Приветствую, друзья!
В предыдущих двух статьях (раз, два) мы погружались в сложность выбора между технологиями и искали оптимальные настройки для нашего решения в Ostrovok.ru. Какую тему поднимем сегодня?
Каждый сервис должен работать на каком-то сервере, общаясь с железом посредством инструментов операционной системы. Этих инструментов великое множество, как и настроек для них. В большинстве случаев для их работы настроек по умолчанию будет более чем достаточно. В этой статье я хотел бы рассказать о тех случаях, когда стандартных настроек все-таки было недостаточно, и приходилось знакомиться с операционной системой чуть ближе – в нашем случае с Linux.

В предыдущей статье я говорил о параметре cpu-map в Haproxy. С его помощью мы привязывали процессы Haproxy к потокам одного ядра на двухпроцессорном сервере. Второе ядро мы отдали под обработку прерываний сетевой карты.
Ниже скрин, на котором можно увидеть подобное разделение. Слева ядра заняты Haproxy в

Привязка прерываний сетевой карты сделана в автоматическом режиме с помощью такого
В интернете есть множество годных простых и более сложных скриптов, делающих ту же работу, но под наши нужды этого скрипта достаточно.
В Haproxy мы привязывали процессы к ядрам, начиная с первого ядра. Этот же скрипт привязывает прерывания, начиная с последнего. Таким образом, мы можем разделить процессоры сервера на два лагеря.
Для большего погружения в тему прерываний и сетевых взаимодействий очень рекомендую прочесть вот эту статью.
Бывает так, что по сети в один момент может прилететь великое множество фреймов, а очередь карты может быть не готова к такому наплыву гостей, пусть даже имея для этого возможности.
Поговорим же о буфере сетевой карты. Чаще всего в значениях по умолчанию используется не весь доступный буфер. Посмотреть текущие параметры можно, используя мощную утилиту ethtool.
Пример использования команды:
А теперь возьмем от жизни все:
Теперь можно быть уверенным, что карточка не сдерживается и работает на максимуме своих возможностей.
В Sysctl великое множество параметров всех цветов и размеров, которые только можно представить. И, как правило, статьи в интернетах, затрагивая вопрос оптимизации, охватывают довольно внушительную часть этих параметров. Я рассмотрю только те, которые было реально полезно поменять в нашем случае.
net.core.netdev_max_backlog – очередь, куда попадают фреймы из сетевой карты, которые затем обрабатываются ядром. При быстрых интерфейсах и больших объемах трафика она может быстро заполняться. Default: 1000.
Мы можем наблюдать за превышением этой очереди глядя на вторую колонку в файле /proc/net/softnet_stat.
Сам файл описывает структуру netif_rx_stats по строке на каждый CPU в системе.
Конкретно вторая колонка описывает количество пакетов в состоянии dropped. Если значение во второй колонке со временем растет, то вероятно стоит увеличить значение
net.core.rmem_default / net.core.rmem_max && net.core.wmem_default / net.core.wmem_max – эти параметры указывают значение по умолчанию / максимальное значение для буферов сокета на чтение и запись. Default значение может быть изменено на уровне приложения в момент создания сокета (кстати, в Haproxy есть параметр, который это делает). У нас бывали случаи, когда ядро накидывало пакетов больше, чем успевал разгребать Haproxy, и тогда начинались проблемы. Поэтому штука важная.
net.ipv4.tcp_max_syn_backlog – отвечает за лимит новых еще не установленных соединений, для которых был получен
net.core.somaxconn – тут уже речь про установленные соединения, но еще не обработанные приложением. Если сервер однопоточный, а к нему пришло два запроса, то первый запрос будет обработан функцией
nf_conntrack_max – вероятно, самый известный из всех параметров. Думаю, почти каждый, кто имел дело с iptables, знает о нем. В идеале, конечно же, если вам не нужно использовать iptables masquerading, то можно выгрузить модуль conntrack и не думать об этом. В моем случае используется Docker, поэтому особо ничего не выгрузишь.
Чтобы не искать вслепую, почему “ваша прокся тормозит”, будет полезно настроить пару графиков и обложить их триггерами.
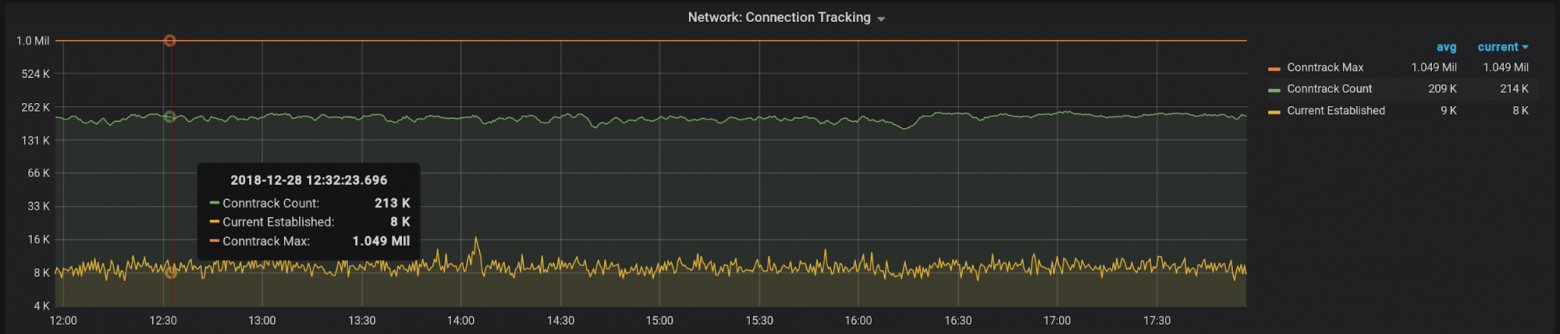
nf_conntrack_count – самая очевидная метрика. По ней можно следить сколько соединений сейчас находится в conntrack таблице. При переполнении таблицы путь для новых соединений будет закрыт.
Текущее значение можно посмотреть здесь:
Tcp segments retransmited – количество пересылок сегментов. Метрика очень объемная, так как может говорить о проблемах на разных уровнях. Рост пересылок может свидетельствовать о проблемах с сетью, о необходимости оптимизации настроек системы или даже о том, что конечное ПО (например, Haproxy) не справляется со своей работой. Как бы там ни было, аномальный рост этого значения может служить поводом для разбирательств.
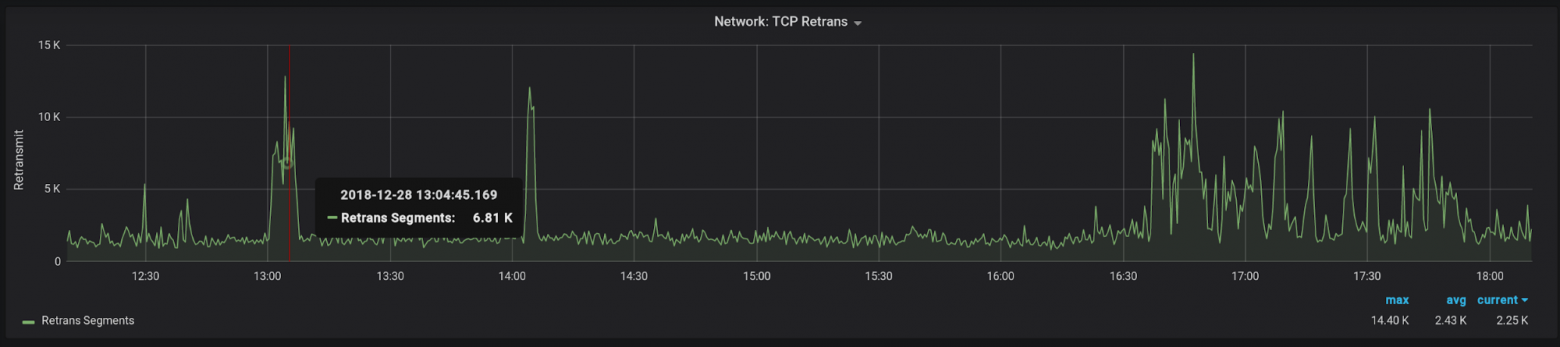
У нас чаще всего рост значений говорит о проблемах с одним из поставщиков, хотя случались проблемы и с производительностью как серверов, так и сети.
Пример для проверки:
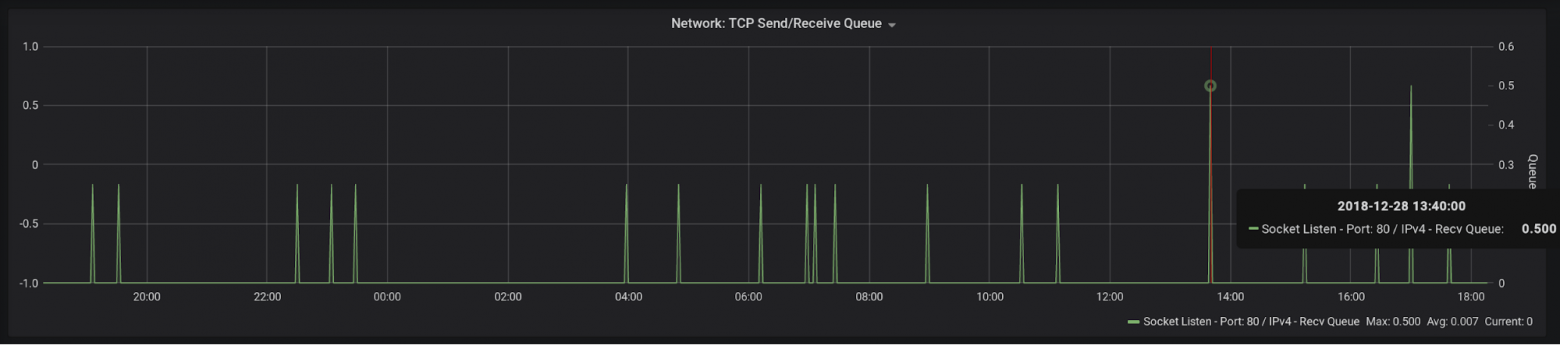
Socket Recv-Q — помните, мы говорили о моментах, когда приложение может не успевать отрабатывать запросы, и тогда
Я лицезрел горы на графиках с этой метрикой, когда параметр maxconn в Haproxy имел значение по умолчанию (2000), и тот попросту не принимал новых соединений.
И снова пример:
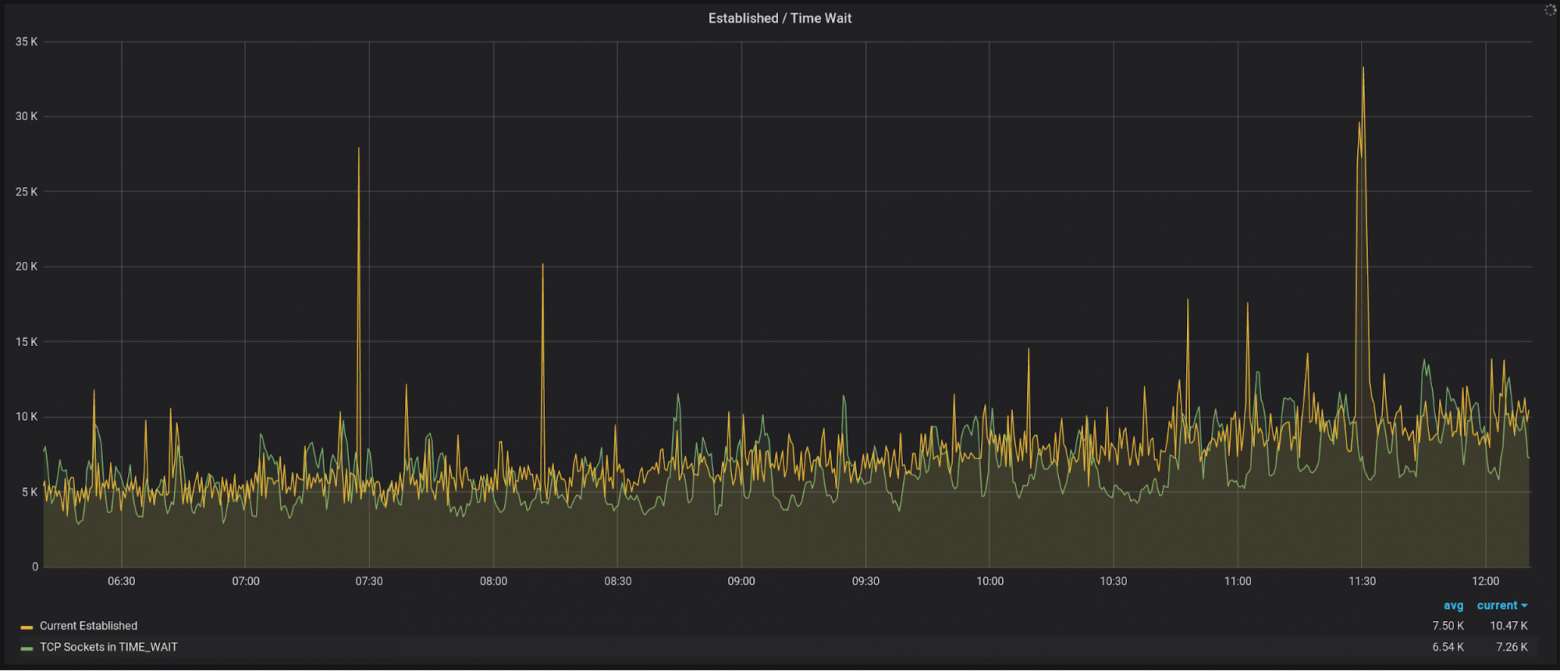
Еще не лишним будет иметь график с разбивкой по состояниям TCP соединений:
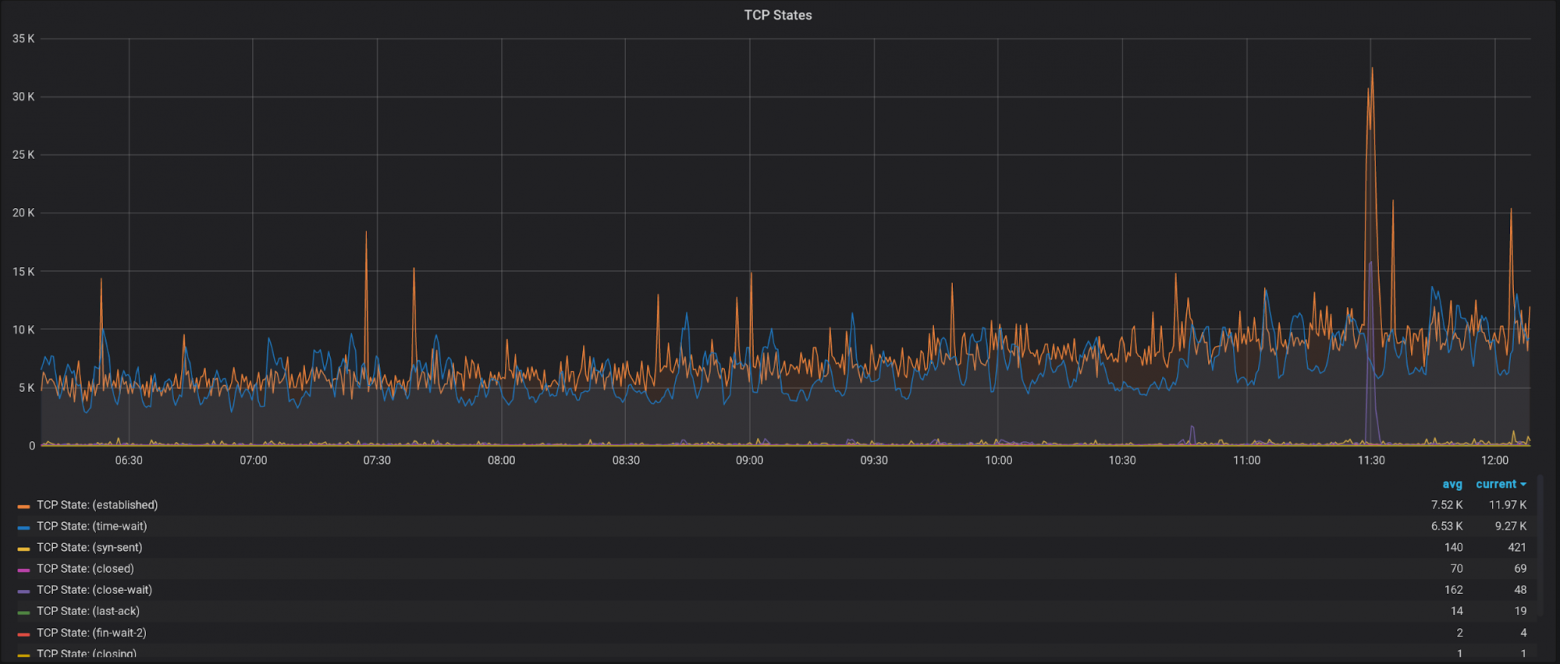
И отдельно вынести
Помимо этих метрик есть множество других, но уже более очевидных – например, загруженность сетевого интерфейса или CPU. Их выбор будет уже больше зависеть от специфики вашей нагрузки.
В общем-то, на этом все – я постарался описать ключевые моменты, с которыми мне довелось столкнуться при настройке http reverse proxy. Казалось бы, задача не сложная, но с ростом нагрузки растет и количество подводных камней, которые всегда всплывают не вовремя. Надеюсь, эта статья поможет вам избежать тех сложностей, с которыми пришлось столкнуться мне.
Всем Peace
В предыдущих двух статьях (раз, два) мы погружались в сложность выбора между технологиями и искали оптимальные настройки для нашего решения в Ostrovok.ru. Какую тему поднимем сегодня?
Каждый сервис должен работать на каком-то сервере, общаясь с железом посредством инструментов операционной системы. Этих инструментов великое множество, как и настроек для них. В большинстве случаев для их работы настроек по умолчанию будет более чем достаточно. В этой статье я хотел бы рассказать о тех случаях, когда стандартных настроек все-таки было недостаточно, и приходилось знакомиться с операционной системой чуть ближе – в нашем случае с Linux.
Используем ядра с умом
В предыдущей статье я говорил о параметре cpu-map в Haproxy. С его помощью мы привязывали процессы Haproxy к потокам одного ядра на двухпроцессорном сервере. Второе ядро мы отдали под обработку прерываний сетевой карты.
Ниже скрин, на котором можно увидеть подобное разделение. Слева ядра заняты Haproxy в
user space, а справа – обработкой прерываний в kernel space.Привязка прерываний сетевой карты сделана в автоматическом режиме с помощью такого
Bash скрипта:
#! /bin/bash interface=${1} if [ -z "${interface}" ];then echo "no interface specified" echo "usage: ${0} eth1" exit 1 fi nproc=$(grep 'physical id' /proc/cpuinfo|sort -u|wc -l) ncpu=$(grep -c 'processor' /proc/cpuinfo) cpu_per_proc=$[ncpu / nproc] queue_threads=$[cpu_per_proc / 2] binary_map="" cpumap="" for(( i=0; i < ncpu; i++ ));do cpumap=${cpumap}1 b+='{0..1}' done binary_map=($(eval echo ${b})) ### Здесь заодно пытаемся поднять количество очередей сетевой карты ### до нужного количества потоков, в случае если карта это поддерживает. ethtool -L ${interface} combined ${queue_threads} || true count=${ncpu} while read irq queue;do let "cpu_num=$[count-1]" let "cpu_index=$[2**cpu_num]" printf "setting ${queue} to %d (%d)\n" $((2#${binary_map[${cpu_index}]})) ${cpu_num} printf "%x\n" "$((2#${binary_map[${cpu_index}]}))" > /proc/irq/${irq}/smp_affinity [ ${interface} != ${queue} ] && count=$[count-1] [ $[ncpu - count] -gt ${queue_threads} ] && count=${ncpu} done < <(awk "/${interface}/ {if(NR > 1){ sub(\":\", \"\", \$1); print \$1,\$(NF)} }" /proc/interrupts) exit 0
В интернете есть множество годных простых и более сложных скриптов, делающих ту же работу, но под наши нужды этого скрипта достаточно.
В Haproxy мы привязывали процессы к ядрам, начиная с первого ядра. Этот же скрипт привязывает прерывания, начиная с последнего. Таким образом, мы можем разделить процессоры сервера на два лагеря.
Для большего погружения в тему прерываний и сетевых взаимодействий очень рекомендую прочесть вот эту статью.
Раскрываем возможности сетевых устройств
Бывает так, что по сети в один момент может прилететь великое множество фреймов, а очередь карты может быть не готова к такому наплыву гостей, пусть даже имея для этого возможности.
Поговорим же о буфере сетевой карты. Чаще всего в значениях по умолчанию используется не весь доступный буфер. Посмотреть текущие параметры можно, используя мощную утилиту ethtool.
Пример использования команды:
> ethtool -g eno1 Ring parameters for eno1: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 256 RX Mini: 0 RX Jumbo: 0 TX: 256
А теперь возьмем от жизни все:
> ethtool -G eno1 rx 4096 tx 4096 > ethtool -g eno1 Ring parameters for eno1: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096
Теперь можно быть уверенным, что карточка не сдерживается и работает на максимуме своих возможностей.
Минимум sysctl настроек для максимальной пользы
В Sysctl великое множество параметров всех цветов и размеров, которые только можно представить. И, как правило, статьи в интернетах, затрагивая вопрос оптимизации, охватывают довольно внушительную часть этих параметров. Я рассмотрю только те, которые было реально полезно поменять в нашем случае.
net.core.netdev_max_backlog – очередь, куда попадают фреймы из сетевой карты, которые затем обрабатываются ядром. При быстрых интерфейсах и больших объемах трафика она может быстро заполняться. Default: 1000.
Мы можем наблюдать за превышением этой очереди глядя на вторую колонку в файле /proc/net/softnet_stat.
awk '{print $2}' /proc/net/softnet_stat
Сам файл описывает структуру netif_rx_stats по строке на каждый CPU в системе.
Конкретно вторая колонка описывает количество пакетов в состоянии dropped. Если значение во второй колонке со временем растет, то вероятно стоит увеличить значение
net.core.netdev_max_backlog или поставить CPU по-шустрее.net.core.rmem_default / net.core.rmem_max && net.core.wmem_default / net.core.wmem_max – эти параметры указывают значение по умолчанию / максимальное значение для буферов сокета на чтение и запись. Default значение может быть изменено на уровне приложения в момент создания сокета (кстати, в Haproxy есть параметр, который это делает). У нас бывали случаи, когда ядро накидывало пакетов больше, чем успевал разгребать Haproxy, и тогда начинались проблемы. Поэтому штука важная.
net.ipv4.tcp_max_syn_backlog – отвечает за лимит новых еще не установленных соединений, для которых был получен
SYN пакет. Если есть большой поток новых соединений (например, много HTTP запросов c Connection: close), есть смысл поднять это значение, чтобы не терять время на пересылке потерявшихся пакетов.net.core.somaxconn – тут уже речь про установленные соединения, но еще не обработанные приложением. Если сервер однопоточный, а к нему пришло два запроса, то первый запрос будет обработан функцией
accept(), а второй будет висеть в backlog, за размер которого и отвечает этот параметр.nf_conntrack_max – вероятно, самый известный из всех параметров. Думаю, почти каждый, кто имел дело с iptables, знает о нем. В идеале, конечно же, если вам не нужно использовать iptables masquerading, то можно выгрузить модуль conntrack и не думать об этом. В моем случае используется Docker, поэтому особо ничего не выгрузишь.
Мониторинг. Очевидный и не очень
Чтобы не искать вслепую, почему “ваша прокся тормозит”, будет полезно настроить пару графиков и обложить их триггерами.
nf_conntrack_count – самая очевидная метрика. По ней можно следить сколько соединений сейчас находится в conntrack таблице. При переполнении таблицы путь для новых соединений будет закрыт.
Текущее значение можно посмотреть здесь:
cat /proc/sys/net/netfilter/nf_conntrack_count
Tcp segments retransmited – количество пересылок сегментов. Метрика очень объемная, так как может говорить о проблемах на разных уровнях. Рост пересылок может свидетельствовать о проблемах с сетью, о необходимости оптимизации настроек системы или даже о том, что конечное ПО (например, Haproxy) не справляется со своей работой. Как бы там ни было, аномальный рост этого значения может служить поводом для разбирательств.
У нас чаще всего рост значений говорит о проблемах с одним из поставщиков, хотя случались проблемы и с производительностью как серверов, так и сети.
Пример для проверки:
netstat -s|grep 'segments retransmited'
Socket Recv-Q — помните, мы говорили о моментах, когда приложение может не успевать отрабатывать запросы, и тогда
socket backlog будет расти? Рост этого показателя совершенно ясно дает понять, что с приложением что-то не так и оно не справляется.Я лицезрел горы на графиках с этой метрикой, когда параметр maxconn в Haproxy имел значение по умолчанию (2000), и тот попросту не принимал новых соединений.
И снова пример:
ss -lntp|awk '/LISTEN/ {print $2}'
Еще не лишним будет иметь график с разбивкой по состояниям TCP соединений:
И отдельно вынести
time-wait/established, т.к. их значения, как правило, сильно отличаются от остальных:Помимо этих метрик есть множество других, но уже более очевидных – например, загруженность сетевого интерфейса или CPU. Их выбор будет уже больше зависеть от специфики вашей нагрузки.
Вместо заключения
В общем-то, на этом все – я постарался описать ключевые моменты, с которыми мне довелось столкнуться при настройке http reverse proxy. Казалось бы, задача не сложная, но с ростом нагрузки растет и количество подводных камней, которые всегда всплывают не вовремя. Надеюсь, эта статья поможет вам избежать тех сложностей, с которыми пришлось столкнуться мне.
Всем Peace

