
Привет, Хабр!
В работе над проектом Образовательной Платформы Сбера мы столкнулись с ситуацией, когда интенсивность влития изменений в центральную ветку репозитория git существенно превысила время прохождения Quality Gate (статический анализ, сборка, автотесты) внесённых изменений. В статье я расскажу, как нам удалось решить эту проблему, не утратив скорости разработки и добившись стопроцентной зелёной ветки master. В рамках данной статьи я позволю себе немного упростить описываемую ситуацию.
А теперь давайте по порядку. Как и в любом новом проекте, всё начинается с одного git-репозитория, кодовая база стремительно растёт, количество разработчиков увеличивается, появляются первые процессы CI/CD, сборка, тестирование, доставка, всевозможные автоматические проверки кода на соответствие стайлгайду, уязвимости, обратной совместимости и т. д.
Для простоты будем считать, что у нас один проект, один репозиторий, master-ветка, множество feature-веток и большое количество разработчиков. Процесс работы с git очень простой — от master отводится feature-ветка, а когда работы завершены, эта ветка вливается обратно в master. GitFlow, Trunk Based Development и другие лучшие практики остаются за скоупом данной статьи.

Время, необходимое чтобы пройти все проверки, неизменно растёт. Конечно, что-то удаётся оптимизировать за счёт вертикального масштабирования, что-то удаётся распараллелить, а где-то достаточно просто подобрать удачную конфигурацию RAM/Cache/Swap/Threads. Но рано или поздно наступит момент, когда длительность проверки одной feature-ветки составит T минут, а интенсивность вливаемых изменений — T’ минут, где T’ >> T. Другими словами, пока один разработчик собирает свою feature-ветку (feature 1) со свежей веткой master, второй разработчик (feature 2) успевает влиться в master, а когда первый разработчик прошёл все необходимые проверки, оказывается, что его ветка устаревает и, не имея явных merge-конфликтов с master, ломает функционал на этапе сборки/автотестов. Первый разработчик снова вносит правки и запускает сборку с автотестами, но пока он это делает, приходит третий разработчик и успевает влиться до первого. Этот процесс может быть бесконечно долгим, возникает гонка на влитие, что очень демотивирует людей и снижает эффективность работы. И чем больше людей работает над одним репозиторием, тем больше вероятность такой ситуации.

Давайте попробуем формализовать вышесказанное. Feature-ветка 1 была отведена от master в точке M2, добавила 2 коммита F1.1 и F1.2 и успешно прошла все проверки:
![BuildAndTest(M_1 + M_2 + [F_{1.1} + F_{1.2}]) = SUCCESS](https://habrastorage.org/getpro/habr/upload_files/466/240/4f3/4662404f39c4686858456d4d2b379a6f.svg)
Feature-ветка 2 отведена от master в точке M2, добавила 2 коммита F2.1 и F2.2, усп��шно прошла все проверки и влилась обратно в master, образовав merge-коммит M3:
![BuildAndTest(M_1 + M_2 + [F_{2.1} + F_{2.2}]) = BuildAndTest(M_1 + M_2 + [M_3]) = SUCCESS](https://habrastorage.org/getpro/habr/upload_files/f78/5c8/aa1/f785c8aa15f3ab502817c2af750b0ab2.svg)
Feature-ветка 1, которая прошла все проверки, вливается в master, но в master уже появился новый коммит M3, который конфликтует с feature-веткой 1 (не путать с git-конфликтами). В итоге после влития мы получаем нерабочую master-ветку.
![BuildAndTest(M_1 + M_2 + [F_{2.1} + F_{2.2}] + [F_1.1 + F_{1.2}]) = \\ = BuildAndTest(M_1 + M_2 + M_3 + [F_{1.1} + F_{1.2}]) = \\ = BuildAndTest(M_1 + M_2 + M_3 + M_4) = FAILED](https://habrastorage.org/getpro/habr/upload_files/cb0/cce/3fc/cb0cce3fcae6f782f71a32c11fc01ad9.svg)
Мы же хотим создать такие условия, при которых master будет всегда зелёным, а именно – в него не попадут merge коммиты, которые не проходят сборку и тестирование.
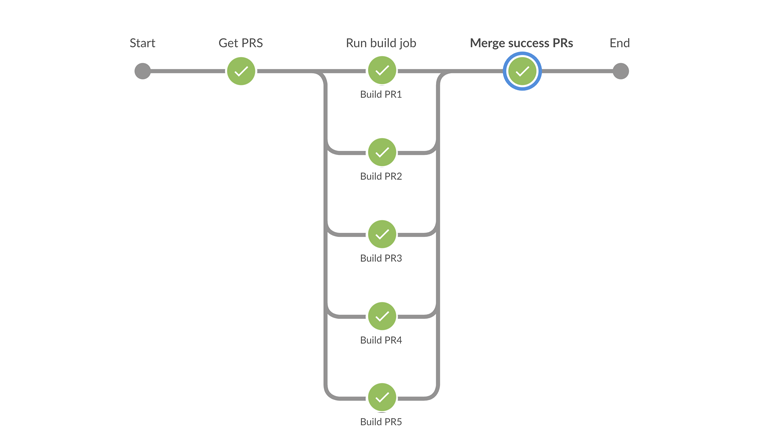
Самый простой и очевидный вариант — выстроить строго последовательную очередь из сборок, где каждый коммит перед влитием будет собираться и тестироваться с самой последней версией ветки master, а остальные ветки будут ждать. Такой способ имеет право на существование, если у вас невысокая интенсивность вносимых изменений и время проверки изменений (сборка и тестирование) достаточно мало. Если же это не так, процесс влития изменений в master будет искусственно ограничен. Например, если время сборки и тестирования занимает 1 час, то в master-ветку нельзя будет внести более 24 изменений (влитий веток) за сутки. Этот вариант, очевидно, нам не подходил. Поэтому возникла идея, что можно параллельно собирать ветки из очереди по принципу матрёшки.
Предположим, что у нас есть F1, F2, …. FN веток, готовых для влития в master. Они выстраиваются в строго последовательную очередь по мере того, как работы по этим веткам были завершены, для простоты пусть эта последовательность будет иметь вид:
F1 | F2 | F3 | F4 | F5 | ... | FN |
Предположим, что у нас есть возможность одновременно создавать K сборок (1 сборка = 1 ветка), где K <= N. Тогда работу для первого раунда сборок можно распределить следующим образом:
Сборка | Ветки | PR | Результат |
1 | Master + F1 | PR1 | SUCCESS |
2 | Master + F1 + F2 | PR2 | SUCCESS |
3 | Master + F1 + F2 + F3 | PR3 | FAILED |
... | ... | ... | |
K | Master + F1 + F2 + F3 + … + FK | PRK | FAILED |
Получается, что при условии, когда все K параллельных сборок прошли успешно, мы можем влить K веток за T минут и гарантировать, что master останется зелёным. Если успешно собрались только первые 2 feature-ветки, то значит, что гарантированно вливаются только эти 2 ветки [F1, F2], а [F4, … FK ,.. FN ] уходят на следующий раунд сборки, заведомо исключая ветку F3 из очереди т. к. она не прошла проверку. Новая очередь для нового раунда сборки будет выглядеть так:
0 | 1 | 2 | ... | K - 4 | ... | N - 4 |
F4 | F5 | F6 | ... | FK | ... | FN |
После того как разработчик ветки F3 внесёт правки, F3 снова может быть добавлена в конец очереди на слияние с master:
0 | 1 | ... | K - 4 | ... | N - 4 | N - 3 |
F4 | F5 | ... | FK | ... | FN | F3 |
Если же K > N, то всю очередь из N веток можно собрать за один проход при условии, что все сборки завершатся успешно. Необходимо помнить, что для гарантированной работы приведённого выше подхода необходимо полностью отказаться от ручного влития в master и делегировать монополию алгоритму.
Выводы
Описанное выше решение расширяет классический подход однопоточной очереди на влитие — Merge Queue. Его главное преимущество заключается в возможности масштабировать пропускную способность с гарантией качества вливаемых изменений.
P.S.
На момент реализации данного подхода в используемом нами стеке BitBucket Server + Jenkins не было найдено готовых подходящих решений. Поэтому появилась идея реализовать прототип и пропилотировать его на реальном проекте. О реализации и полученных результатах расскажу в следующей статье.
