Всем привет.
Написал многопользовательский менеджер задач с веб интерфейсом. Кому интересно, прошу.
Назвал это произведение «Zmey».
Пока выглядит конечно по-спартански, и до Airflow далеко в плане фич.
Реализован такой базовый функционал:
В этой статье хочу сделать не большой обзор системы, более подробное описание будет на страничке проекта (находится в процессе).
Сейчас посмотрим общую схему ПО, и далее поговорим о каждом модуле системы.
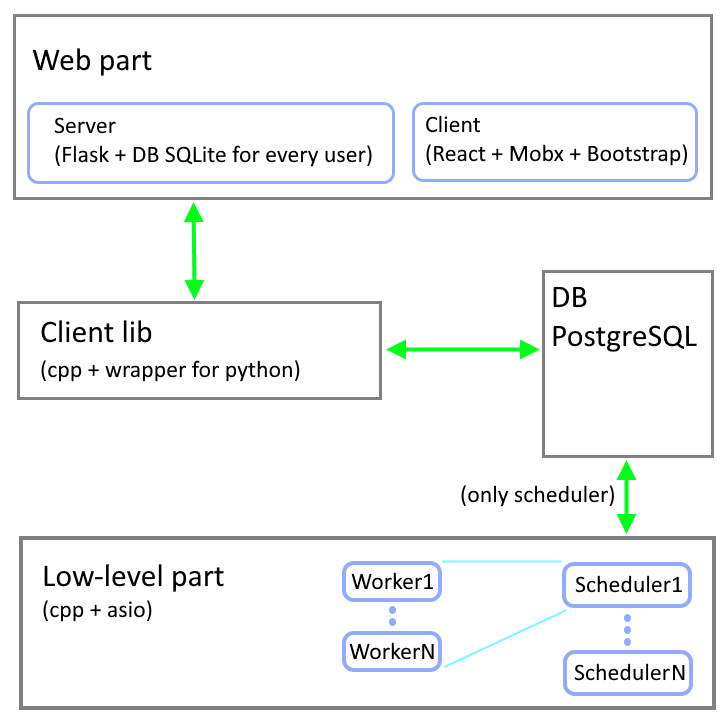
Система на низком уровне состоит из базы данных (PostgreSQL выбрана), планировщика задач `zmscheduler` (далее шедулер) и исполнителя задачи `zmworker` (далее воркер). Написаны на плюсах, из зависимостей только asio (без буста).
Бэкенд написан на Python с помощью вэб-фреймворка Flask. С низким уровнем общается через клиент `zmclient` (написан на плюсах с си-интерфейсом) + обертка для вызова из питона.
Для каждого пользователя при регистрации создается вспомогательная БД sqlite для сохранения инфраструктуры задач и текущего состояния интерфейса.
Фронтенд это SPA приложение на базе React + Mobx, оформление Boostrap, и админка
для создания шедулеров и воркеров (js без реакта).
Общение между фронтом и бэком построено на базе RestAPI.
Задача — это скрипт на любом языке (в основном конечно предполагается 'bash' либо 'Python', на Windows 'cmd' может быть).
На рабочей машине запущен воркер, который выполняет скрипт задачи путем запуска дочернего процесса. Вывод дочернего процесса является результатом выполнения задачи. Каждый воркер может одновременно выполнять несколько задач (конфигурируемый параметр).
Задачи для воркера поставляет шедулер.
В обязанности шедулера входит:
— получение новых задач из БД,
— выбор доступного воркера, и отправка ему задачи
— получение результата и запись в БД
— отслеживание работы воркеров (воркер сам периодически пингует шедулера. По умолчанию, каждую минуту шедулер проверяет были ли от воркера сообщения, и если не было, то все назначенные задачи этого воркера перераспределяет на остальных доступных воркеров)
Шедулер имеет постоянный заранее определенный список своих воркеров (конфигурируемый параметр), причем каждый воркер может относится только к одному шедулеру.
Шедулеров как и воркеров может быть несколько, это может быть актуально для группировки воркеров по функционалу (но не обязательно ограничивать число одинаковых по функционалу воркеров, поскольку один шедулер может обслуживать сотни воркеров, и если понадобится еще шедулер, значит узким местом будет уже скорее БД).
С БД общается только шедулер (через интерфейс), воркер о БД ничего не знает.
Теперь пару слов о БД и перейдем к пользовательскому интерфейсу.
Схему БД посмотрим.
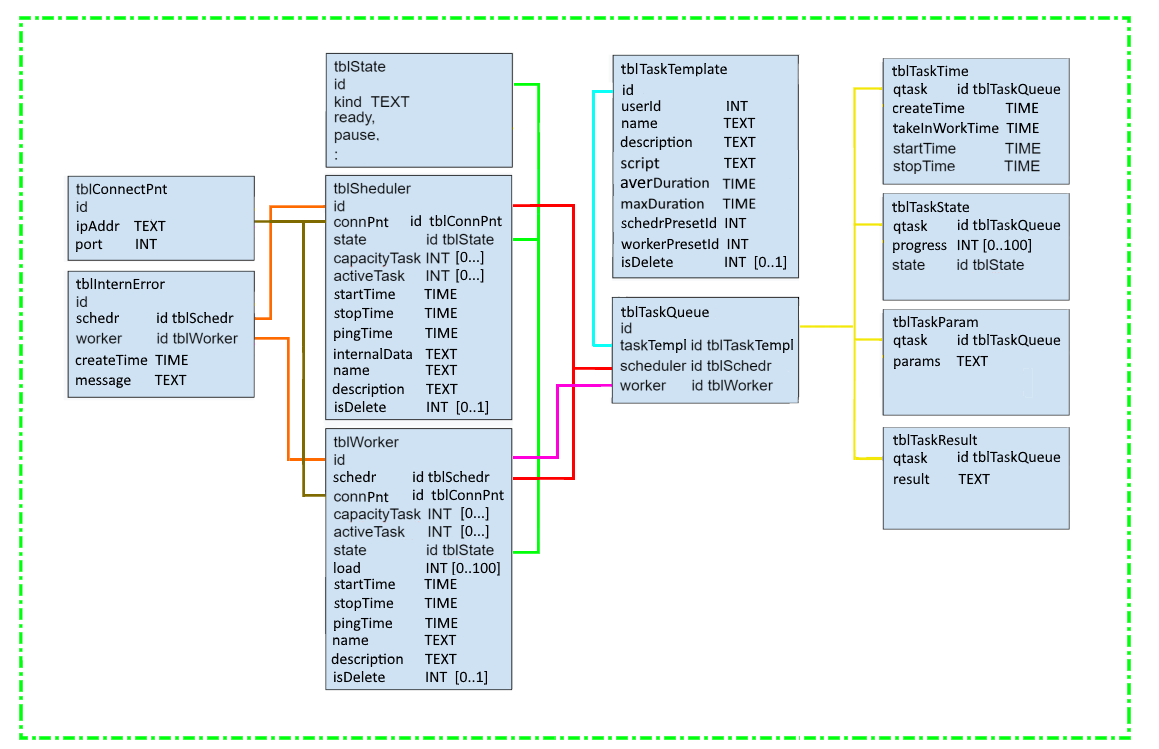
Основная таблица с задачами это `tblTaskQueue`. Задачи с пользовательского интерфейса от всех пользователей попадают в эту таблицу, на таблице висит триггер, который сигнализирует слушающим шедулерам (используется механизм БД 'listen-notify'), что доступны новые задачи.
Остальные таблицы просто перечислю: таблицы конфигов шедулеров/воркеров, таблица скриптов задач, текущее состояние задач, результаты выполнения задач.
Авто-очистка от старых выполненных задач пока не предусмотрена, потом что-нидь придумать можно.
Интерфейс разделен на пайплайны, шаблоны задач, события и сами задачи:
— шаблон задачи — это скрипт задачи + среднее и максимальное время выполнения.
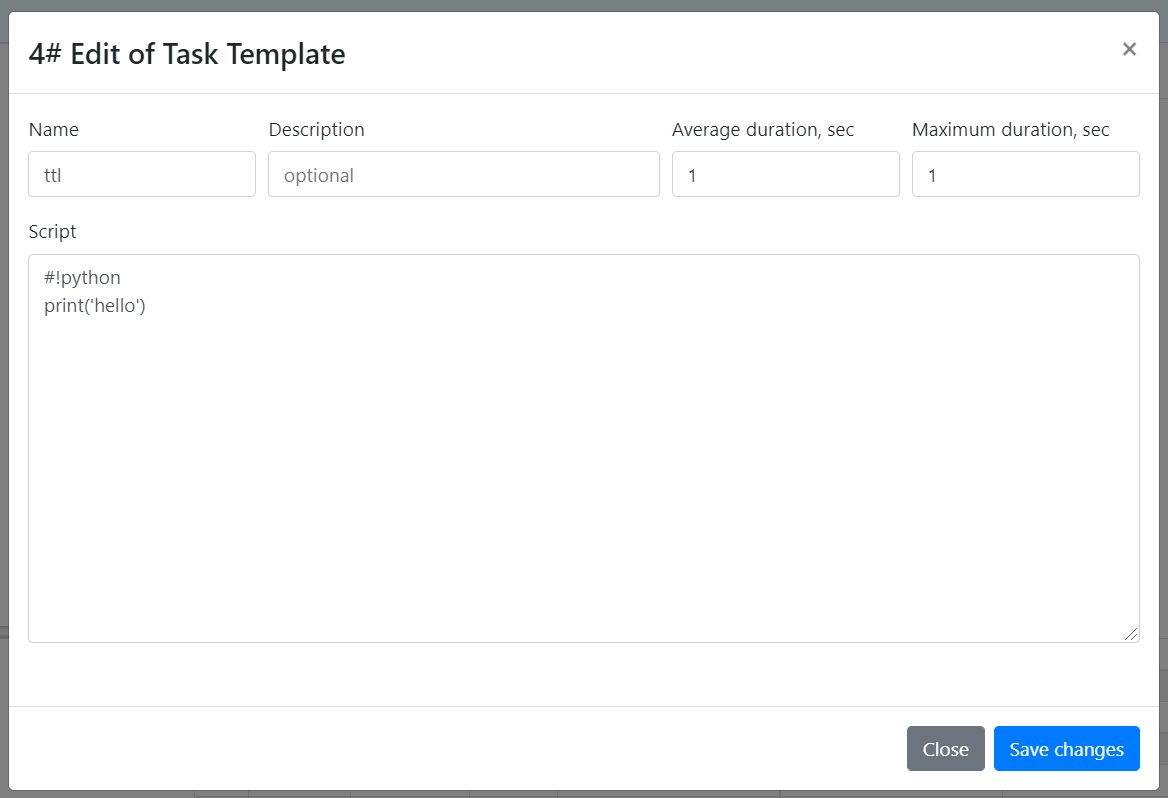
Интерпретатор скрипта задается в первой строке после шебанг (#!), далее могут быть аргументы для интерпретатора.
Среднее время выполнения задачи нужно для правильного расчета процента прогресса выполнения задачи.
Максимальное время — для прерывания задачи. Прерванная задача считается ошибочной.
После ошибочной задачи не запускаются автоматически остальные задачи в цепочке.
— пайплайн — объединение задач по общему смыслу либо исходя из необходимой последовательности выполнения задач.

— события — это временные триггеры, которые срабатывают в заданный момент времени и запускают установленные задачи на любых пайплайнах
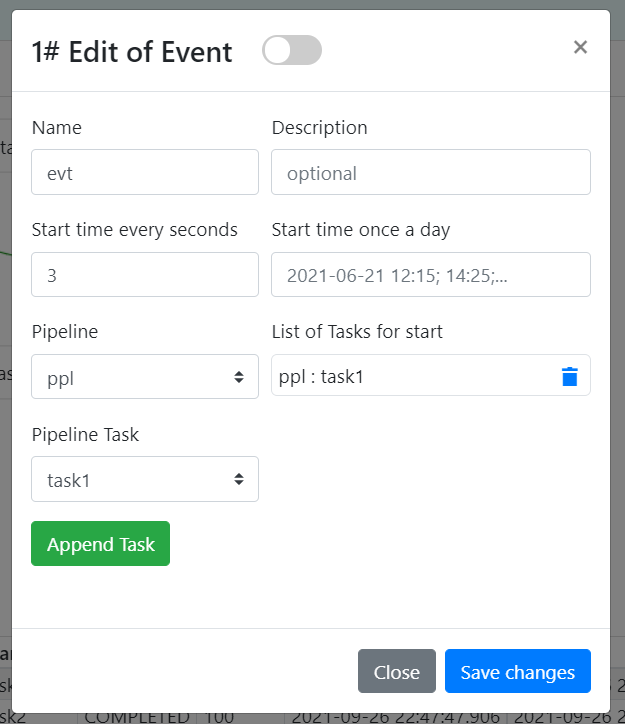
— конфиг задачи — это параметры для скрипта, выбранный шаблон скрипта и настройки для запуска следующей задачи в цепочке. Следующую задачу можно запускать по условию (проверка текущего результата задачи), также можно выбрать передавать ли результат как аргумент для следующей задачи.
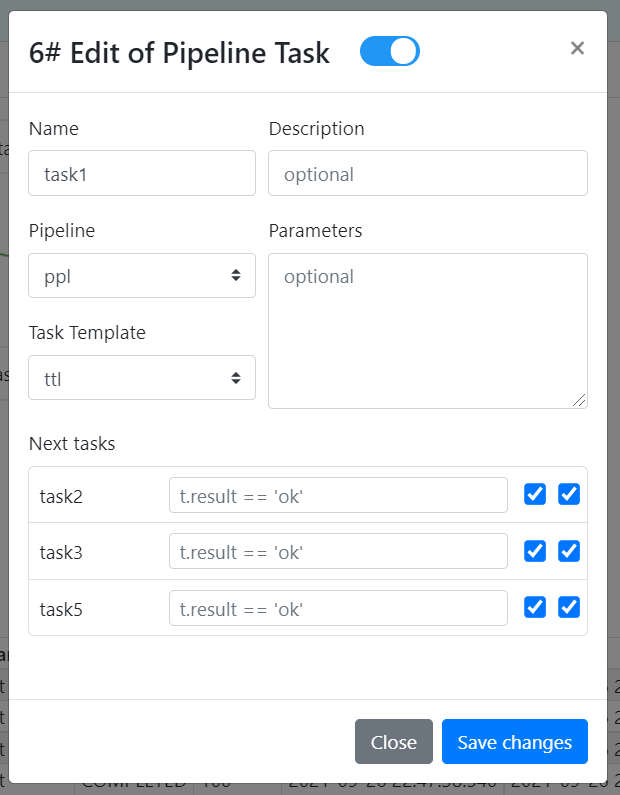
Сейчас немного поговорим про варианты использования этого хозяйства. Мышкой конечно удобно водить, но что если надо запустить 1000 задач одновременно, с одинаковым скриптом, но разными параметрами, или разными в чем-то скриптами. Здесь я вижу два пути решения:
Что имеем: 5 шедулеров, у каждого 20 воркеров, каждый воркер может выполнять одновременно не более 5 задач.
Задача — такой скрипт: "#! /bin/sh \n sleep 1; echo res ", то есть 1 сек пауза.
Как проходил тест:
— запустились все шедулеры и воркеры
— отправили партию 1000 задач
— далее ждем успешного выполнения этих задач
— снова отправляем следующую партию
— опять ждем когда выполнятся и тд 1000 раз
В итоге получилось 1 млн задач, 2 часа с лишним заняло времени. Все это дело запускалось на одной машине (ноут i7, 8Гб).
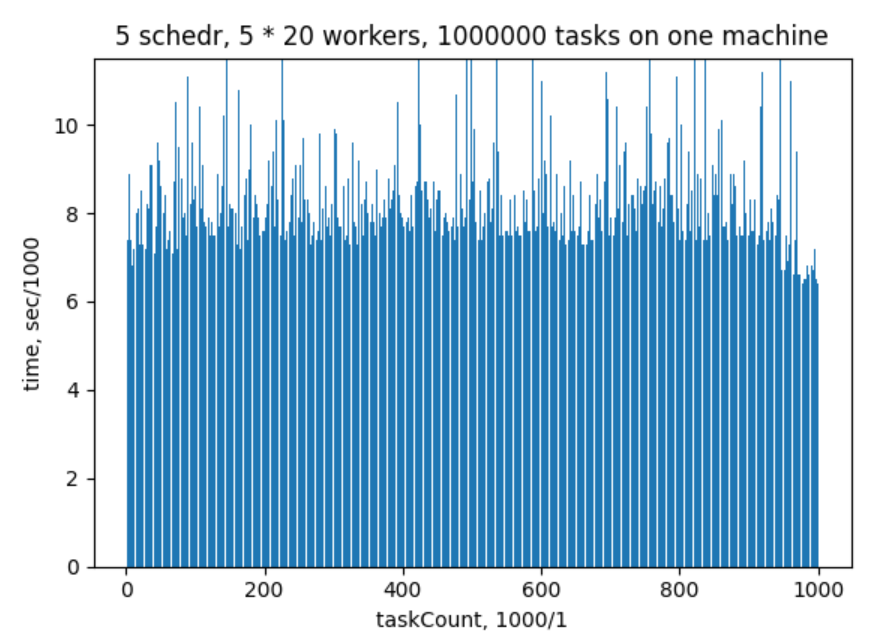
На графике мы видим по оси Х количество выполненных задач в масштабе 1 к 1000, по оси Y время выполнения каждой 1000 задач в секундах. Из графика видно, что в среднем выполнение пачки задач занимало 7-8 секунд. Система в целом отработала стабильно, ни один воркер и шедулер не упал. Тест доступен по ссылке.
Теперь попробуем все это дело развернуть и запустить локально.
Будем использовать docker .
В докер-хаб я не стал выкладывать образ (пока), поэтому будем собирать локально.
Для начала нужно скачать Dockerfile из проекта или скопировать
Этот файл один на все сервисы системы, то есть через него можно запустить: вэб-сервер, шедулер и воркер.
— в Dockerfile нужно изменить строку подключения к БД postgres, где у меня: «DbConnectStr=host=192.168.0.104 port=5432 user=alm password=123 dbname=zmeydb», вы указывайте свою строку подключения.
Подойдет любая пустая БД, никаких таблиц создавать не нужно.
— соберем образ:
— создадим подсеть
— запустим вэб-сервер (здесь Flask запускается непосредственно только для демонстрации, но вы можете потом использовать продакшн WSGI сервер gunicorn, например):
— на хост машине в браузере откроем страничку 172.22.0.1:5000/ (172.22.0.1 — адрес шлюза для докера у меня, у вас адрес может быть другим) и зайдем в админку, нужно задать: логин 'admin', пароль 'p@ssw0rd' (пароль зашит в коде). Добавим шедулера и воркера, должно получиться как здесь:

— далее запустим шедулер:
Здесь аргумент -la=172.18.0.3:4440 — адрес контейнера и порт, его же мы указали при создании шедулера в админке, -db — строка подключения к БД (у вас должна быть своя).
— запустим воркер:
Здесь аргумент -la=172.18.0.4:4450 — адрес контейнера и порт, его же мы указали при создании воркера в админке, -sa=172.18.0.3:4440 — адрес контейнера шедулера.
— далее на хост машине в браузере переходим на страничку регистрации 172.22.0.1:5000/auth/register, создаем любого пользователя, далее логинимся от него.
В итоге должна открыться главная страничка приложения:

Далее там все довольно просто, в ролике выше весь процесс показан: создаете пайплайн, шаблон задачи, добавляете задачу на экран, далее ПКМ на задаче — «Запустить».
Ну вот и все пожалуй. Присоединяйтесь к разработке.
Распространяется свободно, лицензия MIT
Спасибо.
Написал многопользовательский менеджер задач с веб интерфейсом. Кому интересно, прошу.
Сразу ролик, что получилось
Назвал это произведение «Zmey».
Пока выглядит конечно по-спартански, и до Airflow далеко в плане фич.
Реализован такой базовый функционал:
- запуск, пауза, останов конкретной задачи
- передача результата задачи в следующую по цепочке задачу
- запуск задачи по времени — в конкретное время, либо через интервал
- у каждого пользователя свой пул задач
- задачи выполняются параллельно на множестве машин
В этой статье хочу сделать не большой обзор системы, более подробное описание будет на страничке проекта (находится в процессе).
Сейчас посмотрим общую схему ПО, и далее поговорим о каждом модуле системы.
Архитектура ПО
Система на низком уровне состоит из базы данных (PostgreSQL выбрана), планировщика задач `zmscheduler` (далее шедулер) и исполнителя задачи `zmworker` (далее воркер). Написаны на плюсах, из зависимостей только asio (без буста).
Бэкенд написан на Python с помощью вэб-фреймворка Flask. С низким уровнем общается через клиент `zmclient` (написан на плюсах с си-интерфейсом) + обертка для вызова из питона.
Для каждого пользователя при регистрации создается вспомогательная БД sqlite для сохранения инфраструктуры задач и текущего состояния интерфейса.
Фронтенд это SPA приложение на базе React + Mobx, оформление Boostrap, и админка
для создания шедулеров и воркеров (js без реакта).
Общение между фронтом и бэком построено на базе RestAPI.
Задача — это скрипт на любом языке (в основном конечно предполагается 'bash' либо 'Python', на Windows 'cmd' может быть).
На рабочей машине запущен воркер, который выполняет скрипт задачи путем запуска дочернего процесса. Вывод дочернего процесса является результатом выполнения задачи. Каждый воркер может одновременно выполнять несколько задач (конфигурируемый параметр).
Задачи для воркера поставляет шедулер.
В обязанности шедулера входит:
— получение новых задач из БД,
— выбор доступного воркера, и отправка ему задачи
— получение результата и запись в БД
— отслеживание работы воркеров (воркер сам периодически пингует шедулера. По умолчанию, каждую минуту шедулер проверяет были ли от воркера сообщения, и если не было, то все назначенные задачи этого воркера перераспределяет на остальных доступных воркеров)
Шедулер имеет постоянный заранее определенный список своих воркеров (конфигурируемый параметр), причем каждый воркер может относится только к одному шедулеру.
Шедулеров как и воркеров может быть несколько, это может быть актуально для группировки воркеров по функционалу (но не обязательно ограничивать число одинаковых по функционалу воркеров, поскольку один шедулер может обслуживать сотни воркеров, и если понадобится еще шедулер, значит узким местом будет уже скорее БД).
С БД общается только шедулер (через интерфейс), воркер о БД ничего не знает.
Теперь пару слов о БД и перейдем к пользовательскому интерфейсу.
Схему БД посмотрим.
Основная таблица с задачами это `tblTaskQueue`. Задачи с пользовательского интерфейса от всех пользователей попадают в эту таблицу, на таблице висит триггер, который сигнализирует слушающим шедулерам (используется механизм БД 'listen-notify'), что доступны новые задачи.
Остальные таблицы просто перечислю: таблицы конфигов шедулеров/воркеров, таблица скриптов задач, текущее состояние задач, результаты выполнения задач.
Авто-очистка от старых выполненных задач пока не предусмотрена, потом что-нидь придумать можно.
Пользовательский интерфейс
Интерфейс разделен на пайплайны, шаблоны задач, события и сами задачи:
— шаблон задачи — это скрипт задачи + среднее и максимальное время выполнения.
Интерпретатор скрипта задается в первой строке после шебанг (#!), далее могут быть аргументы для интерпретатора.
Среднее время выполнения задачи нужно для правильного расчета процента прогресса выполнения задачи.
Максимальное время — для прерывания задачи. Прерванная задача считается ошибочной.
После ошибочной задачи не запускаются автоматически остальные задачи в цепочке.
— пайплайн — объединение задач по общему смыслу либо исходя из необходимой последовательности выполнения задач.
— события — это временные триггеры, которые срабатывают в заданный момент времени и запускают установленные задачи на любых пайплайнах
— конфиг задачи — это параметры для скрипта, выбранный шаблон скрипта и настройки для запуска следующей задачи в цепочке. Следующую задачу можно запускать по условию (проверка текущего результата задачи), также можно выбрать передавать ли результат как аргумент для следующей задачи.
Сейчас немного поговорим про варианты использования этого хозяйства. Мышкой конечно удобно водить, но что если надо запустить 1000 задач одновременно, с одинаковым скриптом, но разными параметрами, или разными в чем-то скриптами. Здесь я вижу два пути решения:
- Первый путь довольно хардкорный может быть. Это использование относительно низкоуровневого интерфейса системы — либы `zmclient`. Здесь полностью игнорируется вэб часть системы, и все взаимодействие идет непосредственно с БД postgres. Хоть и есть обертка на питоне, но все равно придется разбираться с интерфейсом клиента и со структурой БД. Этот путь подходит для разового решения конкретной задачи. Тест производительности описанный ниже как раз идет по этому пути.
- Второй путь проще и более гибкий может быть. Это использование RestAPI интерфейса вэб-клиента, то есть пользователь выступает в качестве браузера, на том же питоне (или используя curl и bash) пишет вэб-запросы к серверу. При этом все созданные скрипты и запущенные задачи будут отображены в интерфейсе, и записаны в локальную БД sqlite пользователя, также можно непосредственно обратится к этой локальной БД и вытащить оттуда всю необходимую информацию, никак не влияя на работу основной БД. Но пока на данный момент RestAPI клиента довольно скудный и не может охватить множество вариантов использования, также пока отсутствует описание RestAPI интерфейса взаимодействия.
Тест производительности
Что имеем: 5 шедулеров, у каждого 20 воркеров, каждый воркер может выполнять одновременно не более 5 задач.
Задача — такой скрипт: "#! /bin/sh \n sleep 1; echo res ", то есть 1 сек пауза.
Как проходил тест:
— запустились все шедулеры и воркеры
— отправили партию 1000 задач
— далее ждем успешного выполнения этих задач
— снова отправляем следующую партию
— опять ждем когда выполнятся и тд 1000 раз
В итоге получилось 1 млн задач, 2 часа с лишним заняло времени. Все это дело запускалось на одной машине (ноут i7, 8Гб).
На графике мы видим по оси Х количество выполненных задач в масштабе 1 к 1000, по оси Y время выполнения каждой 1000 задач в секундах. Из графика видно, что в среднем выполнение пачки задач занимало 7-8 секунд. Система в целом отработала стабильно, ни один воркер и шедулер не упал. Тест доступен по ссылке.
Теперь попробуем все это дело развернуть и запустить локально.
Установка и запуск
Будем использовать docker .
В докер-хаб я не стал выкладывать образ (пока), поэтому будем собирать локально.
Для начала нужно скачать Dockerfile из проекта или скопировать
отсюда:
FROM ubuntu:18.04 RUN apt-get update && \ apt-get -y install build-essential git cmake python3.8 python3-pip && \ apt-get -y install libpq-dev postgresql-server-dev-10 && \ apt-get clean RUN pip3 install flask # build core RUN git clone https://github.com/Tyill/zmey.git WORKDIR /zmey/build RUN cmake -B . -S ../core -DCMAKE_BUILD_TYPE=Release && cmake --build . # prepare flask app ENV FLASK_APP=/zmey/web/server ENV LC_ALL=C.UTF-8 ENV LANG=C.UTF-8 ENV LD_LIBRARY_PATH=/zmey/build/Release RUN printf "[Params]\n \ DbConnectStr=host=192.168.0.104 port=5432 user=alm password=123 dbname=zmeydb" \ > /zmey/zmserver.cng WORKDIR /zmey
Этот файл один на все сервисы системы, то есть через него можно запустить: вэб-сервер, шедулер и воркер.
— в Dockerfile нужно изменить строку подключения к БД postgres, где у меня: «DbConnectStr=host=192.168.0.104 port=5432 user=alm password=123 dbname=zmeydb», вы указывайте свою строку подключения.
Подойдет любая пустая БД, никаких таблиц создавать не нужно.
— соберем образ:
docker build . -t zmcore
— создадим подсеть
docker network create --subnet=172.18.0.0/16 zmnet
— запустим вэб-сервер (здесь Flask запускается непосредственно только для демонстрации, но вы можете потом использовать продакшн WSGI сервер gunicorn, например):
docker container run -it --rm --net zmnet --ip 172.18.0.2 -p 5000:5000 zmcore flask run --host 0.0.0.0
— на хост машине в браузере откроем страничку 172.22.0.1:5000/ (172.22.0.1 — адрес шлюза для докера у меня, у вас адрес может быть другим) и зайдем в админку, нужно задать: логин 'admin', пароль 'p@ssw0rd' (пароль зашит в коде). Добавим шедулера и воркера, должно получиться как здесь:
— далее запустим шедулер:
docker container run -it --rm --net zmnet --ip 172.18.0.3 -p 4440:4440 zmcore build/Release/zmscheduler -la=172.18.0.3:4440 -db="host=192.168.0.104 port=5432 user=alm password=123 dbname=zmeydb"
Здесь аргумент -la=172.18.0.3:4440 — адрес контейнера и порт, его же мы указали при создании шедулера в админке, -db — строка подключения к БД (у вас должна быть своя).
— запустим воркер:
docker container run -it --rm --net zmnet --ip 172.18.0.4 -p 4450:4450 zmcore build/Release/zmworker -la=172.18.0.4:4450 -sa=172.18.0.3:4440
Здесь аргумент -la=172.18.0.4:4450 — адрес контейнера и порт, его же мы указали при создании воркера в админке, -sa=172.18.0.3:4440 — адрес контейнера шедулера.
— далее на хост машине в браузере переходим на страничку регистрации 172.22.0.1:5000/auth/register, создаем любого пользователя, далее логинимся от него.
В итоге должна открыться главная страничка приложения:
Далее там все довольно просто, в ролике выше весь процесс показан: создаете пайплайн, шаблон задачи, добавляете задачу на экран, далее ПКМ на задаче — «Запустить».
Ну вот и все пожалуй. Присоединяйтесь к разработке.
Распространяется свободно, лицензия MIT
Спасибо.

