
Временами бывает нужно отпрофилировать производительность программы или потребление памяти в программе на C++. К сожалению, зачастую это сделать не так просто как может показаться.
Здесь будут рассмотрены особенности профилирования программ с использованием инструментов valgrind и google perftools. Материал получился не очень структурированным, это скорее попытка собрать базу знаний «для личных целей», чтобы в будущем не приходилось судорожно вспоминать, «а почему не работает то» или «а как сделать это». Скорее всего, здесь будут затронуты далеко не все неочевидные случаи, если вам есть что добавить, пишите пожалуйста в комментарии.
Все примеры будут запускаться в системе linux.
Профилирование времени выполнения
Подготовка
Для разбора особенностей профилирования я буду запускать небольшие программки, как правило состоящие из одного main.cpp файла и одного файла func.cpp вместе с инклудом.
Компилировать их я буду компилятором g++ 8.3.0.
Так как профилировать неоптимизированные программы — довольно странное занятие, будем компилировать с опцией -Ofast, а для того, чтобы получить debug-символы на выходе, не забудем добавить опцию -g. Тем не менее, иногда вместо нормальных имен функций можно увидеть только невнятные адреса вызовов. Это значит, что произошла «рандомизация размещения адресного пространства». Это можно определить, вызывав команду nm на бинарнике. Если в большинство адресов выглядят примерно так 00000000000030e0 (большое количество нулей в начале), то скорее всего это оно. В нормальной программе адреса выглядят как 0000000000402fa0. Поэтому нужно добавить опцию -no-pie. В результате, полный набор опций будет выглядеть вот так:
-Ofast -g -no-pie
Для просмотра результатов будем использовать программу KCachegrind, который умеет работать с форматом отчетов callgrind
Callgrind
Первая утилита, которую мы сегодня рассмотрим — callgrind. Эта утилита входит в состав инструмента valgrind. Она эмулирует каждую исполняемую инструкцию программы и на основании внутренних метрик о «стоимости» работы каждой инструкции выдает нужное нам заключение. Из-за такого подхода иногда бывает так, что callgrind не может распознать очередую инструкцию и вываливается с ошибкой
Unrecognised instruction at address
Единственный выход из такой ситуации — пересмотреть все опции компиляции и попытаться найти мешающую
Давайте для тестирования этого инструмента создадим программу, состоящую из одной shared, и одной static библиотеки (в дальнейшем в других тестах от библиотек откажемся). Каждая библиотека, а также сама программа, будет предоставлять простенькую вычислительную функцию, например, вычисление последовательности Фибоначчи.
static_lib
////////////////// // static_lib.h // ////////////////// #ifndef SERVER_STATIC_LIB_H #define SERVER_STATIC_LIB_H int func_static_lib(int arg); #endif //SERVER_STATIC_LIB_H //////////////////// // static_lib.cpp // /////////////////// #include "static_lib.h" #include "static_func.h" #include <cstddef> int func_static_lib(int arg) { return static_func(arg); } /////////////////// // static_func.h // /////////////////// #ifndef TEST_PROFILER_STATIC_FUNC_H #define TEST_PROFILER_STATIC_FUNC_H int static_func(int arg); #endif //TEST_PROFILER_STATIC_FUNC_H ///////////////////// // static_func.cpp // ///////////////////// #include "static_func.h" int static_func(int arg) { int fst = 0; int snd = 1; for (int i = 0; i < arg; i++) { int tmp = (fst + snd) % 17769897; fst = snd; snd = tmp; } return fst; }
shared_lib
////////////////// // shared_lib.h // ////////////////// #ifndef TEST_PROFILER_SHARED_LIB_H #define TEST_PROFILER_SHARED_LIB_H int func_shared_lib(int arg); #endif //TEST_PROFILER_SHARED_LIB_H //////////////////// // shared_lib.cpp // //////////////////// #include "shared_lib.h" #include "shared_func.h" int func_shared_lib(int arg) { return shared_func(arg); } /////////////////// // shared_func.h // /////////////////// #ifndef TEST_PROFILER_SHARED_FUNC_H #define TEST_PROFILER_SHARED_FUNC_H int shared_func(int arg); #endif //TEST_PROFILER_SHARED_FUNC_H ///////////////////// // shared_func.cpp // ///////////////////// #include "shared_func.h" int shared_func(int arg) { int result = 1; for (int i = 1; i < arg; i++) { result = (int)(((long long)result * i) % 19637856977); } return result; }
main
////////////// // main.cpp // ////////////// #include <iostream> #include "static_lib.h" #include "shared_lib.h" #include "func.h" int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); std::cout << "result: " << func_static_lib(arg) << " " << func_shared_lib(arg) << " " << func(arg); return 0; } //////////// // func.h // //////////// #ifndef TEST_PROFILER_FUNC_H #define TEST_PROFILER_FUNC_H int func(int arg); #endif //TEST_PROFILER_FUNC_H ////////////// // func.cpp // ////////////// #include "func.h" int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; } return fst; }
Компилируем программу, и запускаем valgrind следующим образом:
valgrind --tool=callgrind ./test_profiler 100000000
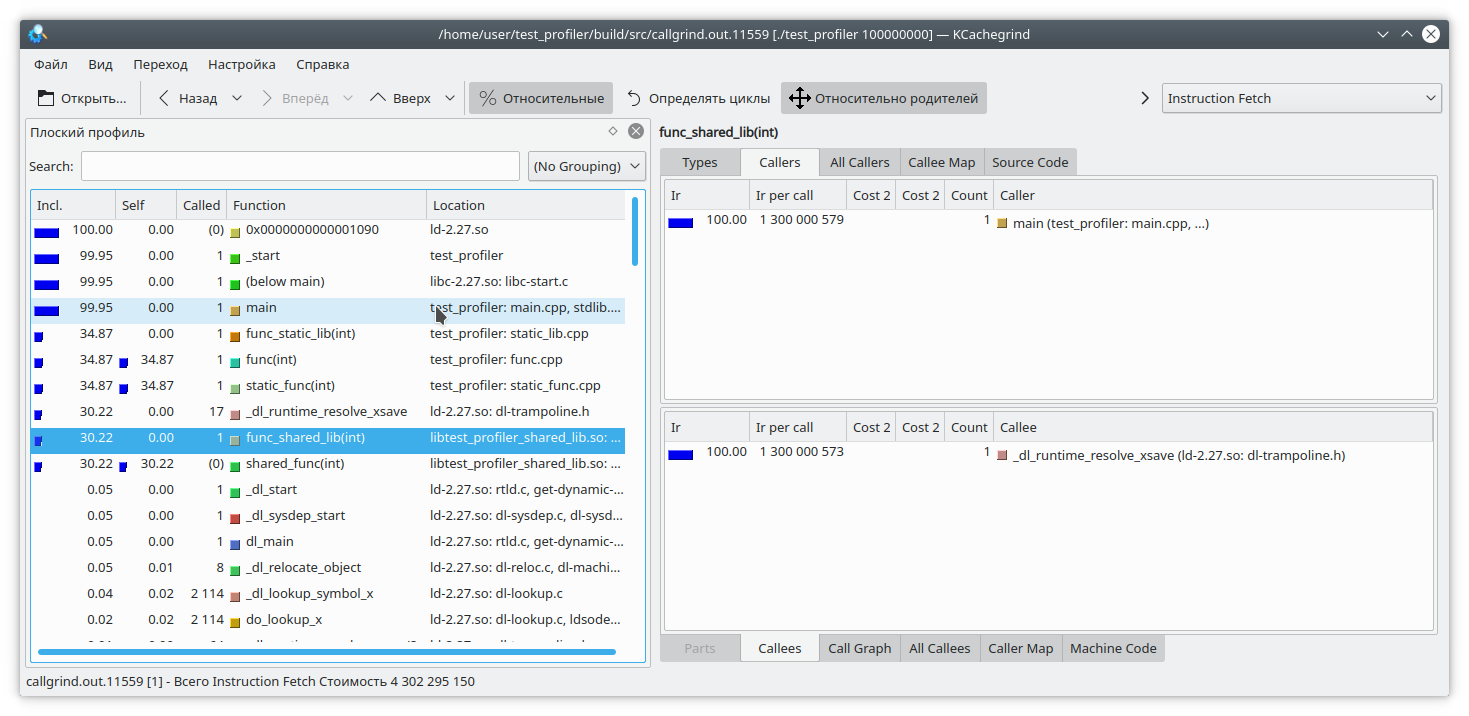
Видим, что для статической библиотеки и обычной функции результат похож на ожидаемый. А вот в динамической библиотеке callgrind не смог до конца отрезолвить функцию.
Для того, чтобы это исправить, при запуске программы нужно установить переменную LD_BIND_NOW в значение 1, вот так:
LD_BIND_NOW=1 valgrind --tool=callgrind ./test_profiler 100000000
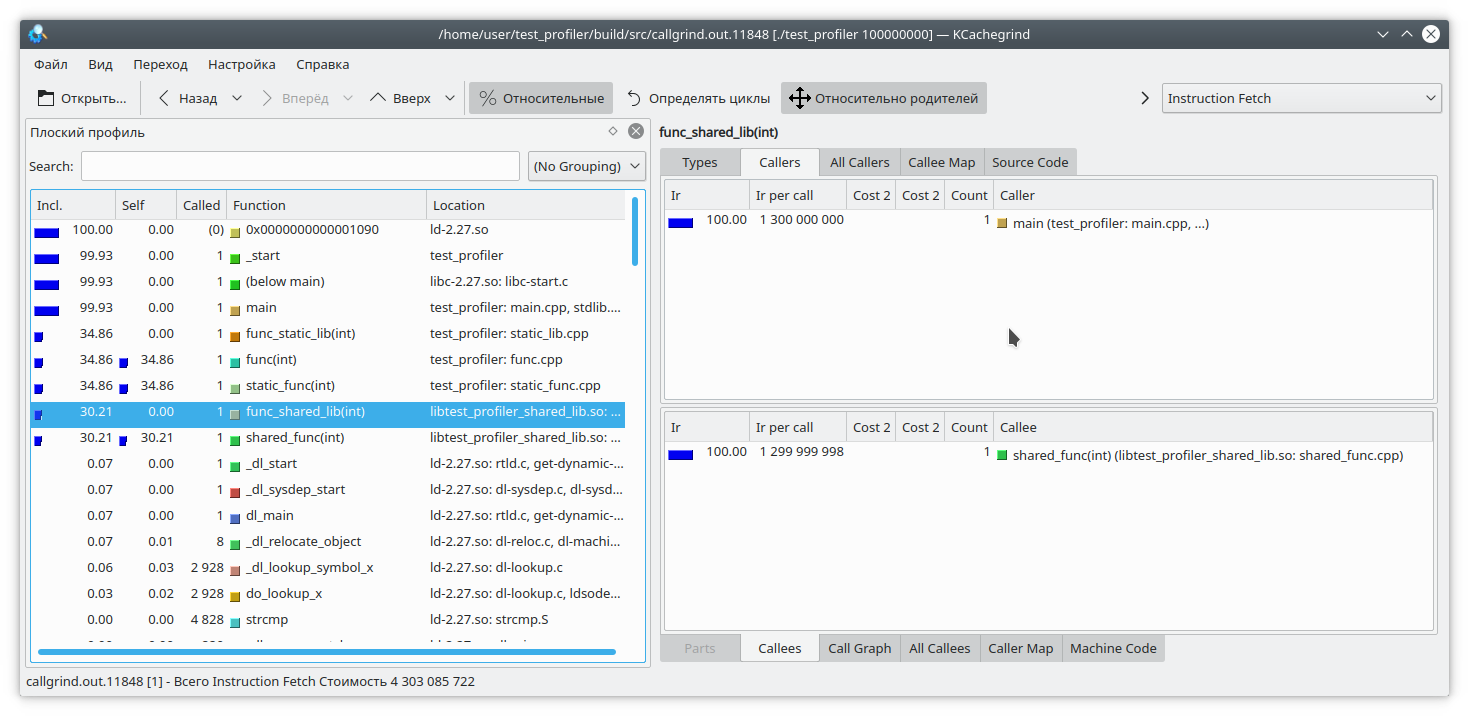
И теперь, как видите, все нормально
Следующая проблема callgrind-а, вытекающая из профилирования путем эмуляции инструкций в том, что выполнение программы сильно замедляется. Это может нести в себе неправильную относительную оценку времени выполнения различных частей кода.
Давайте рассмотрим такой код:
int func(int arg) { int fst = 1; int snd = 1; std::ofstream file("tmp.txt"); for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; std::string r = std::to_string(res); file << res; file.flush(); fst = snd; snd = res + r.size(); } return fst; }
Здесь я добавил на каждую итерацию цикла запись небольшого количества данных в файл. Так как запись в файл — довольно длительная операция, для противовеса я добавил на каждую итерацию цикла генерацию строки из числа. Очевидно, что в данном случае операция записи в файл занимает больше времени, чем вся остальная логика функции. Но callgrind считает по-другому:
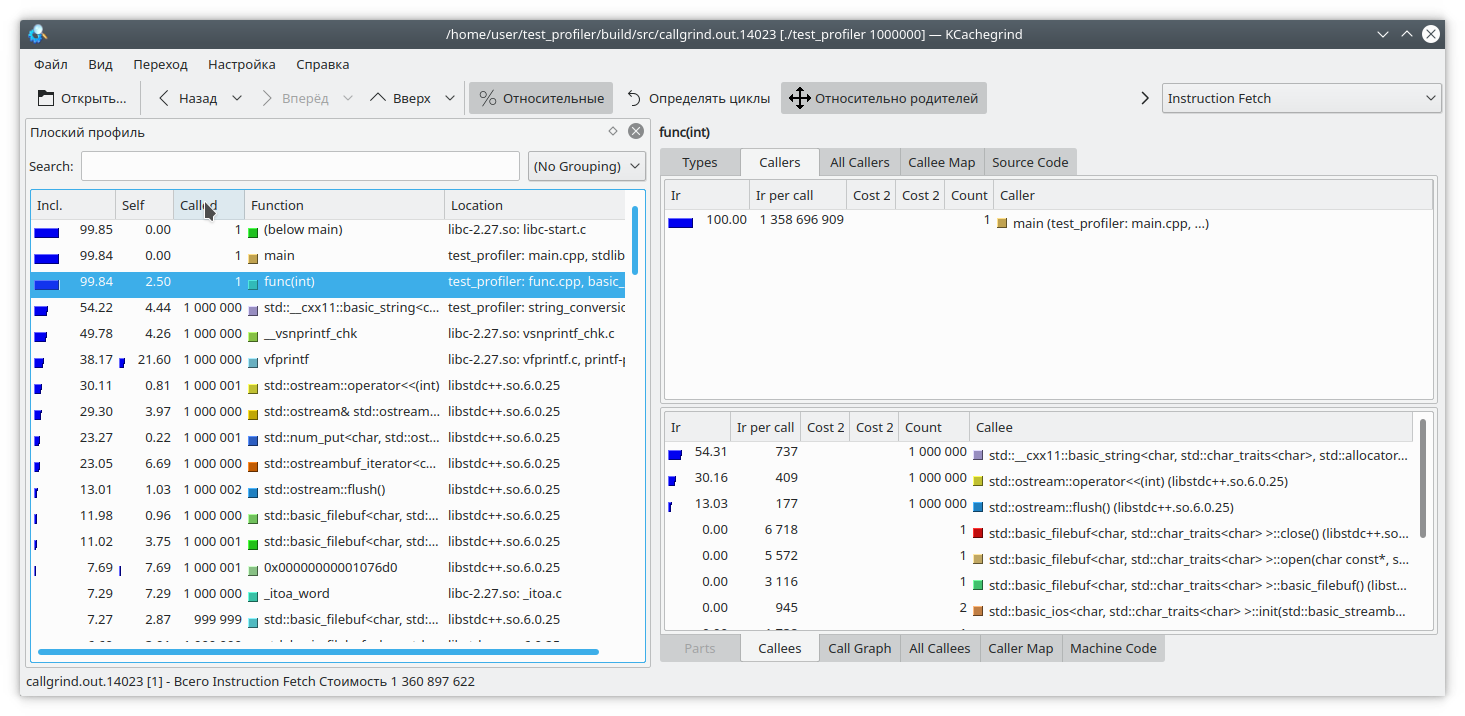
Также стоит учесть, что callgrind может измерять стоимость работы функции, только когда та работает. Функция не работает — значит, и стоимость не растет. Это усложняет отладку программ, которые время от времени входят в блокировку или работают с блокирующей файловой системой/сетью. Давайте проверим:
#include "func.h" #include <mutex> static std::mutex mutex; int funcImpl(int arg) { std::lock_guard<std::mutex> lock(mutex); int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; } return fst; } int func2(int arg){ return funcImpl(arg); } int func(int arg) { return funcImpl(arg); } int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); auto future = std::async(std::launch::async, &func2, arg); std::cout << "result: " << func(arg) << std::endl; std::cout << "second result " << future.get() << std::endl; return 0; }
Здесь мы вложили выполнение функции целиком в lock мьютекса, и вызвали эту функцию из двух разных потоков. Результат callgrind-а вполне предсказуем — он не видит проблемы в захвате мьютекса:
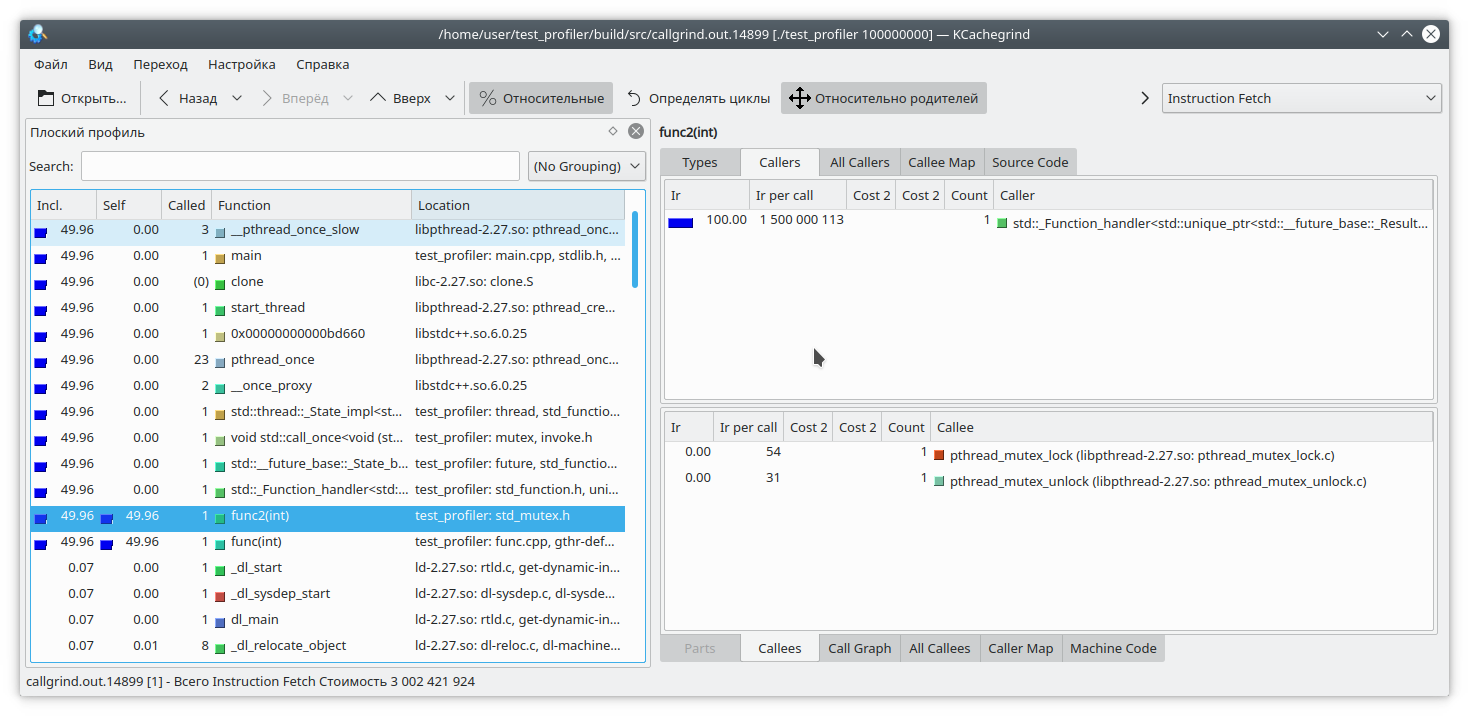
Итак, мы рассмотрели некоторые проблемы использования профилировщика callgrind. Давайте перейдем к следующему испытуемому — профилировщику из состава google perftools
google perftools
В отличие от callgrind, профилировщик от google работает по другому принципу.
Вместо того, чтобы анализировать каждую инструкцию исполняемой программы, он приостанавливает выполнение программы через равные промежутки времени и пытается определить, в какой функции в данный момент находится. В результате, это почти не влияет на производительность запущенного приложения. Но у такого подхода есть и свои слабые стороны.
Давайте для начала попробуем провести профилирование первой программы с двумя библиотеками.
Как правило, для запуска профилирования этой утилитой необходимо предзагрузить библиотеку libprofiler.so, выставить частоту сэмплирования и указать файл для сохранения дампа. К сожалению, профайлер требует, чтобы программа завершалась «своим ходом». Принудительное завершение программы приведет к тому, что дамп отчета просто не создастся. Это неудобно при профилировании долгоживущих программ, которые сами по себе не останавливаются, например демонов. Для обхода этого препятствия я создал такой скрипт:
gprof.sh
rnd=$RANDOM if [ $# -eq 0 ] then echo "./gprof.sh command args" echo "Run with variable N_STOP=true if hand stop required" exit fi libprofiler=$( dirname "${BASH_SOURCE[0]}" ) arg=$1 nostop=$N_STOP profileName=callgrind.out.$rnd.g gperftoolProfile=./gperftool."$rnd".txt touch $profileName echo "Profile name $profileName" if [[ $nostop = "true" ]] then echo "without stop" trap 'echo trap && kill -12 $PID && sleep 1 && kill -TERM $PID' TERM INT else trap 'echo trap && kill -TERM $PID' TERM INT fi if [[ $nostop = "true" ]] then CPUPROFILESIGNAL=12 CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" & else CPUPROFILE_FREQUENCY=1000000 CPUPROFILE=$gperftoolProfile LD_PRELOAD=${libprofiler}/libprofiler.so "${@:1}" & fi PID=$! if [[ $nostop = "true" ]] then sleep 1 kill -12 $PID fi wait $PID trap - TERM INT wait $PID EXIT_STATUS=$? echo $PWD ${libprofiler}/pprof --callgrind $arg $gperftoolProfile* > $profileName echo "Profile name $profileName" rm -f $gperftoolProfile*
Эту утилиту нужно запускать, передавая в качестве параметров имя исполняемого файла и список его параметров. Также, предполагается, что рядом со скриптом лежат необходимые ему файлы libprofiler.so и pprof. В случае, если программа долгоживущая и останавливается путем прерывания выполнения, необходимо установить переменную N_STOP в значение true, например так:
N_STOP=true ./gprof.sh ./test_profiler 10000000000
В конце работы скрипт сгенерирует отчет в любимом мною формате callgrind.
Итак, давайте запустим нашу программу под этим профилировщиком
./gprof.sh ./test_profiler 1000000000

В принципе, все довольно наглядно.
Как я уже сказал, гугловый профилировщик работает, останавливая выполнение программы и вычисляя текущую функцию. Как же он это делает? Делает он это путем раскрутки стека. А что, если в момент раскрутки стека программа сама раскручивала стек? Ну, очевидно, что ничего хорошего при этом не произойдет. Давайте это проверим. Напишем такую функцию:
int runExcept(int res) { if (res % 13 == 0) { throw std::string("Exception"); } return res; } int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; try { res = runExcept(res); } catch (const std::string &e) { res = res - 1; } fst = snd; snd = res; } return fst; }
И запустим профилирование. Программа довольно быстро зависнет.
Есть и другая проблема, связанная с особенностью работы профайлера. Предположим, мы сумели раскрутить стек, и теперь нам нужно сопоставить адреса с конкретными функциями программы. Это может быть очень нетривиально, так как в C++ довольно большое количество функций инлайнится. Давайте посмотрим на таком примере:
#include "func.h" static int func1(int arg) { std::cout << 1 << std::endl; return func(arg); } static int func2(int arg) { std::cout << 2 << std::endl; return func(arg); } static int func3(int arg) { std::cout << 3 << std::endl; if (arg % 2 == 0) { return func2(arg); } else { return func1(arg); } } int main(int argc, char **argv) { if (argc != 2) { std::cout << "Incorrect args"; return -1; } const int arg = std::atoi(argv[1]); int arg2 = func3(arg); int arg3 = func(arg); std::cout << "result: " << arg2 + arg3; return 0; }
Очевидно, что если запустить программу например вот так:
./gprof.sh ./test_profiler 1000000000
то функция func1 никогда не вызовется. Но профайлер считает по-другому:
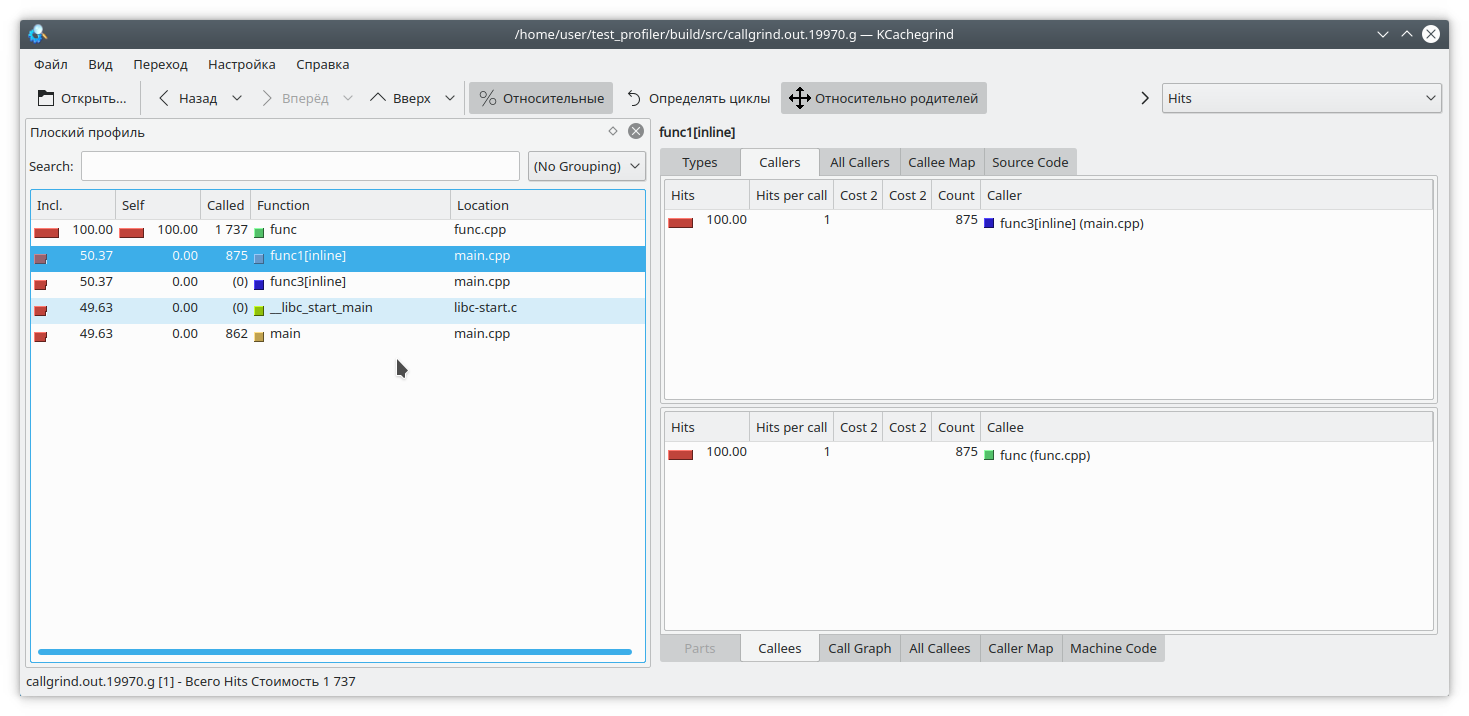
(К слову, valgrind здесь решил скромно промолчать и не уточнять, из какой конкретной функции пришел вызов).
Профилирование памяти
Нередко возникают ситуации, когда память из приложения куда-то «течет». Если это связано с отсутствием очистки ресурсов, то для выявлении проблемы должен помочь Memcheck. Но в современном C++ не так сложно обойтись без ручного управления ресурсами. unique_ptr, shared_ptr, vector, map делают манипулирование «голыми» указателями бесмыссленными.
Тем не менее, и в таких приложениях память бывает что течет. Как это происходит? Довольно просто, как правило это чтото вроде «положил значение в долгоживущий map, а удалить забыл». Давайте попробуем отследить эту ситуацию.
Для этого перепишем нашу тестовую функцию таким образом
#include "func.h" #include <deque> #include <string> #include <map> static std::deque<std::string> deque; static std::map<int, std::string> map; int func(int arg) { int fst = 1; int snd = 1; for (int i = 0; i < arg; i++) { int res = (fst + snd + 1) % 19845689; fst = snd; snd = res; deque.emplace_back(std::to_string(res) + " integer"); map[i] = "integer " + std::to_string(res); deque.pop_front(); if (res % 200 != 0) { map.erase(i - 1); } } return fst; }
Здесь мы на каждой итерации добавляем в мапу некоторые элементы, и совершенно случайно (правда-правда) забываем их оттуда иногда удалить. Также, для отвода глаз мы немного мучаем std::deque.
Отлавливать утечки памяти мы будем двумя инструментами — valgrind massif и google heapdump.
Massif
Запускаем программу такой командой
valgrind --tool=massif ./test_profiler 1000000
И видим что-то наподобие
Massif
time=1277949333 mem_heap_B=313518 mem_heap_extra_B=58266 mem_stacks_B=0 heap_tree=detailed n4: 313518 (heap allocation functions) malloc/new/new[], --alloc-fns, etc. n1: 195696 0x109A69: func(int) (new_allocator.h:111) n0: 195696 0x10947A: main (main.cpp:18) n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25) n1: 72704 0x4010731: _dl_init (dl-init.c:72) n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so) n1: 72704 0x0: ??? n1: 72704 0x1FFF0000D1: ??? n0: 72704 0x1FFF0000E1: ??? n2: 42966 0x10A7EC: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (new_allocator.h:111) n1: 42966 0x10AAD9: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466) n1: 42966 0x1099D4: func(int) (basic_string.h:1932) n0: 42966 0x10947A: main (main.cpp:18) n0: 0 in 2 places, all below massif's threshold (1.00%) n0: 2152 in 10 places, all below massif's threshold (1.00%)
Видно, что massif смог обнаружить утечку в функции, но пока не понятно где. Давайте пересоберем программу с флагом -fno-inline и запустим анализ еще раз
massif
time=3160199549 mem_heap_B=345142 mem_heap_extra_B=65986 mem_stacks_B=0 heap_tree=detailed n4: 345142 (heap allocation functions) malloc/new/new[], --alloc-fns, etc. n1: 221616 0x10CDBC: std::_Rb_tree_node<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >* std::_Rb_tree<int, std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::_Select1st<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_create_node<std::piecewise_construct_t const&, std::tuple<int const&>, std::tuple<> >(std::piecewise_construct_t const&, std::tuple<int const&>&&, std::tuple<>&&) [clone .isra.81] (stl_tree.h:653) n1: 221616 0x10CE0C: std::_Rb_tree_iterator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > std::_Rb_tree<int, std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::_Select1st<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::_M_emplace_hint_unique<std::piecewise_construct_t const&, std::tuple<int const&>, std::tuple<> >(std::_Rb_tree_const_iterator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::piecewise_construct_t const&, std::tuple<int const&>&&, std::tuple<>&&) [clone .constprop.87] (stl_tree.h:2414) n1: 221616 0x10CF2B: std::map<int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::less<int>, std::allocator<std::pair<int const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >::operator[](int const&) (stl_map.h:499) n1: 221616 0x10A7F5: func(int) (func.cpp:20) n0: 221616 0x109F8E: main (main.cpp:18) n1: 72704 0x52BA414: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.25) n1: 72704 0x4010731: _dl_init (dl-init.c:72) n1: 72704 0x40010C8: ??? (in /lib/x86_64-linux-gnu/ld-2.27.so) n1: 72704 0x0: ??? n1: 72704 0x1FFF0000D1: ??? n0: 72704 0x1FFF0000E1: ??? n2: 48670 0x10B866: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:317) n1: 48639 0x10BB2C: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace(unsigned long, unsigned long, char const*, unsigned long) (basic_string.tcc:466) n1: 48639 0x10A643: std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > std::operator+<char, std::char_traits<char>, std::allocator<char> >(char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&&) [clone .constprop.86] (basic_string.h:6018) n1: 48639 0x10A7E5: func(int) (func.cpp:20) n0: 48639 0x109F8E: main (main.cpp:18) n0: 31 in 1 place, below massif's threshold (1.00%) n0: 2152 in 10 places, all below massif's threshold (1.00%)
Теперь ясно видно, где утечка — в добавлении элемента map-ы. Massif умеет определять короткоживущие объекты, поэтому манипуляции с std::deque в этом дампе незаметны.
Heapdump
Для работы google heapdump необходимо прилинковать или предзагрузить библиотеку tcmalloc. Эта библиотека подменяет стандартные функции выделения памяти malloc, free,… Также она умеет собирать информацию об использовании этих функций, чем мы и воспользуемся при анализе программы.
Так как этот метод работает очень неторопливо (даже по сравнению с massif-ом), рекомендую сразу отключить при компиляции встраивание функций опцией -fno-inline. Итак, пересобираем наше приложение и запускаем с командой
HEAPPROFILESIGNAL=23 HEAPPROFILE=./heap ./test_profiler 100000000
Здесь предполагается, что библиотека tcmalloc прилинкована к нашему приложению.
Теперь, выжидаем некоторое время, необходимое для образования заметной утечки, и посылаем нашему процессу сигнал 23
kill -23 <pid>
В результате появляется файл с именем heap.0001.heap, который мы конвертируем в callgrind формат командой
pprof ./test_profiler "./heap.0001.heap" --inuse_space --callgrind > callgrind.out.4
Обратите также внимание на опции pprof-а. Можно выбирать из опций inuse_space, inuse_objects, alloc_space, alloc_objects, которые показывают находящиеся в использование пространство или объекты, или выделенное за все время работы программы пространство и объекты соответственно. Нас интересует опция inuse_space, которая показывает используемое в настоящее время пространство памяти.
Открываем наш любимый kCacheGrind и видим
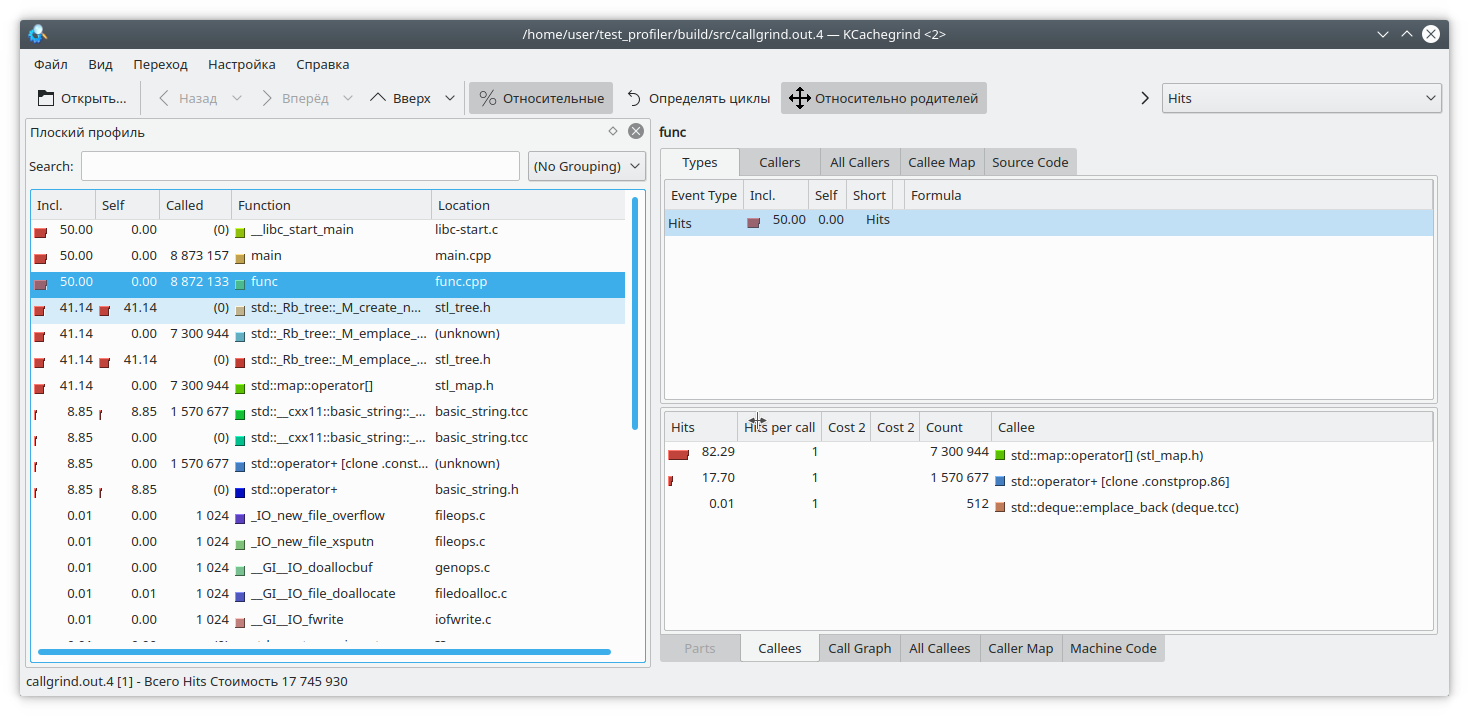
std::map «выел» слишком много памяти. Наверное утечка в нем.
Выводы
Профилирование на C++ — очень непростая задача. Здесь нам придется бороться с инлайнингом функций, неподдерживаемыми инструкциями, некорректными результатами и т.д. Не всегда можно доверять результатам работы профилировщика.
Кроме предложенных выше функций, есть и другие инструменты, предназначенные для профилирования — perf, intel VTune и другие. Но и они проявляют некоторые из указанных недочетов. Поэтому не стоит забывать и о «дедушкином» способе профилирования путем замера времени выполнения функций и выводе его в лог.
Также, если у вас есть интересные приемы профилирования кода, прошу выкладывать их в комментариях

