
Привет, Хабр!
В декабре наш коллега от направления «Продвинутая аналитика» Леонид Шерстюк занял первое место в компетенции Машинное обучение и большие данные во II отраслевом чемпионате DigitalSkills. Это «цифровая» ветка известных профессиональных конкурсов, которые устраивает WorldSkills Russia. Всего в чемпионате приняли участие более 200 человек, соревновались за лидерство по 25 цифровым компетенциям – Корпоративная защита от внутренних угроз ИБ, Интернет-маркетинг, Разработка компьютерных игр и мультимедийных приложений, Квантовые технологии, Интернет вещей, Промышленный дизайн и т.д.

В качестве кейса для Машинного обучения была предложена задача по мониторингу и обнаружению дефектов трубопроводов АЭС, нефтяных и газотрубопроводов с помощью системы полуавтоматического ультразвукового контроля.
О том, что было на конкурсе и как ему удалось победить, Леонид расскажет под катом.
WorldSkills – международная организация, устраивающая конкурсы профессиональных навыков по всему миру. Традиционно в этих соревнованиях участвовали представители промышленных компаний и студенты соответствующих ВУЗов, демонстрируя свои навыки в рабочих специальностях. С недавних пор на конкурсе начали появляться цифровые номинации, где молодые специалисты соревнуются в навыках роботостроения, разработки приложений, информационной безопасности, и в прочих профессиях, которые рабочими уже никак не назовешь. В одной из таких номинаций – по Машинному обучению и работе с большими данными – я соревновался в Казани на конкурсе DigitalSkills, проходящем под эгидой WS.
Поскольку компетенция для конкурса новая, мне было трудно представить, чего ожидать. На всякий случай я повторил все, что знаю о работе с БД и распределенными вычислениями, метриками и алгоритмами обучения, статистическими критериями и методами предобработки. Будучи знакомым с приблизительными критериями оценивания, я не понимал, как можно в 6 коротких сессиях уместить и полноценную работу с Hadoop, и создание чат-бота.
Весь конкурс проходит 3 дня, в течение 6 сессий. Каждая сессия представляет из себя 3 часа с перерывом, за которые тебе необходимо выполнить несколько заданий, содержательно связанных друг с другом. Сначала может показаться, что времени вполне достаточно, но в реальности требовался бешеный темп, чтобы успеть сделать все задуманное.
На конкурсе ожидаемо выяснилось, что работы с большими данными не предполагается, а весь пул задач сводится к анализу ограниченного набора данных.
В сущности, нам было предложено повторить путь одного из организаторов, к которому пришли заказчики со своей проблемой и данными, и от которого ожидают коммерческого предложения в течение нескольких недель.
Мы работали с данными ПУЗК (системы полуавтоматического ультразвукового контроля). Система предназначена для проверки швов на трубопроводе на наличие трещин и дефектов. Сама установка едет по рельсе, установленной на трубу, и на каждом шаге делает 16 замеров. В идеальных условиях и при отсутствии дефектов некоторые датчики должны были давать максимальный сигнал, другие – нулевой; в реальности данные были сильно зашумлены, и ответить на вопрос, есть ли в данном месте дефект, становилось нетривиальной задачей.

Установка системы ПУЗК
Первый день был посвящен знакомству с данными, их очистке, составлением дескриптивных статистик. Нам дали минимальную вводную информацию об установке и типах датчиков, закрепленных на приборе. Помимо предобработки данных, нам необходимо было установить, к какому типу относятся датчики, и как они расположены на приборе.
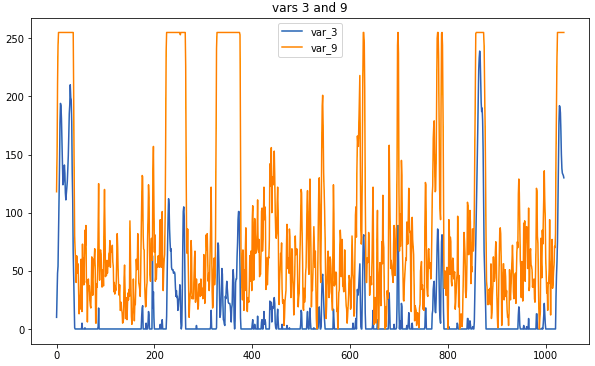
Пример данных: так выглядят связанные датчики
Главная операция по предобработке – замена измерений скользящим средним. При слишком большом окне был риск потерять слишком много информации, зато корреляции, помогающие определить тип, были бы более наглядными. Некоторые связи были заметны и без предобработки; однако на внимательное разглядывание сырых данных не было времени, поэтому без использования коррелограмм не обойтись.
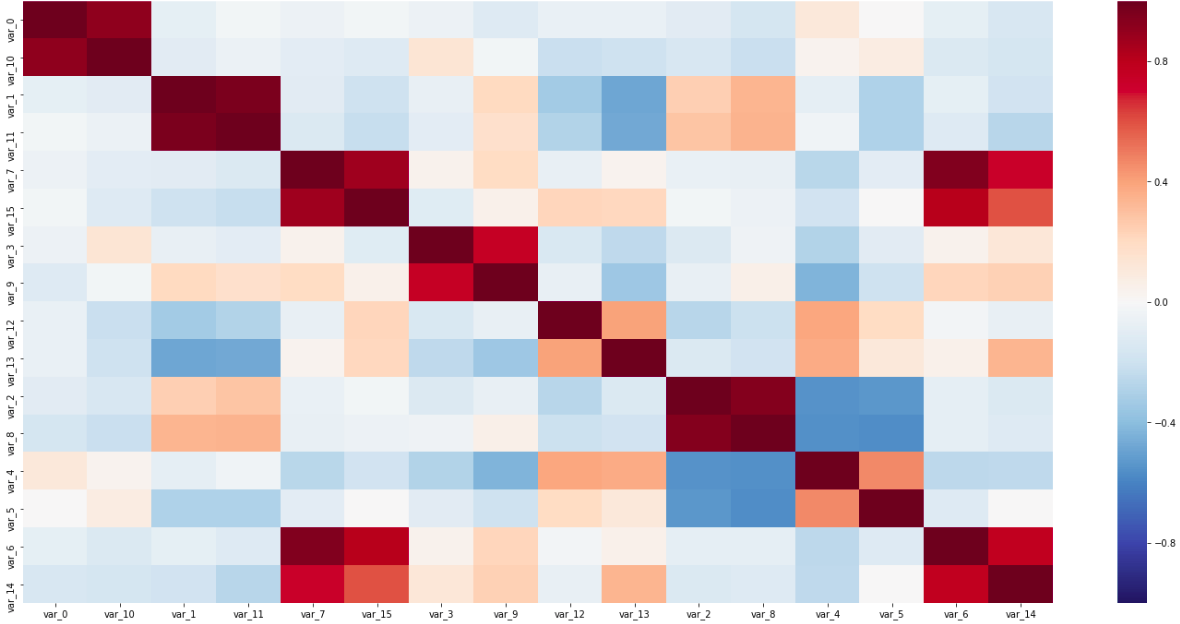
Матрица корреляций
На этой матрице видны как пары датчиков вдоль диагонали, тесно связанные друг с другом, так и обратно коррелирующие переменные; все это помогло определить типы датчиков.
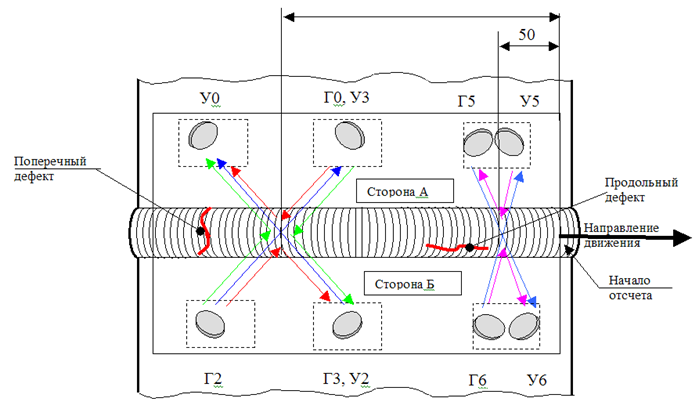
Последним обязательным пунктом было сведéние датчиков к одной координате. Поскольку измерительный прибор существенно больше одного шага измерения, а датчики были разнесены по всему прибору, это был обязательный шаг перед дальнейшим использованием данных для обучения.
 \
\
Схема расположения датчиков на установке
На схеме установки датчиков на приборе видно, что нам нужно найти расстояния между тремя группами датчиков. Самый простой и быстрый способ здесь – установить, на каком сегменте прибора должен находиться каждый датчик, а затем искать максимальную корреляцию, сдвигая часть измерений на шаг.
Этот этап усложнялся тем, что мои предположения о типе датчиков не являлись гарантированными, поэтому мне приходилось просматривать все корреляции, типы, схему, и увязывать это в единую непротиворечивую систему.
За второй день нам предстояло подготовить данные к обучению и провести кластеризацию на точках, а затем построить классификатор.
В ходе подготовки данных я убрал слишком коррелирующие показания, а в качестве синтетической фичи добавил скользящее среднее, производную и z-score. Бесспорно, в синтезе новых переменных можно было разыграться достаточно широко, но время накладывало свои ограничения.
Кластеризация могла бы помочь отделить точки с дефектами от всех остальных. Я попробовал 3 метода: k-means, Birch и DBScan, но, к сожалению, ни один из них не дал хорошего результата.
Для предиктивного алгоритма нам была дана полная свобода; задавался только формат, который должен получиться на выходе. Алгоритм должен был предоставлять таблицу (или данные, сводимые к ней), в которой строке соответствует одна трещина, а столбцам – ее характеристики (как то: длина, ширина, тип и сторона). Мне представлялся простейшим вариант, при котором мы делаем предсказание для каждой точки тестовой выборки, а затем соседние объединяем в одну трещину. В итоге я сделал 3 классификатора, которые отвечали на следующие вопросы: на какой стороне шва находится дефект, как глубоко он проходит, и к какому типу относится (продольный или поперечный).
Здесь бросается в глаза глубина, которую следовало бы предсказывать регрессией; однако, в размеченной выборке я обнаружил только 5 уникальных глубин, поэтому я посчитал это упрощение допустимым.

Метрики оценки работы алгоритмов
Из всех алгоритмов (я успел попробовать логистическую регрессию, решающее дерево и градиентный бустинг) лучше всего, ожидаемо, справился бустинг. Метрики, несомненно, очень приятные, но оценить работу алгоритмов без результатов на новой, тестовой выборке, достаточно сложно. Организаторы так и не вернулись с конкретными метриками, ограничившись лишь общим комментарием о том, что никто не справился с тестом так же хорошо, как на отложенной выборке.
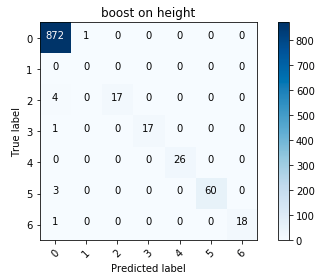
Матрица ошибок для бустинга
В целом я остался доволен результатами; в частности, редукция высоты до категориальной переменной оправдала себя.
За последний день нам предстояло завернуть натренированные алгоритмы в продукт, которым мог бы воспользоваться потенциальный заказчик, и подготовить презентацию своего enterprise-ready решения.
Здесь мне помог перфекционизм в написании относительно чистого кода, не пропавший даже в условиях ограниченного времени. Из готовых кусков кода прототип сложился быстро, и у меня было время на отладку ошибок. В отличие от предыдущих этапов, здесь более важную роль играла работоспособность решения, а не удовлетворение формальным критериям.

Готовый продукт — CLI-утилита
К концу сессии у меня получилась CLI-утилита, принимающая на вход папку с исходниками, и возвращающая таблицы с результатами предсказания в виде, удобном для технолога.
На завершающем этапе мне предоставили возможность рассказать о своих успехах и увидеть, к чему пришли другие участники. Даже в условиях строгих критериев наши решения были совершенно разными — кто-то провел успешную кластеризацию, другие умело воспользовались линейными методами. В ходе презентаций конкурсанты делали упор на свои сильные стороны – одни ставили на продажу продукта, другие более глубоко погружались в технические детали; были и красивые графики, и адаптивные интерфейсы решения.

Главное преимущество моего решения поместилось на один слайд
Что можно сказать о соревновании в целом?
Соревнования такого типа – это отличная возможность выяснить, насколько оперативно ты умеешь выполнять задачи, типичные для твоей специальности. Критерии были составлены таким образом, что больше баллов получает не тот, кто получил самые лучшие результаты (как это происходит, например, на Kaggle), а кто быстрее всего может выполнить операции, типичные для ежедневной работы в индустрии. По моему мнению, участие и победа в таких соревнованиях может сказать потенциальному нанимателю не меньше, чем опыт в индустрии, на хакатонах и Kaggle.
Ленонид Шерстюк,
Аналитик данных, «Продвинутая аналитика», СИБУР
В декабре наш коллега от направления «Продвинутая аналитика» Леонид Шерстюк занял первое место в компетенции Машинное обучение и большие данные во II отраслевом чемпионате DigitalSkills. Это «цифровая» ветка известных профессиональных конкурсов, которые устраивает WorldSkills Russia. Всего в чемпионате приняли участие более 200 человек, соревновались за лидерство по 25 цифровым компетенциям – Корпоративная защита от внутренних угроз ИБ, Интернет-маркетинг, Разработка компьютерных игр и мультимедийных приложений, Квантовые технологии, Интернет вещей, Промышленный дизайн и т.д.
В качестве кейса для Машинного обучения была предложена задача по мониторингу и обнаружению дефектов трубопроводов АЭС, нефтяных и газотрубопроводов с помощью системы полуавтоматического ультразвукового контроля.
О том, что было на конкурсе и как ему удалось победить, Леонид расскажет под катом.
WorldSkills – международная организация, устраивающая конкурсы профессиональных навыков по всему миру. Традиционно в этих соревнованиях участвовали представители промышленных компаний и студенты соответствующих ВУЗов, демонстрируя свои навыки в рабочих специальностях. С недавних пор на конкурсе начали появляться цифровые номинации, где молодые специалисты соревнуются в навыках роботостроения, разработки приложений, информационной безопасности, и в прочих профессиях, которые рабочими уже никак не назовешь. В одной из таких номинаций – по Машинному обучению и работе с большими данными – я соревновался в Казани на конкурсе DigitalSkills, проходящем под эгидой WS.
Поскольку компетенция для конкурса новая, мне было трудно представить, чего ожидать. На всякий случай я повторил все, что знаю о работе с БД и распределенными вычислениями, метриками и алгоритмами обучения, статистическими критериями и методами предобработки. Будучи знакомым с приблизительными критериями оценивания, я не понимал, как можно в 6 коротких сессиях уместить и полноценную работу с Hadoop, и создание чат-бота.
Весь конкурс проходит 3 дня, в течение 6 сессий. Каждая сессия представляет из себя 3 часа с перерывом, за которые тебе необходимо выполнить несколько заданий, содержательно связанных друг с другом. Сначала может показаться, что времени вполне достаточно, но в реальности требовался бешеный темп, чтобы успеть сделать все задуманное.
На конкурсе ожидаемо выяснилось, что работы с большими данными не предполагается, а весь пул задач сводится к анализу ограниченного набора данных.
В сущности, нам было предложено повторить путь одного из организаторов, к которому пришли заказчики со своей проблемой и данными, и от которого ожидают коммерческого предложения в течение нескольких недель.
Мы работали с данными ПУЗК (системы полуавтоматического ультразвукового контроля). Система предназначена для проверки швов на трубопроводе на наличие трещин и дефектов. Сама установка едет по рельсе, установленной на трубу, и на каждом шаге делает 16 замеров. В идеальных условиях и при отсутствии дефектов некоторые датчики должны были давать максимальный сигнал, другие – нулевой; в реальности данные были сильно зашумлены, и ответить на вопрос, есть ли в данном месте дефект, становилось нетривиальной задачей.
Установка системы ПУЗК
Первый день был посвящен знакомству с данными, их очистке, составлением дескриптивных статистик. Нам дали минимальную вводную информацию об установке и типах датчиков, закрепленных на приборе. Помимо предобработки данных, нам необходимо было установить, к какому типу относятся датчики, и как они расположены на приборе.
Пример данных: так выглядят связанные датчики
Главная операция по предобработке – замена измерений скользящим средним. При слишком большом окне был риск потерять слишком много информации, зато корреляции, помогающие определить тип, были бы более наглядными. Некоторые связи были заметны и без предобработки; однако на внимательное разглядывание сырых данных не было времени, поэтому без использования коррелограмм не обойтись.
Матрица корреляций
На этой матрице видны как пары датчиков вдоль диагонали, тесно связанные друг с другом, так и обратно коррелирующие переменные; все это помогло определить типы датчиков.
Последним обязательным пунктом было сведéние датчиков к одной координате. Поскольку измерительный прибор существенно больше одного шага измерения, а датчики были разнесены по всему прибору, это был обязательный шаг перед дальнейшим использованием данных для обучения.
\Схема расположения датчиков на установке
На схеме установки датчиков на приборе видно, что нам нужно найти расстояния между тремя группами датчиков. Самый простой и быстрый способ здесь – установить, на каком сегменте прибора должен находиться каждый датчик, а затем искать максимальную корреляцию, сдвигая часть измерений на шаг.
Этот этап усложнялся тем, что мои предположения о типе датчиков не являлись гарантированными, поэтому мне приходилось просматривать все корреляции, типы, схему, и увязывать это в единую непротиворечивую систему.
За второй день нам предстояло подготовить данные к обучению и провести кластеризацию на точках, а затем построить классификатор.
В ходе подготовки данных я убрал слишком коррелирующие показания, а в качестве синтетической фичи добавил скользящее среднее, производную и z-score. Бесспорно, в синтезе новых переменных можно было разыграться достаточно широко, но время накладывало свои ограничения.
Кластеризация могла бы помочь отделить точки с дефектами от всех остальных. Я попробовал 3 метода: k-means, Birch и DBScan, но, к сожалению, ни один из них не дал хорошего результата.
Для предиктивного алгоритма нам была дана полная свобода; задавался только формат, который должен получиться на выходе. Алгоритм должен был предоставлять таблицу (или данные, сводимые к ней), в которой строке соответствует одна трещина, а столбцам – ее характеристики (как то: длина, ширина, тип и сторона). Мне представлялся простейшим вариант, при котором мы делаем предсказание для каждой точки тестовой выборки, а затем соседние объединяем в одну трещину. В итоге я сделал 3 классификатора, которые отвечали на следующие вопросы: на какой стороне шва находится дефект, как глубоко он проходит, и к какому типу относится (продольный или поперечный).
Здесь бросается в глаза глубина, которую следовало бы предсказывать регрессией; однако, в размеченной выборке я обнаружил только 5 уникальных глубин, поэтому я посчитал это упрощение допустимым.
Метрики оценки работы алгоритмов
Из всех алгоритмов (я успел попробовать логистическую регрессию, решающее дерево и градиентный бустинг) лучше всего, ожидаемо, справился бустинг. Метрики, несомненно, очень приятные, но оценить работу алгоритмов без результатов на новой, тестовой выборке, достаточно сложно. Организаторы так и не вернулись с конкретными метриками, ограничившись лишь общим комментарием о том, что никто не справился с тестом так же хорошо, как на отложенной выборке.
Матрица ошибок для бустинга
В целом я остался доволен результатами; в частности, редукция высоты до категориальной переменной оправдала себя.
За последний день нам предстояло завернуть натренированные алгоритмы в продукт, которым мог бы воспользоваться потенциальный заказчик, и подготовить презентацию своего enterprise-ready решения.
Здесь мне помог перфекционизм в написании относительно чистого кода, не пропавший даже в условиях ограниченного времени. Из готовых кусков кода прототип сложился быстро, и у меня было время на отладку ошибок. В отличие от предыдущих этапов, здесь более важную роль играла работоспособность решения, а не удовлетворение формальным критериям.
Готовый продукт — CLI-утилита
К концу сессии у меня получилась CLI-утилита, принимающая на вход папку с исходниками, и возвращающая таблицы с результатами предсказания в виде, удобном для технолога.
На завершающем этапе мне предоставили возможность рассказать о своих успехах и увидеть, к чему пришли другие участники. Даже в условиях строгих критериев наши решения были совершенно разными — кто-то провел успешную кластеризацию, другие умело воспользовались линейными методами. В ходе презентаций конкурсанты делали упор на свои сильные стороны – одни ставили на продажу продукта, другие более глубоко погружались в технические детали; были и красивые графики, и адаптивные интерфейсы решения.
Главное преимущество моего решения поместилось на один слайд
Что можно сказать о соревновании в целом?
Соревнования такого типа – это отличная возможность выяснить, насколько оперативно ты умеешь выполнять задачи, типичные для твоей специальности. Критерии были составлены таким образом, что больше баллов получает не тот, кто получил самые лучшие результаты (как это происходит, например, на Kaggle), а кто быстрее всего может выполнить операции, типичные для ежедневной работы в индустрии. По моему мнению, участие и победа в таких соревнованиях может сказать потенциальному нанимателю не меньше, чем опыт в индустрии, на хакатонах и Kaggle.
Ленонид Шерстюк,
Аналитик данных, «Продвинутая аналитика», СИБУР
