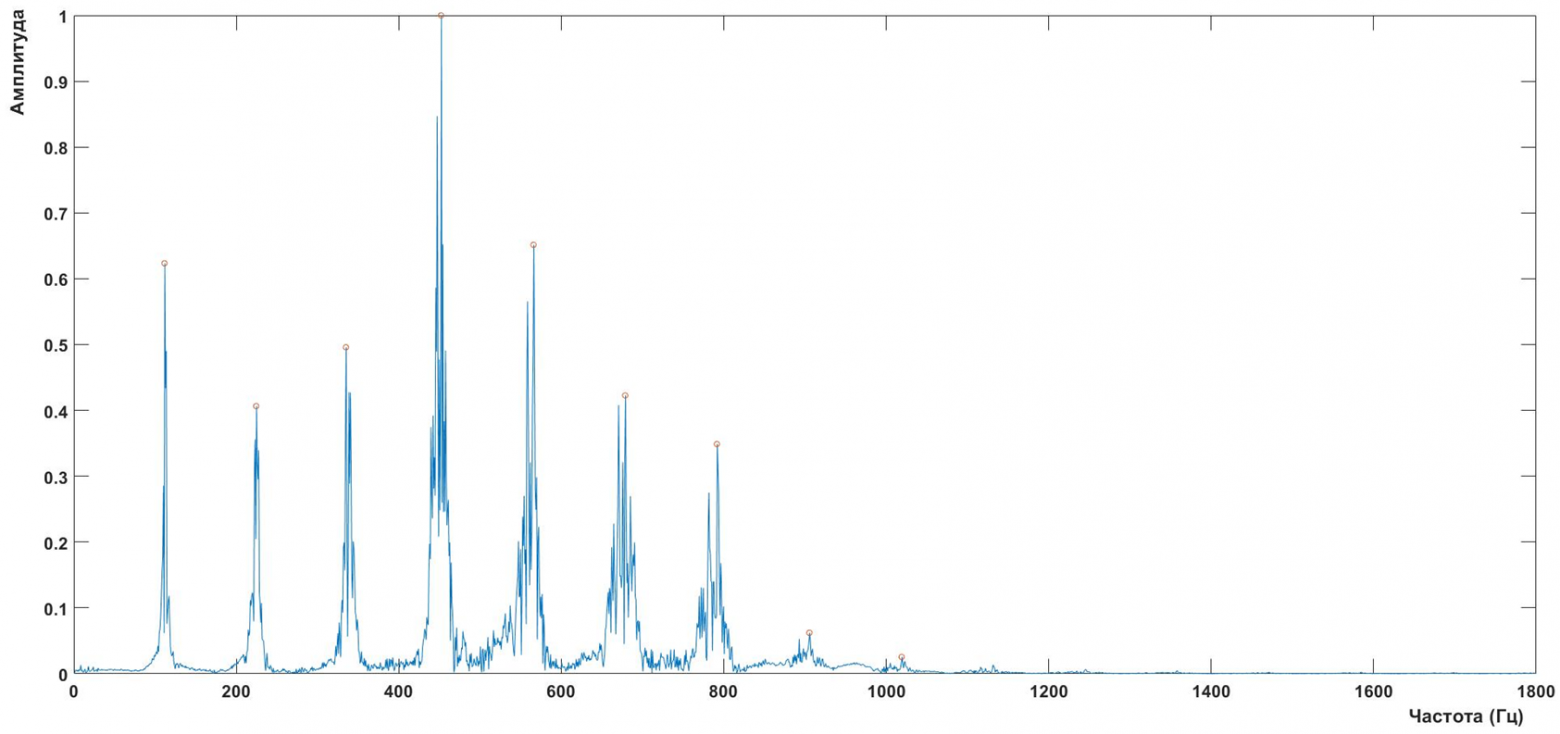
Но фонема, как атом, казалось бы нельзя разделить на составляющие то, что кажется неделимым. Но это не так: каждый пик на приведенном выше графике соответствует одной гармонической составляющей фонемы – форманте. Таким образом, каждую фонему можно описать, если описать ее простейшие составляющие. А с последним проблем возникнуть не должно ни у кого. Если вы внимательно посмотрите на график, то сможете легко определить, что форманта описывается одновременно двумя параметрами: частотой и относительной амплитудой. Соответственно чисто математически эти два параметра формируют вектор, а набор таких векторов, соответствующих имеющимся значимым формантам, соответствует матрице параметров.
Тогда фонема (квазистационарный процесс) может характеризоваться следующим набором параметров:
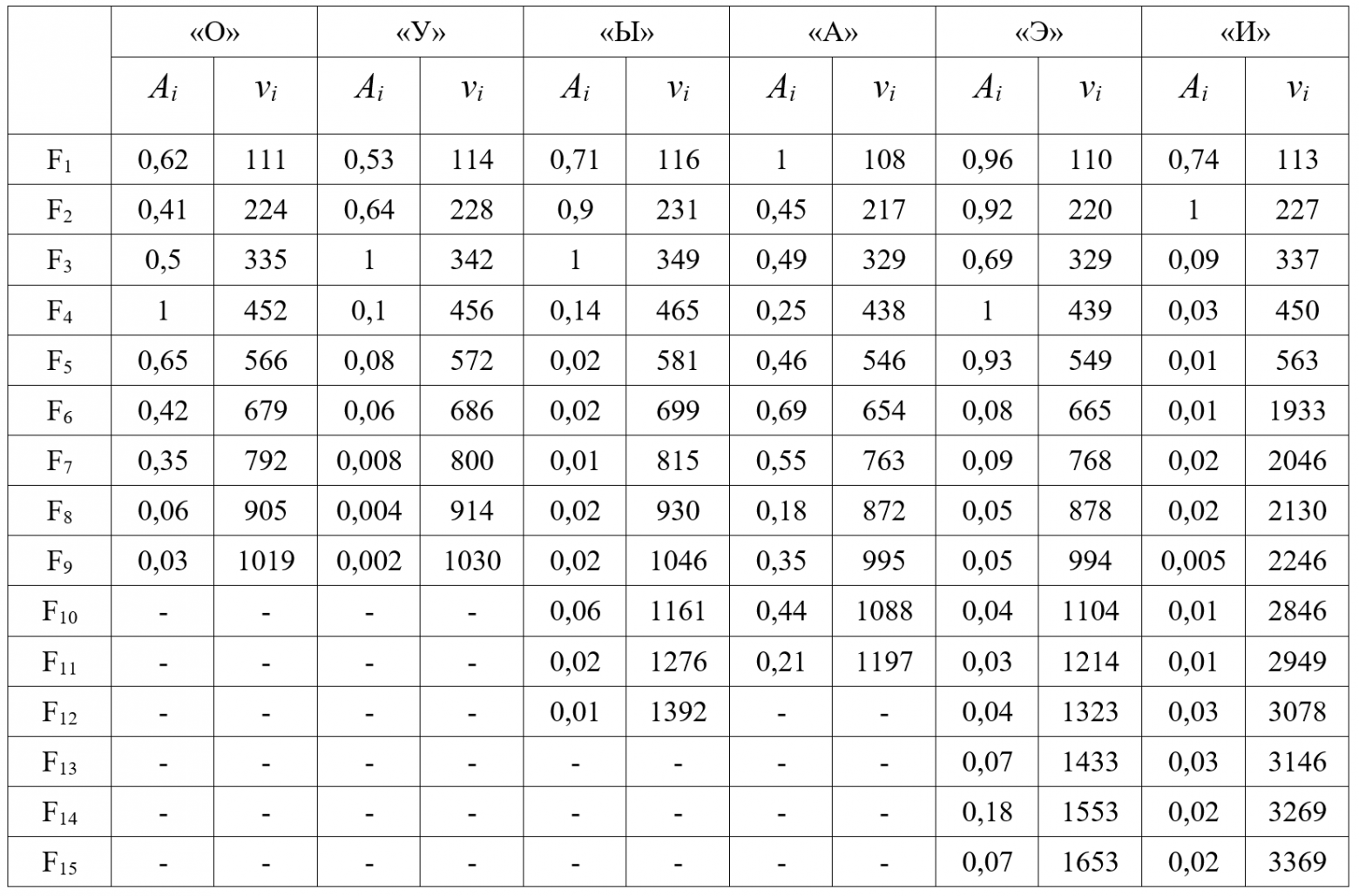
Тут же приведены параметры и для некоторых других гласных букв. Буква A – амплитуда, соответственно v – частота. Справедливо будет заметить, что самыми «сложными» буквами являются «Э» и «И» – спектр их фонем шире, а значимые частоты находятся в двух различных промежутках.
Для реализации возможности оценки качества описанного метода, была предложена модель реконструкции фонем речи человека по полученным параметрическим матрицам: . Здесь под знаком суммы указана формальная запись форманты. Соответственно, используя даные из таблицы выше, можно составит модель звука, например буквы «У» и синтезировать его.
. Здесь под знаком суммы указана формальная запись форманты. Соответственно, используя даные из таблицы выше, можно составит модель звука, например буквы «У» и синтезировать его.

Набор параметров значений матриц зависит от свойств фонемы. Так, для реалистичной реконструкции звукозаписи гласной буквы «У» применена матрица, состоящая из восемнадцати числовых параметров, описывающих девять значимых формант. Для построения более точной модели, необходимо учитывать все значимые форманты фонемы. Другим условием точности сравнения оригинального и синтезированного сигнала является равная продолжительность звучания сигналов.
Вы поняли, что фонема – не такая уж неделимая единица при анализе речи человека. Так же я вам показал простой способ аналитического описания формант фонем речи человека. В последнем разделе разобрали, что по полученным параметрам возможно построить математическую модель фонемы, а полученную модель в свою очередь возможно использовать для синтеза фонемы. Надеюсь данный материал вам понравился. В следующей статье разберем, чем же сложна эмоциональная окраска голоса и как для нее можно было бы построить математические модели эмпирически.
Основной текст опубликованной работы можно найти здесь.
Но такие подходы к анализу речи можно применять не только для ее распознавания, но и для обучения аналитического описания фонем, построения математической модели по полученным данным и синтез звука, практический аналогичный оригиналу.
Анализ составных частей человеческой речи
Всем со школы еще известно, что слово состоит из одного или нескольких слогов, которые в свою очередь состоят из одной или нескольких фонем. А фонема – это такая минимальная единица языка (самое главное, что она смыслоразличительная), она не имеет какого-либо лексического или грамматического значения, но служит для того, чтобы мы могли понимать элементарные единицы языка – слова.
Вот так выглядит амплитудно-временная характеристика фонемы буквы «О».
Для удобства я отметил здесь три разных временных промежутка:
- а – процесс экскурсии (каждая фонема начинается именно с этого процесса)
- б – процесс выдержки (то самое «место» фонемы, которое требует описания)
- в – процесс рекскурсии (грубо говоря – закончили говорить, закончился и звук :) )
Я проводил анализ отрезка времени, в течение которого фонема (ее амплитудно-временная характеристика) остается в квазистационарном состоянии. Здесь же можно предположить, что именно в этот момент времени неизменны (почти) составляющие спектра звука.
Для дальнейшего анализа и описания, нужно декомпозировать звук выдержки в спектральные составляющие.
Но фонема, как атом, казалось бы нельзя разделить на составляющие то, что кажется неделимым. Но это не так: каждый пик на приведенном выше графике соответствует одной гармонической составляющей фонемы – форманте. Таким образом, каждую фонему можно описать, если описать ее простейшие составляющие. А с последним проблем возникнуть не должно ни у кого. Если вы внимательно посмотрите на график, то сможете легко определить, что форманта описывается одновременно двумя параметрами: частотой и относительной амплитудой. Соответственно чисто математически эти два параметра формируют вектор, а набор таких векторов, соответствующих имеющимся значимым формантам, соответствует матрице параметров.
Тогда фонема (квазистационарный процесс) может характеризоваться следующим набором параметров:
Тут же приведены параметры и для некоторых других гласных букв. Буква A – амплитуда, соответственно v – частота. Справедливо будет заметить, что самыми «сложными» буквами являются «Э» и «И» – спектр их фонем шире, а значимые частоты находятся в двух различных промежутках.
Синтез фонем
Для реализации возможности оценки качества описанного метода, была предложена модель реконструкции фонем речи человека по полученным параметрическим матрицам:
. Здесь под знаком суммы указана формальная запись форманты. Соответственно, используя даные из таблицы выше, можно составит модель звука, например буквы «У» и синтезировать его.Набор параметров значений матриц зависит от свойств фонемы. Так, для реалистичной реконструкции звукозаписи гласной буквы «У» применена матрица, состоящая из восемнадцати числовых параметров, описывающих девять значимых формант. Для построения более точной модели, необходимо учитывать все значимые форманты фонемы. Другим условием точности сравнения оригинального и синтезированного сигнала является равная продолжительность звучания сигналов.
Заключение и выводы
Вы поняли, что фонема – не такая уж неделимая единица при анализе речи человека. Так же я вам показал простой способ аналитического описания формант фонем речи человека. В последнем разделе разобрали, что по полученным параметрам возможно построить математическую модель фонемы, а полученную модель в свою очередь возможно использовать для синтеза фонемы. Надеюсь данный материал вам понравился. В следующей статье разберем, чем же сложна эмоциональная окраска голоса и как для нее можно было бы построить математические модели эмпирически.
P.S.
Основной текст опубликованной работы можно найти здесь.

