В последнее время я все чаще слышу о NoSQL и о графовых базах данных в частности. Но воспользовавшись хабропоиском с удивлением обнаружил, что статей на эту тему не так и много, а по запросу «Neo4j», так вообще 4 результата, где косвенно упоминается это название в тексте статей.
Что такое Neo4j?
 Neo4j
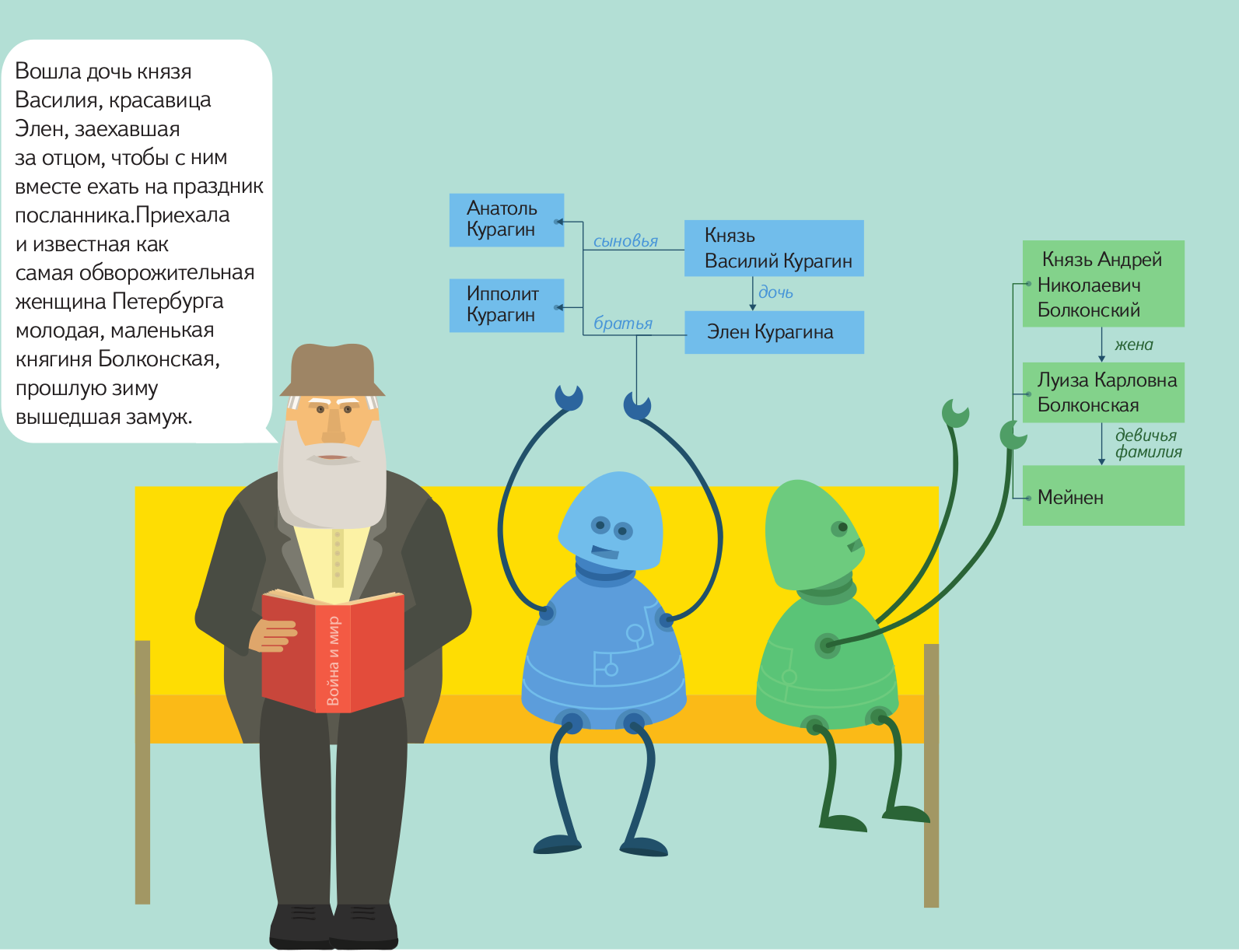
Neo4j — это высокопроизводительная, NoSQL база данных основанная на принципе графов. В ней нет такого понятия как таблицы со строго заданными полями, она оперирует гибкой структурой в виде нод и связей между ними.
Как я докатился до этого?
Уже более года я не использовал в своих проектах SQL, с того времени, как попробовал документо-ориентированную СУБД "
MongoDB". После MySQL моей радости не было предела, как все просто и удобно можно делать в MongoDB. За год, в нашей
студии создания сайтов, переписали тройку CMS, использующих основные фишки Mongo c её документами, и с десяток сайтов работающих на их основе. Всё было хорошо, и я уже начал забывать, что такое писать запросы в полсотни строк на каждое действие с БД и все бы ничего пока на мою голову не свалился проект с кучей отношений, которые ну никак не укладывались в документы. Возвращаться к SQL очень не хотелось, и пару дней я потратил чисто на поиск NoSQL решения, позволяющего делать гибкие связи — на графовые СУБД. И по ряду причин мой выбор остановился на Neo4j, одна из главных причин — это то, что мой движок был написан на PHP, а для неё был написан хороший драйвер "
Neo4jPHP", который охватывает почти 100% REST-интерфейса, предоставляющегося сервером Noe4j.








 В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.
В данном топике хотелось бы поговорить о повышении производительности при работе с таблицами.