
Прошел почти год с тех пор, как мы опубликовали на GitHub библиотеку для машинного обучения NeoML. О чем, конечно же, была статья на Хабре. Мы обещали поддерживать и развивать ее. Свое обещание мы сдержали, и на днях свет увидела вторая версия библиотеки!
С первой версии в жизни проекта произошло много интересного: мы продолжили разработку на GitHub, освоили Azure DevOps для регулярных сборок, поддержали новые платформы, добавили немало новых и не столь новых, но очень нужных алгоритмов, добавили производительности и — самое главное — сделали для библиотеки Python интерфейс! Собственно, после окончания работ над Python оберткой библиотека и получила номер версии 2.0.
Ниже я подробнее расскажу о том, как это все происходило.
Open source/GitHub/Azure DevOps
Перенос разработки на GitHub был для нас смелым шагом, так как внутри компании уже устоялся процесс ведения проектов с помощью Azure DevOps: репозитории, пайплайны, багтрекер, менеджер задач и т. д. – все это пришлось так или иначе менять.
Прежде всего мы переживали за доступность кода. В компании ежедневно идут сотни автоматических сборок, так или иначе использующих код NeoML. Как поведет себя GitHub понимания не было. Поначалу мы даже сделали “зеркало” для внутренних сборок, из которого и предлагалось брать код. Но как-то сами собой все начали брать код напрямую с GitHub. Причем за это время нам не известно ни об одной сборке, упавшей по вине GitHub. Так что полет нормальный!
Сборка самой библиотеки тоже изменилась. Поднимает версии, ставит теги и собирает внутреннюю версию библиотеки по-прежнему локальный пул серверов. Однако проверка собираемости мастера, оберток и pull request’ов происходит в облаке. С этим пришлось изрядно повозиться, но наши DevOps’ы справились, и теперь для регуляных сборок и проверки собираемости pull reguest’ов мы используем Azure, а именно – его бесплатную функциональность для сборки opensource-проектов. О чем на главной странице репозитория на GitHub говорят (чаще всего зеленые) бейджи:

Остальное уже было не так существенно. Но некоторые неудобства все-таки были. Например, просмотрщик pull request'ов в GitHub, на наш взгляд, уступает аналогу из Azure DevOps, ревью делать в нем не так удобно. Багтрекер с GitHub так и не прижился, так как на локальном в компании построено много процессов, и интегрировать в них другой сервис непросто. Возможно, в будущем мы исправим это и сделаем процесс разработки более открытым, но пока менеджерские задачи ведутся локально.
В целом можно сказать, что процесс идет успешно и связка GitHub + Azure DevOps работает хорошо. Сама же идея сделать библиотеку открытой себя более чем оправдала! Мы получили много отзывов и интересных предложений, которые помогли нам стать лучше. И, что особенно приятно, мы нашли единомышленников, которые в итоге помогли нам создать Python обертку.
Python
Тема создания Python обертки бесспорно достойна отдельной статьи, и очень может быть, что она скоро появится. Сейчас же постараюсь кратко рассказать, как мы это делали и с какими проблемами столкнулись.
На вопрос, зачем нужен Python интерфейс для современной ML-библиотеки, сейчас уже отвечать не нужно. Python уже давно стал стандартом в этой области. Скорее интересно, почему у нас он появился только сейчас. Развернутый ответ на этот вопрос можно найти в первой статье про библиотеку.
В итоге, сэкономленные на развитии механизмов конвертации моделей из форматов других Python библиотек ресурсы было решено направить на создание собственного Python решения. И таким образом перенести все обучение моделей в ABBYY на NeoML. Использование других фреймворков сохранилось только на этапе экспериментов.
Способы создания обертки
Как же правильно делать Python обертку для C/C++ кода? В этом направлении существует немало решений: можно использовать ctype и сделать С-обертку для С++ интерфейса написать свой модуль, используя “чистый” Python/C API, или использовать «помощников» типа cffi, cython или pybind11. Мы выбрали последнее.
Cffi отмели сразу, так как он только для C. Pybind11 же показался проще и гибче cython из-за использования C++ при написании модуля расширения. Также в пользу pybind11 сыграло то, что он использовался в других крупных ML-проектах. В итоге мы ни разу не разочаровались в pybind11. Библиотека оказалась простой, понятной и удобной, с нормальной документацией и примерами.
Pybind11
Pybind11 — это легковесная header-only библиотека, позволяющая использовать С++ в Python и наоборот. Главным образом она используется для создания Python оберток существующего C++ кода. Прародителем pybind11 был Boost.Python, но pybind11 проще и не имеет зависимостей. Вообще, про pybind11 и то, почему она хороша, написано много статей в том числе и на Хабре, например, тут. Поэтому я просто расскажу, что именно мы из нее использовали.
Pybind11 создает модуль расширения для Python и в нем оборачивает существующий С++ код. Мы описали такой модуль и в нем экспортировали необходимые функции и классы из наших С++ библиотек. Наш код сообщает об ошибках через STL исключения и использует STL типы, соответственно, пригодилась встроенная поддержка STL. Также пригодилась встроенная поддержка типов библиотеки NumPy, поддержка buffer protocol и pickle. Неожиданным оказалось то, что для удобной и функциональной обертки понадобятся еще и вызовы Python из C++, но и это тоже в библиотеке тоже имелось. В общем, все, что нам было нужно для реализации идей и представлений об обертке в pybind11, было в наличии.
Идея обертки
Для нас было важно, чтобы обертка оставалась именно оберткой. Это значит, что в Python не должно быть никакой ML-логики, только то, что необходимо для реализации адекватного Python интерфейса. Также крайне желательно, чтобы С++ часть ничего «не знала» о существовании Python интерфейса! Это наш основной сценарий использования библиотеки, и очень не хотелось бы, чтобы на него что-то повлияло.
В итоге наша обертка получилась двухуровневой.
Первый уровень — это сгенерированный pybind11 код. Здесь почти для каждой экспортируемой из С++ библиотек сущности существует pybind11 обертка. Цель обертки — владеть С++ сущностью и разбирать/создавать «упрощенные» Python/pybind11 объекты, типа py::list, py::dict, py::array и т. д., передаваемые на вход и выдаваемые на выход.
Пример функции первого уровня:
class CPyBlob { public: ... private: CPtr<CPyMathEngineOwner> mathEngineOwner; CPtr<CDnnBlob> blob; // C++ сущность. }; py::class_<CPyBlob>(m, "Blob", py::buffer_protocol()) .def( py::init([]( const CPyBlob& blob ) { return CPyBlob( blob.MathEngineOwner(), blob.Blob() ); }) ) ... ; m.def("tensor", []( const CPyMathEngine& mathEngine, const py::array& shape, const std::string& blobTypeStr ) { const int* shapePtr = reinterpret_cast<const int*>( shape.data() ); TBlobType blobType = CT_Invalid; if( blobTypeStr == "int32" ) { blobType = CT_Int; } else if( blobTypeStr == "float32" ) { blobType = CT_Float; } return CPyBlob( mathEngine, blobType, shapePtr ); });
Оказалось, что для создания удобного и функционального Python интерфейса этого мало. Так появился уровень два.
Второй уровень — это чисто Python код, классы, агрегирующие сущности первого уровня. Цель этого уровня — разбирать Python параметры в «упрощенные», принимаемые на вход уровнем 1, проверять их правильность и выдавать адекватную диагностику. Дело в том, что в С++ библиотеке правильность входных параметров проверяется ассертами, а такую диагностику использовать в Python крайне неудобно. Также на втором уровне написаны комментарии ко всем доступным в Python сущностям. В принципе, все это можно было бы сделать и на уровне pybind11, но нам показалось, что написать это на Python проще и «правильнее», чем на С++.
Пример функции второго уровня:
def tensor(math_engine, shape, dtype="float32"): """Creates a blob of the specified shape. ... """ if dtype != "float32" and dtype != "int32": raise ValueError('The `dtype` must be one of {`float32`, `int32`}.') shape = numpy.array(shape, dtype=numpy.int32, copy=False) ... return Blob(PythonWrapper.tensor(math_engine._internal, shape, dtype))
В итоге, данную функцию можно вызвать из Python кода пользователя, например, так:
math_engine = neoml.MathEngine.CpuMathEngine(4) shape = (10, 1, 1, 1, 32, 32, 3) float_blob = neoml.Blob.tensor(math_engine, shape, "int32")
Что получилось
В результате у нас получилась полнофункциональная Python обертка. Все классы и функции, за исключением тех, для которых мы решили, что в Python они не нужны или для которых в Python существуют общепринятые аналоги, доступны через новый интерфейс. Python обертка использует ту же версию бинарников, что и C++. Для нее не требуется какая-либо условная компиляция или специальные настройки в рантайме.
Разумеется, интерфейс поддерживает различные сущности библиотеки NumPy, без которых в современном ML уже никуда. С помощью них мы заменили самописные примитивы, которые использовали в C++, например, CSparseFloatVector, CSparseFloatMatrix и т.д. Также наши блобы поддерживают buffer protocol, благодаря чему преобразования из NumPy и обратно происходят без потери данных. Приятно, что pybind11 обеспечивает простую поддержку и NumPy типов, и buffer protocol.
Как уже оговаривалось выше, обработка корректности входных параметров происходит в Python части. Однако ошибки, которые выявляются во время исполнения сети, диагностируются с помощью STL исключений, что благодаря pybind11 дает вполне адекватный вид диагностики. К тому же оказалось не лишним проанализировать все такие ошибки и сделать их описания более подробными.
Python версия библиотеки полностью совместима с C++ версией. Любая модель, использующая стандартные сущности библиотеки, может быть загружена и использована в С++ версии, и наоборот. Для этого в Python части доступны методы сериализации во внутренний формат библиотеки. Существует только ограничение, касающееся самописных слоев. Пока общего механизма их использования в обоих интерфейсах мы не предоставляем. В Python же создание собственных слоев, за исключением слоев, реализующих функции потерь, пока недоступно. Мы продолжаем изучать этот вопрос, но в наших текущих сценариях такой необходимости пока нет.
Что касается реализации собственных функций потерь, во второй версии появился механизм autodiff, заметно упрощающий их реализацию. Раньше вычисление градиентов для каждой функции потерь приходилось писать вручную, используя возможности вычислительного движка, теперь же это делается автоматически. Пока список функций не такой большой, но по мере надобности будет расширяться.
Помимо сериализации во внутренний формат, доступна и стандартная для Python pickle сериализация. Обученная модель сохраняется и загружается через pickle, даже если она использует самописные функции потерь. Тут опять помогают макросы из pybind11.
Отдельным вопросом стало написание документации для нового интерфейса. Мы решили использовать сервис readthedocs.org, предоставляющий бесплатную функциональность по автогенерации и хостингу справки для опенсорс-проектов. Сервис оказался довольно удобным: наша справка из мастера автоматически подтянулась сюда neoml.readthedocs.io, а на GitHub появился бейдж о статусе ее сборки.
Выводы
Появление Python интерфейса для NeoML позволило расширить область применения библиотеки. Благодаря этому закрылись многие сценарии использования сторонних ML-фреймворков в компании, тем самым упростив и оптимизировав работу наших инженеров. На Python проще осваивать библиотеку и ставить эксперименты.
Создание нового интерфейса к библиотеке вынудило нас по-новому, более критично, посмотреть на существующий и исправить много огрехов, таких как недостаточная диагностика или нехватка функциональности. Да и в целом это был интересный творческий процесс, от которого мы все получили немало удовольствия.
Как я уже сказал, обертку мы делали не одни. Незаменимую помощь в ее создании оказали разработчики из некоммерческой организации DuckStax и лично Александр Боргардт, за что им огромное спасибо!
Пакет нашей библиотеки можно найти в PyPi. Доступны версии для Python 3.6-3.9, работающие на Windows, Linux и macOS.
Новые платформы
За время, прошедшее с выхода первой версии, изменились сценарии и целевые платформы библиотеки. Для нас все важнее становится Linux. Поэтому теперь поддержка Windows и Linux равноправная. В частности, было поддержано обучение на GPU под Linux. Что касается GPU, мы подняли версию CUDA до 11.2, так как в версии 10.2 была ограничена поддержка новых карт серии 30. Замедление доходило до 5 раз.
Вот некоторая выдержка из тех замеров. Здесь представлено время умножения матриц библиотекой cuBlas на различных картах и версиях CUDA:

Без обновлений не обошлась и работа на CPU. Компания Apple начала использовать новые процессоры архитектуры ARM. А значит, в срочном порядке понадобилась реализация вычислительного движка для новой платформы. К счастью, наша реализация для Android CPU с незначительными изменениями отлично подошла, и мы получили работающее решение всего за несколько дней, которые главным образом ушли на настройку сборки.
Новая функциональность
Не только новые платформы, но и новые методы машинного обучения появились в нашем арсенале.
Классические методы
Наконец-то дошли руки пересмотреть реализацию кластеризации. В KMeans, помимо наивного Lloyd алгоритма, появился Elkan, добавлены новые методы инициализации кластеров и, конечно, поддержка многопоточности, а некоторые вычисления теперь выполняются функциями вычислительного движка. Также все алгоритмы кластеризации теперь принимают данные в dense формате, а не только в sparse, как раньше. Все это привело к ускорению кластеризации на порядок.
Алгоритмы классификации и регрессии практически не изменились, однако все методы по аналогии с кластеризацией принимают dense-данные. Плюс, методы классификации теперь поддерживают внутри себя мультиклассовую классификацию. Причем не только методом «один против всех», но и новым методом «каждый против каждого».
Для мультиклассовой классификации в градиентном бустинге деревьев появился новый алгоритм! Для выполнения классификации он использует один ансамбль, а не N, как в классическом случае. Только в листах деревьев этого ансамбля лежат векторы ответов для N классов. Такой ансамбль, очевидно, дает ниже качество, но при увеличении количества деревьев в некоторых задачах можно выйти на исходные показатели. Главный же плюс этого метода в ускорении предсказания, так как теперь вместо N деревьев нужно найти лист только в одном. И если количество деревьев для получения нужного качества не сильно больше исходного, можно получить солидный прирост производительности! Еще для градиентого бустинга было добавлено компактное представление модели, которое сократило размеры модели в памяти до двух раз.
Новое в нейронных сетях
В нейронных сетях появилось около десятка новых слоев. В основном это развитие идеи рекуррентных слоев или альтернатива им. Так в библиотеке появились следующие слои:
· Quasi-recurrent neural network (CQrnnLayer);
· Identity recurrent neural network (CIRnnLayer);
· Independently recurrent neural network (CIndRnnLayer).
Основной идеей этих методов является сокращение вычислений, производимых в рекуррентной части, для повышения производительности на GPU. Также расширена поддержка трансформеров добавлением реализации Multihead Attention (CMultiheadAttentionLayer).
Добавилось несколько разноплановых слоев: активация (GELULayer), пулинг (CProjectionPoolingLayer) и работа с эмбеддингами (CTiedEmbeddingsLayer, CPositionalEmbeddingLayer) — все это для решения современных NLP-задач.
У нас даже появился один новый солвер — LAMB, который также дал положительные результаты в NLP.
Оптимизация
Python, новые платформы и новые алгоритмы — это хорошо, но не стоит забывать и об улучшении производительности существующего кода. И мы стараемся не забывать, потому дальше я расскажу, что было сделано на этом поприще со времен первой версии. Разумеется, с графиками и таблицами.
Ускорение k-means
Как уже было сказано, за счет использования функций вычислительного движка при реализации алгоритма k-means было получено значительное ускорение. Реализация этого алгоритма в первой версии библиотеки была достаточно наивной, и сравнивать производительность с ней не имеет большого смысла. Поэтому здесь приведем сравнения с реализацией этого метода из библиотеки scikit-learn на различных датасетах. Благо, теперь у нас есть Python интерфейс, чтобы сделать это в одинаковых условиях.
Время работы k-means из scikit-learn и NeoML:

AVX2 модуль
В библиотеке появился отдельный подмодуль вычислительного движка, реализующий вычисления с использованием инструкций из набора AVX2. В него вынесены реализации специфических операций свертки. Отдельный модуль позволяет не требовать от библиотеки сборки под конкретную платформу, а использовать общую сборку, «на лету» определять возможности процессора и использовать для него наиболее подходящий код. Благодаря созданию этого модуля нам удалось ускорить инференс некоторых сверточных архитектур до 30%!
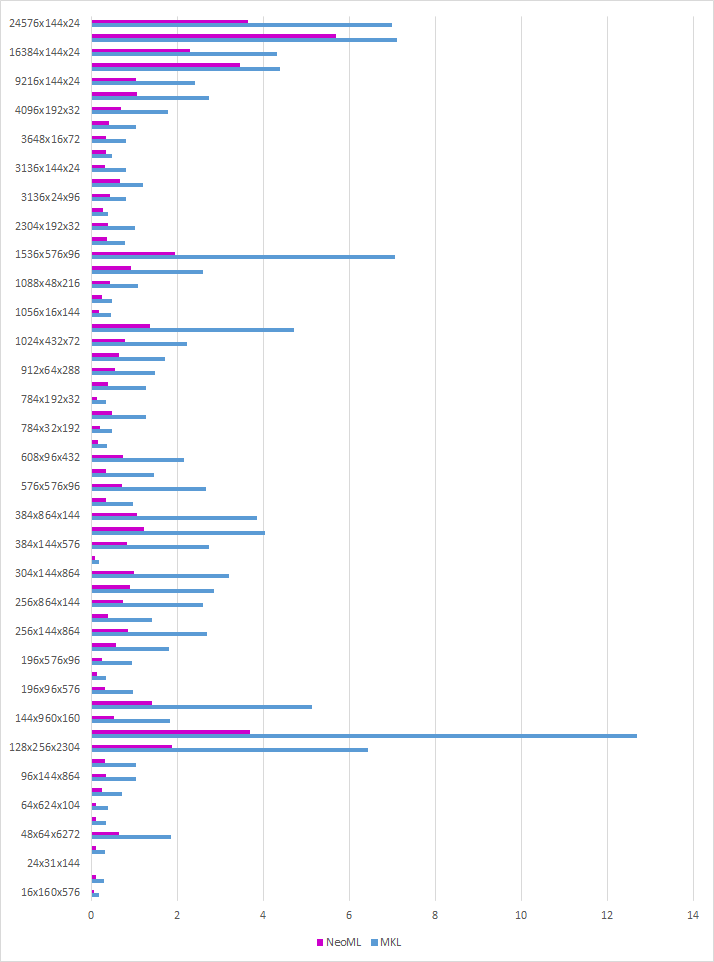
Оптимизация для AMD
Библиотека MKL (Intel Math Kernel Library) не оптимально работает на процессорах компании AMD. Судя по всему, такой процессор определяется как обладающий минимальным набором команд, и далее все вычисления идут с использованием максимум SSE. Хотя он, конечно, может гораздо больше.
Мы адаптировали нашу реализацию матричного умножения для ARM, написав ядра на AVX2. И теперь используем ее при работе на процессорах AMD. В результате получилось ускорить некоторые сети до двух раз!
Сравнение времени матричного умножения в NeoML и MKL на процессоре AMD Zen 2:
Замеры производительности NN с другими фреймворками
Ну и, конечно, мы держим руку на пульсе относительно производительности в сравнении с аналогами. Ниже предоставлены сравнительные замеры обучения и прямого прохода сетей на различных библиотеках:
Архитектура CAN:

Архитектура MobileNetV2:

Для тестов использовались следующие версии библиотек:
— torch версии 1.8.1 + cuda11;
— tensorflow версии 2.5.0 (если указано *, то tensorflow был скомпилирован вручную с более широкой поддержкой AVX и AVX2, иначе — взят из PyPI).
Что дальше
Дальше продолжаем работать в том же темпе! Из существенных задумок в ближайшее время мы хотим заняться распределенным обучением и JIT-компиляцией. Конечно, продолжим дорабатывать Python интерфейс, чтобы сделать его более функциональным и удобным. Вероятно, добавим реализации новых методов и точно будем оптимизировать старые. В оптимизации еще много интересных задач. Например, AVX512 вычисления, которые особенно актуальны при работе в облаках.
В общем, работы еще много. Надеемся, что у нас все получится, и следующие версии библиотеки будут еще удобнее и быстрее! Скачивайте библиотеку NeoML 2.0 из PyPi и заходите к нам на GitHub. Будем рады любым отзывам и предложениям!

