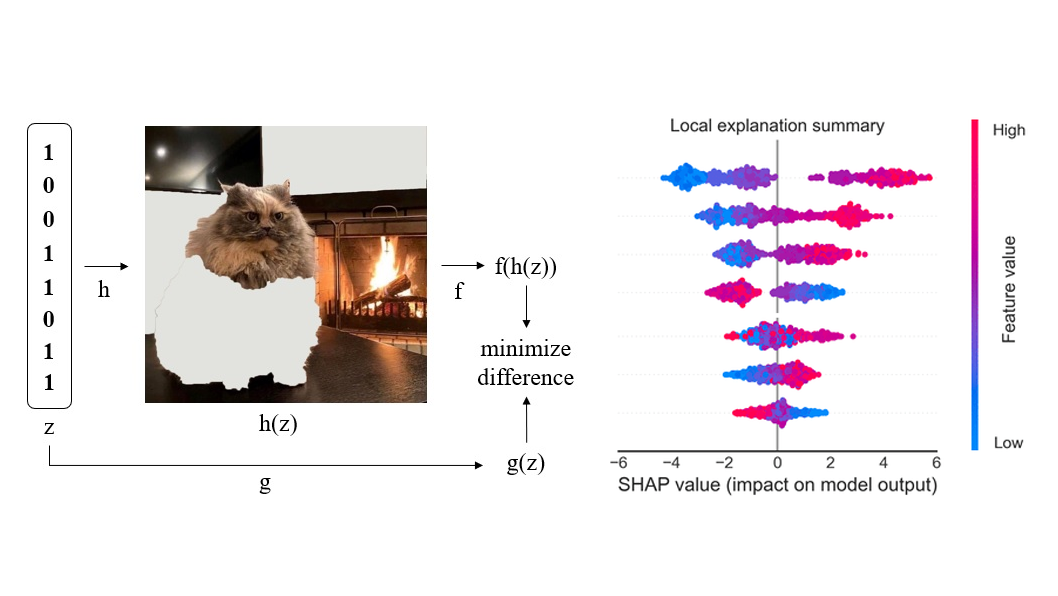
В этом обзоре мы рассмотрим, как методы LIME и SHAP позволяют объяснять предсказания моделей машинного обучения, выявлять проблемы сдвига и утечки данных, осуществлять мониторинг работы модели в production и искать группы примеров, предсказания на которых объясняются схожим образом.
Также поговорим о проблемах метода SHAP и его дальнейшем развитии в виде метода Shapley Flow, объединяющего интерпретацию модели и многообразия данных.
Помните этот момент из легендарного произведения Гайдая? Удивительно, насколько по-разному может восприниматься один и тот же человек с одним и тем же лицом. А когда речь идет о миллионах разных людей и нужно найти одного единственного — даже человек уже бессилен, а сверточные нейросети продолжают справляться. Такое большое количество лиц вынуждает искать новые подходы к разграничению. Один из таких подходов — модификации функций потерь, которые помогают нам не потонуть в огромных датасетах при распознавании лиц, довольно точно определяя, кто есть кто.
Под катом мы рассмотрим различные модификации кросс-энтропии для задачи распознавания лиц.