
Всем привет! Я Никита Карпенко — ведущий frontend-разработчик команды CorelK в Cloud.ru. Сегодня порассуждаю о том, почему логика в хуках — это всегда иногда не очень хорошо, как не ошибиться с выбором технологий и управлять состоянием приложений так, чтобы было удобно. В статье поделюсь, как работаю без логики в хуках. Если интересно, заглядывай под кат!

В чем, собственно, проблема? Рассмотрим на простом примере
Начну с простого примера: заказчик просит сделать табличку с пользователями:

Для фронта это простая и понятная задача: запросили данные с помощью React Query — готово!
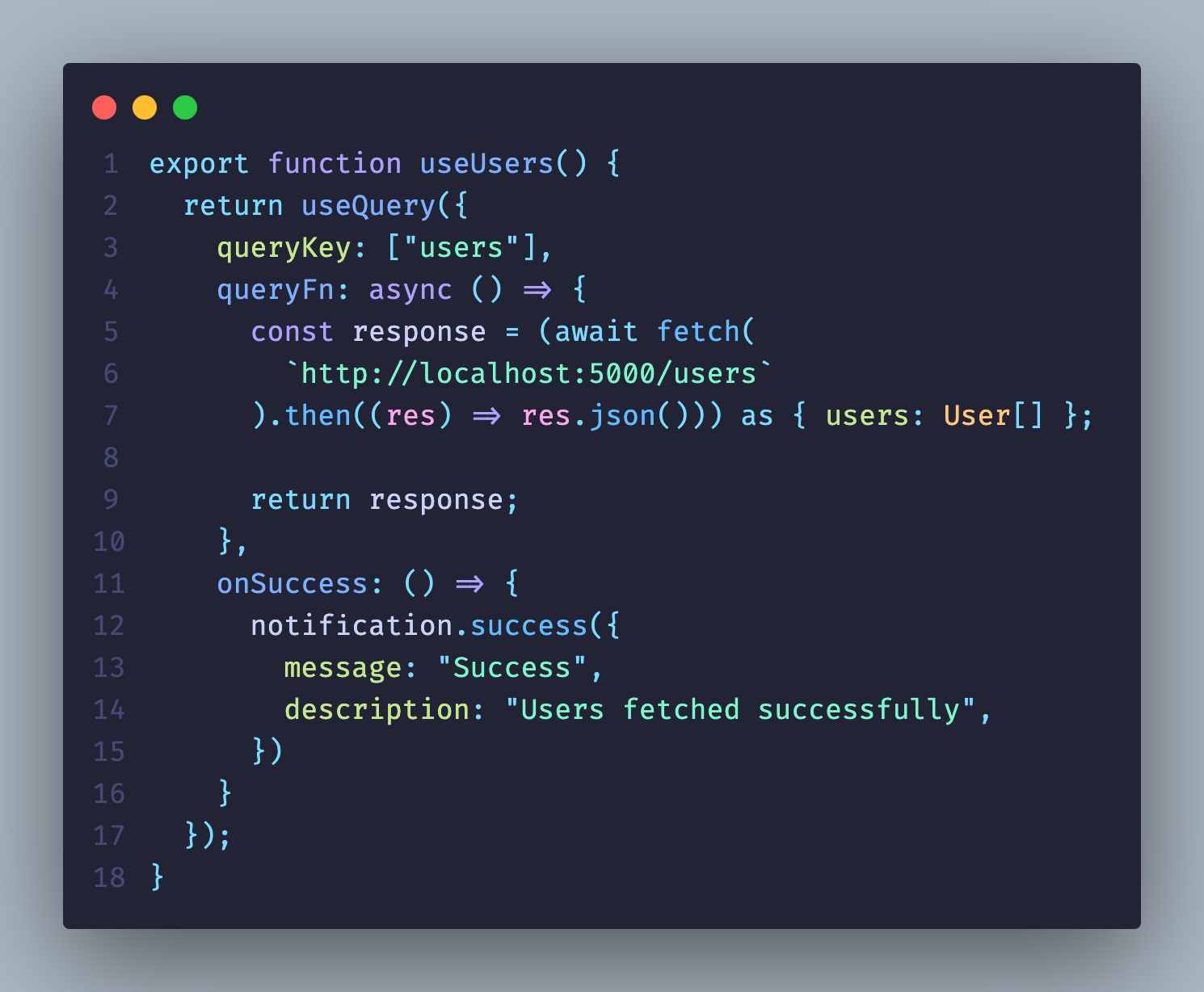
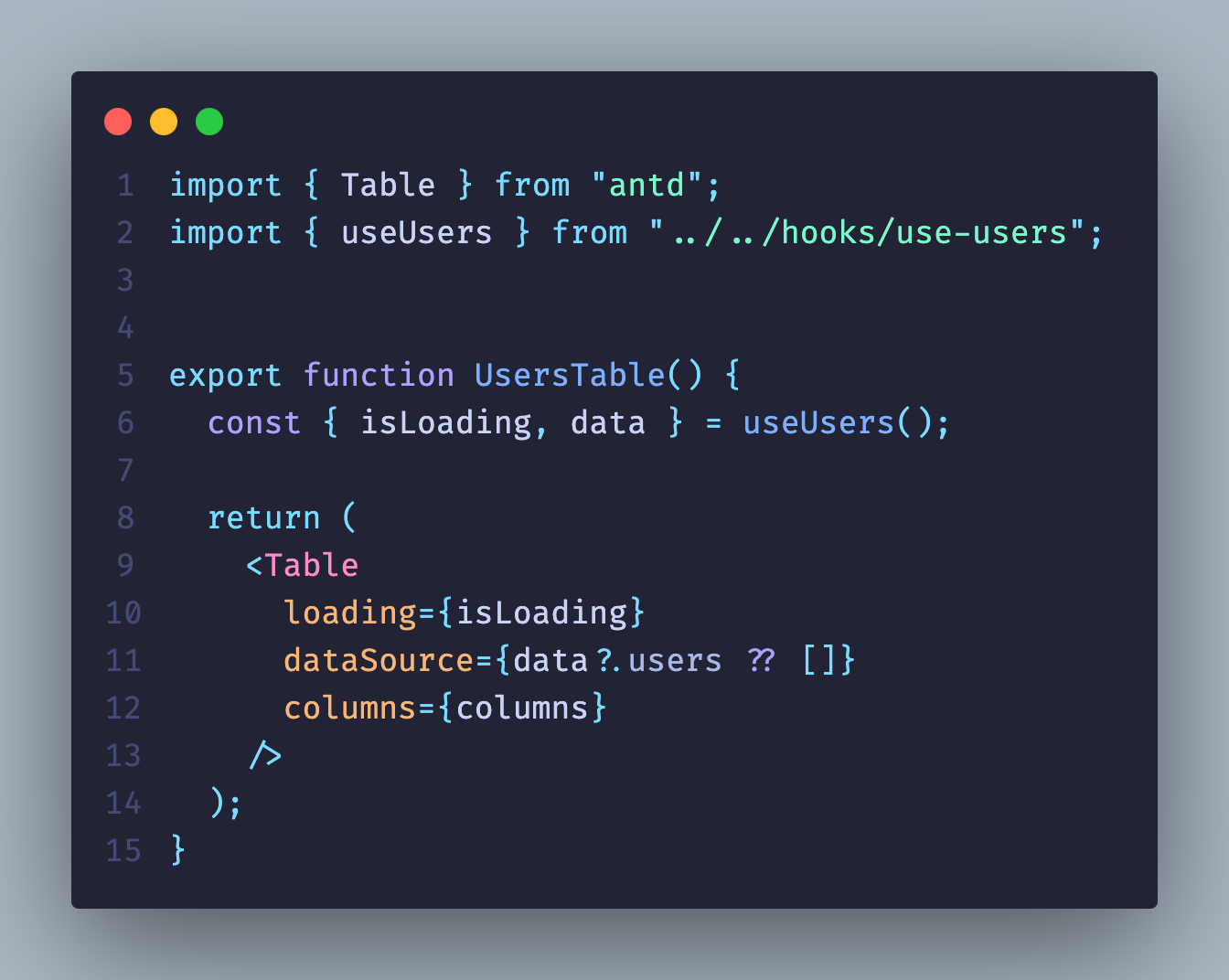
Но к нам снова приходит заказчик: «В табличке уже 200 пользователей. Сделайте, пожалуйста, поиск». Не вопрос — сделали:

И вроде бы все хорошо, но хук useUsers теперь находится на уровень выше. Теперь на каждое изменение SearchValue наш компонент UsersTable будет перерисовываться, хотя такое поведение мы не планировали:

Что мы обычно делаем в таких случаях? Правильно, используем React memo. Но в такие моменты может возникнуть вопрос — почему мы вообще должны об этом думать, решая самую примитивную задачу?
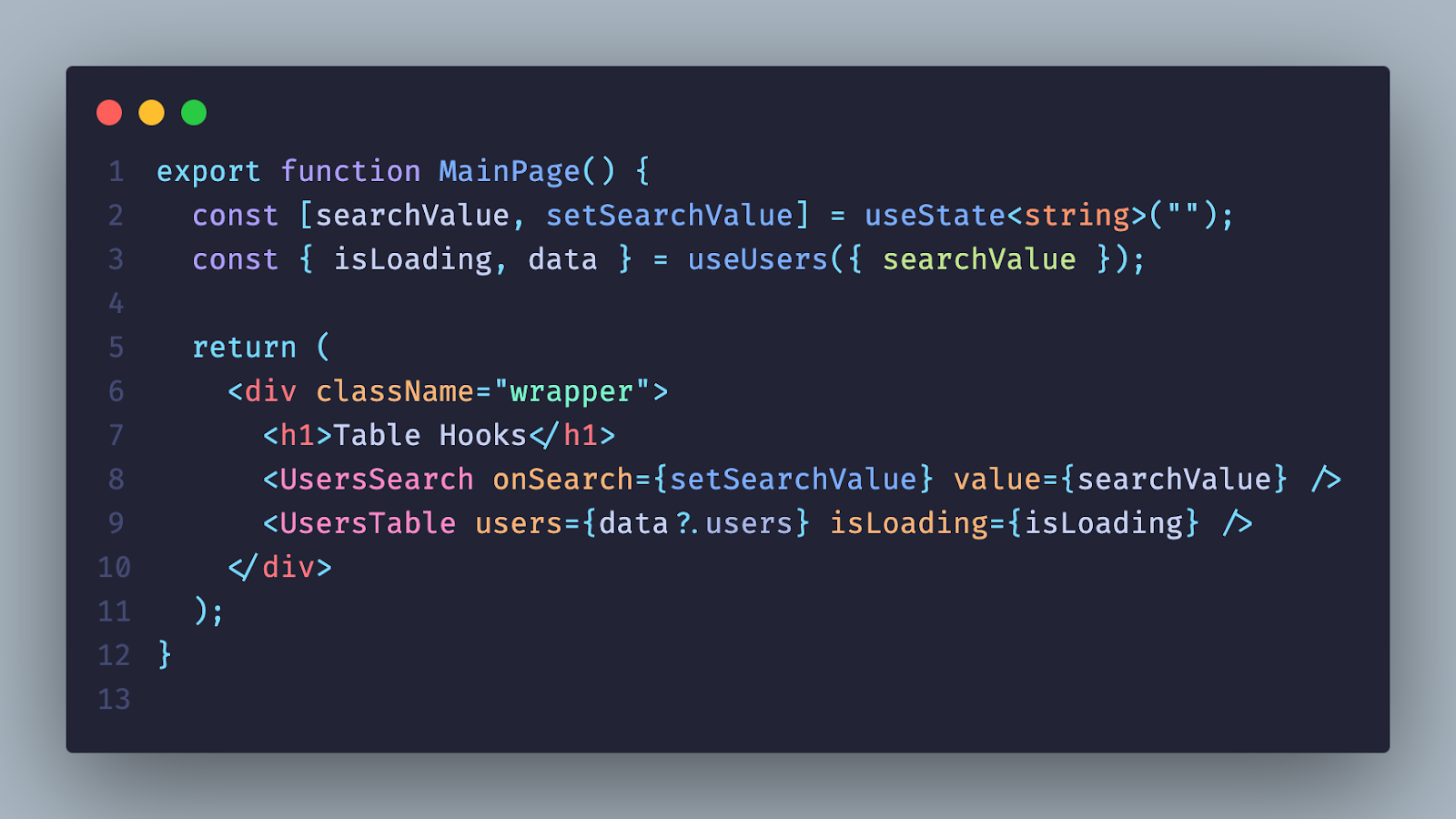
И вот к нам снова приходит заказчик и хочет, чтобы мы добавили фильтры, пагинацию и поиск с debounce:

Хорошо, напишем код. Но тут появляются нюансы: нам приходится использовать useCallback, чтобы при ререндере наша функция сохранила ссылку. И снова в голове возникают вопросы: почему я об этом должен думать? Правильно ли мы все делаем, если решение даже такой простой задачи заставляет нас учитывать столько нюансов?
Внутри нашего компонента стало много логики и переменных, а мы даже не реализовали всё, что хотели:

Но есть выход — можно вынести все в хук. Вот как это будет выглядеть:

Отлично, мы вынесли логику и теперь она находится вне компонента. Но хук все так же прибит к жизненному циклу. Это бывает неудобно, ведь далеко не вся наша логика зависит от жизненного цикла компонента. Поэтому иногда мы завязываемся на «симптомы», например, переход на страницу мы ловим на маунт компонента, а не как событие на роутере.
Получается, когда мы только начинаем работать над проектом, то имеем дело с «CRUD-мешалками». Мы получаем данные, отрисовываем их, затем получаем новые данные, добавляем их и снова отрисовываем: просто и примитивно.
Но всё меняется, когда мы начинаем делать сложные приложения, где есть огромное количество сущностей и в разы больше связей (примерно такое, как количество пассажиров и веток в Московском метро).
Например, мы делаем чаты, большие и сложные формы, дашборды, а не только таблички и формочки с четырьмя полями.
Но как делать сложные приложения с использованием локальных состояний? Кажется, что это слишком тяжело, появляется Props Drilling. Возникает вопрос — а что делать?
Варианты решения проблемы
У нас есть несколько вариантов:
Использовать связку react-query + context. Минус подхода в том, что нужно мигрировать данные между несколькими системами реактивности, что не очень просто. Также мы не сможем просто описывать бизнес-процесс, потому что логика также будет находиться внутри useEffect’ов (думаю, вы встречали useEffect hell, где от них невозможно избавиться).
Использовать СТМ, которые помогают управлять как локальным, так и серверным состоянием. Например:
RTK Query — хороший вариант, если бы не «Redux»;
Effector + Farfetched — библиотека русскоговорящих разработчиков, которая очень декларативна, предоставляет огромный спектр инструментов и позволяет решать бизнесовые задачи;
многие другие решения.
Я предлагаю рассмотреть, как работает Effector + Farfetched.
Преимущества Effector + Farfetched
Итак, на первом скриншоте наш компонент:
А на втором код, который нужно написать, чтобы логику из useState унести в сторону:

Вы можете сказать: «Как много! Раньше для того, чтобы создать состояние, мне нужно было написать ровно одну строчку, а теперь придется явно больше!». Но и это можно поправить — сделать фабрику, которая будет генерировать так же в одну строчку.
Итак, мы хотим каждый раз, когда меняются фильтры с каким-то debounce, делать запрос на сервер. Как это будет выглядеть: мы собираем общий фильтр, который будет базироваться на всех связанных (т. е. всех фильтрах, которые у нас были). Теперь на каждое изменение будет отправляться запрос. Также у нас есть debounce, который позволяет в одну строчку реализовать то, что при помощи хуков занимало бы около 15 строчек:
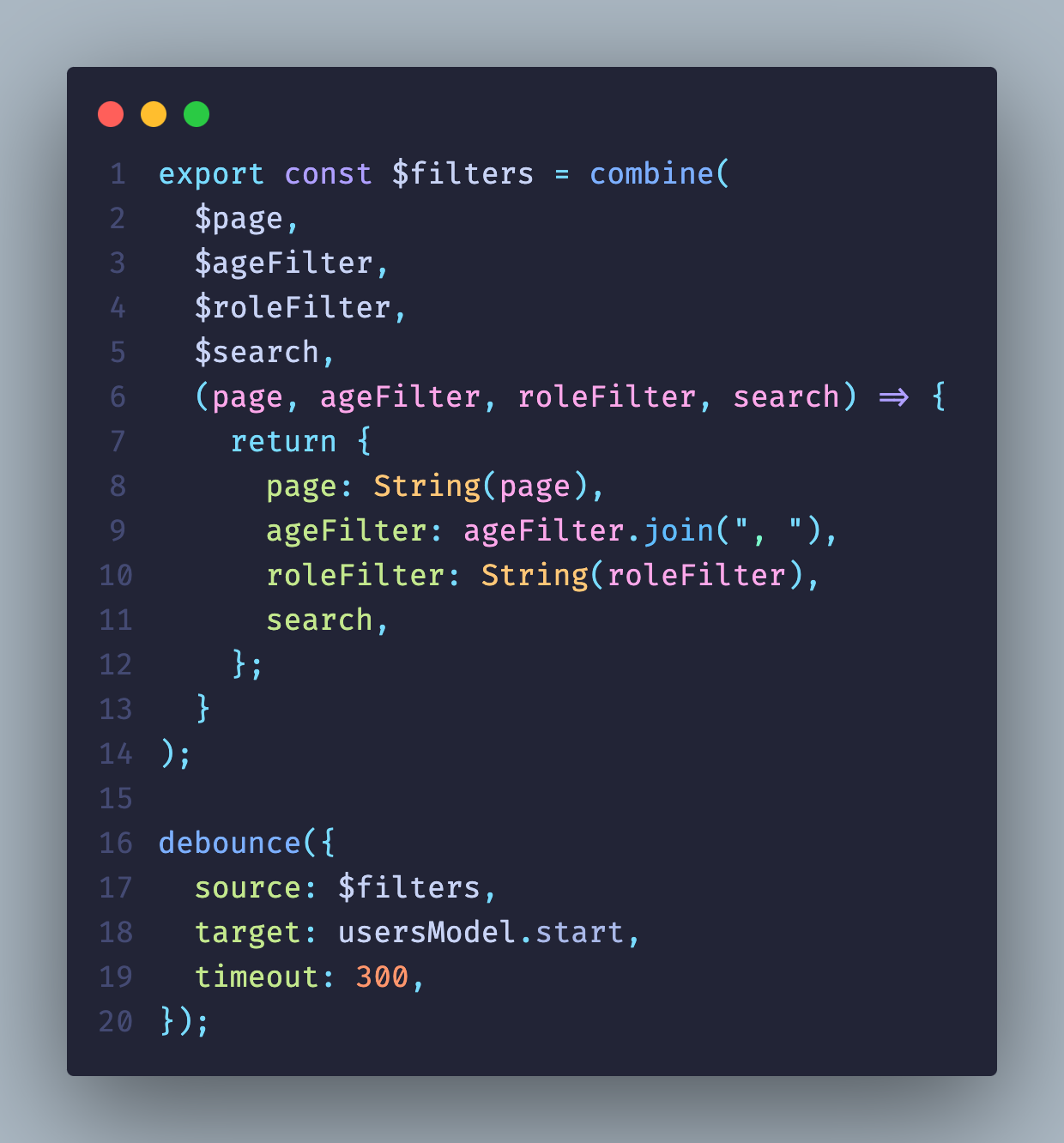
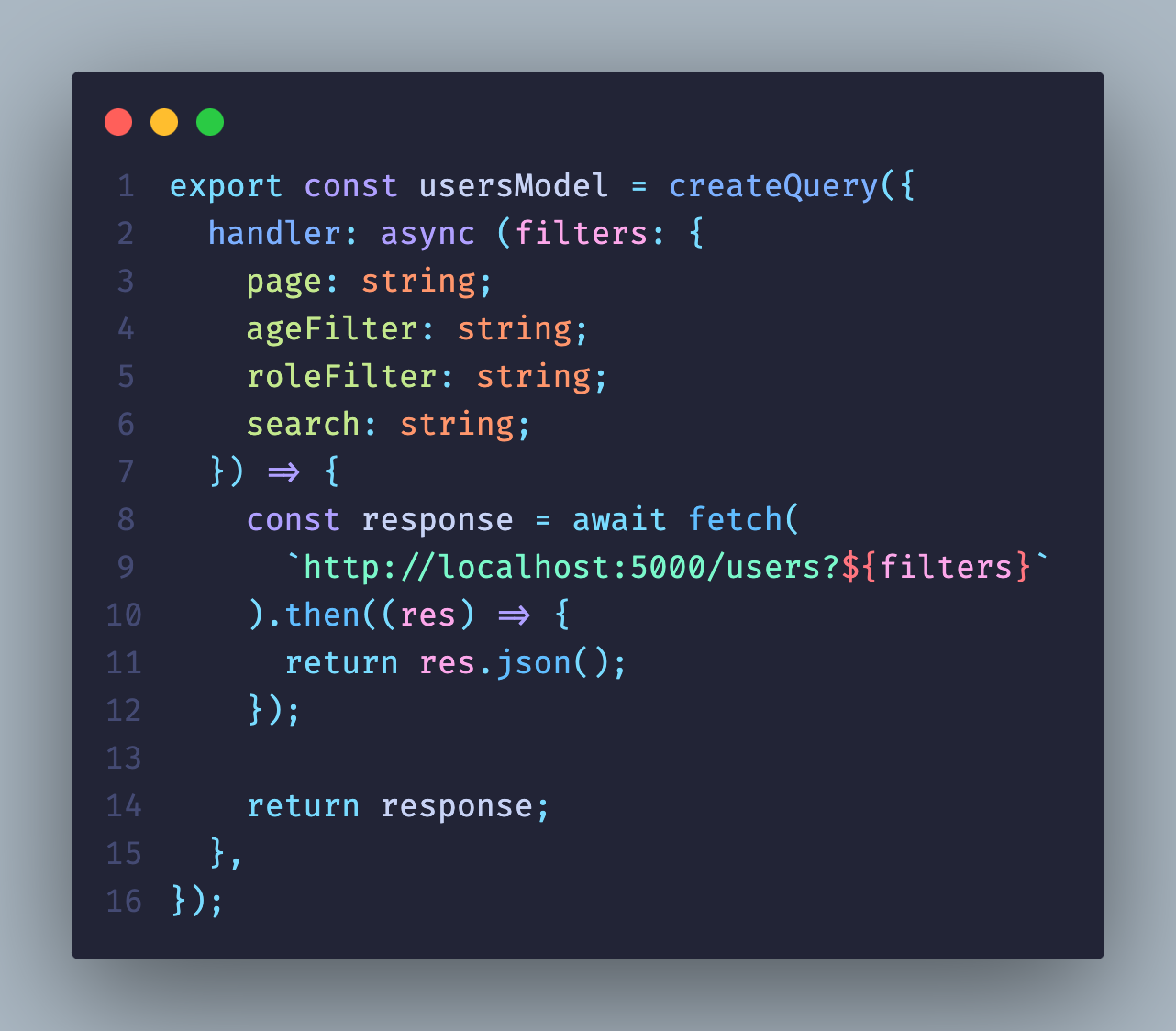
Посмотрите, как теперь выглядит компонент UsersTable. Получение данных снова вернулось в компонент таблицы, а все состояния фильтров используются только в тех компонентах, где правда нужны. На верхнем уровне нет никаких состояний, которые заставляют ререндериться всё приложение.
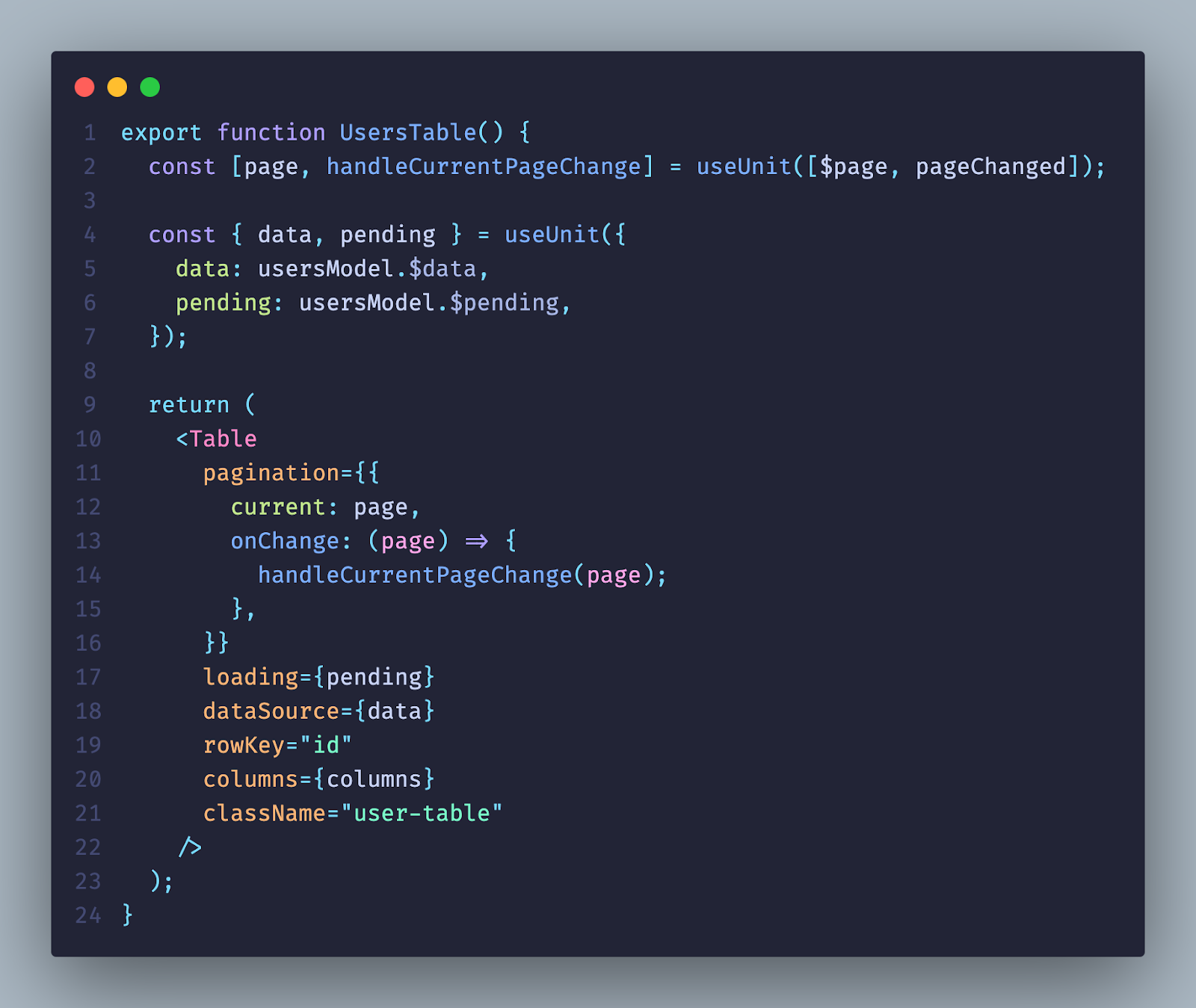
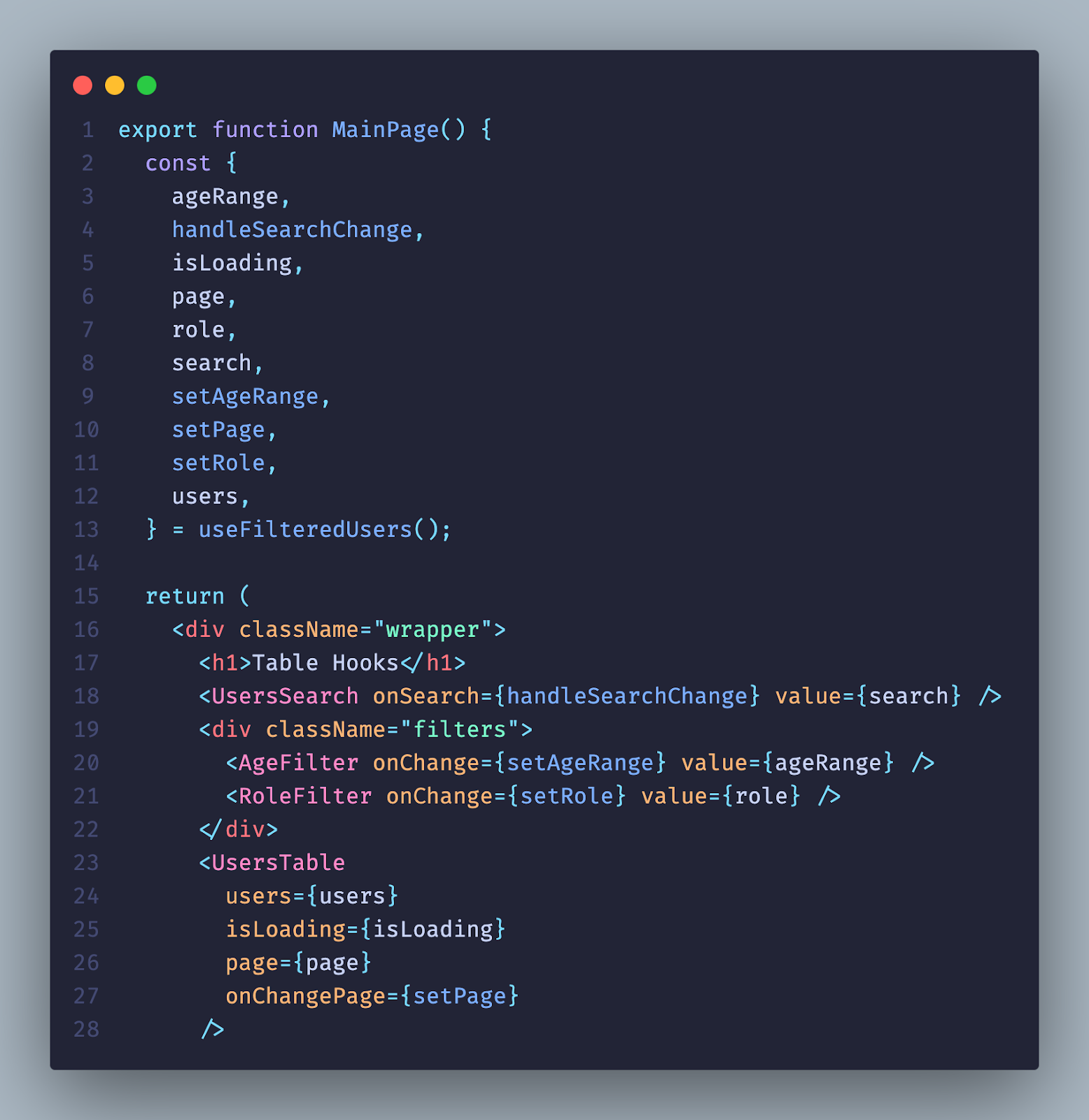
Теперь посмотрите на первый скриншот и на второй. На первом супер чистая структура компонентов, которые никак не зависят друг от друга и не заставляют друг друга ререндериться. Нам не нужно думать, что обернуть в useMemo, useCallback — все данные мы унесли в статическое хранилище, которое будет зависеть от жизненных циклов компонентов только тогда, когда мы захотим.

Но есть одна загвоздка — farfetched. У него около 1 100 загрузок в неделю (приблизительно 5 000 в месяц). Кажется, что использовать библиотеку с таким количеством скачиваний в некоторых случаях может быть рискованно.
Но и на такой случай есть решение) И оно достаточно простое:
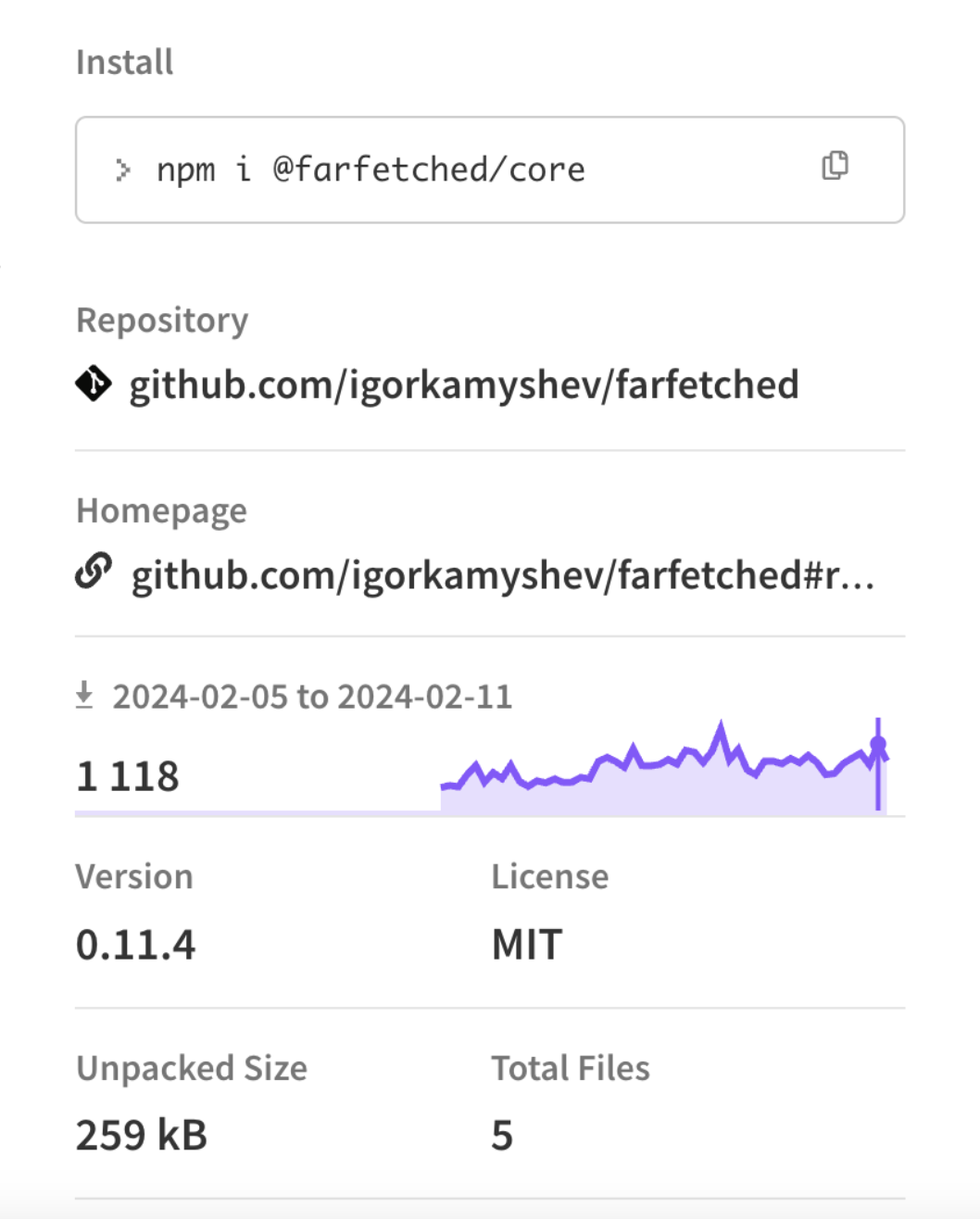
Можно взять tanstack/query-core (не react-query) и поверх него накрутить ту логику, которую мы и описывали. Теперь она не будет прибита хуками к компонентам:
Выводы
Стоит помнить, что со временем приложения всегда становится сложнее. Система должна помогать пользователю решать его задачи, это влечет за собой сложные процессы, а не простые CRUD-операции. Это важно учитывать при выборе стека перед стартом проекта или большим рефакторингом.
СТМ — это не так больно, как было раньше. Они не заставляют писать огромное количество кода, как это было во времена Redux’а.
Мало кода — это не значит, что код хороший.
Доклад Никиты Карпенко в видеоформате, а также обсуждение и ответы на вопросы можно посмотреть на YouTube-канале Cloud.ru. Подписывайтесь!
Интересное в блоге:
