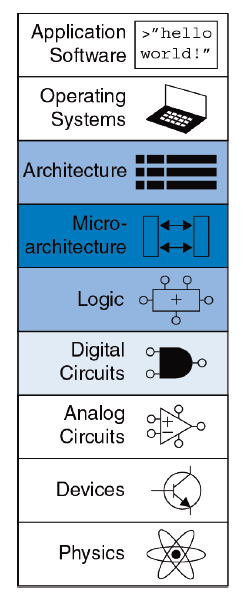
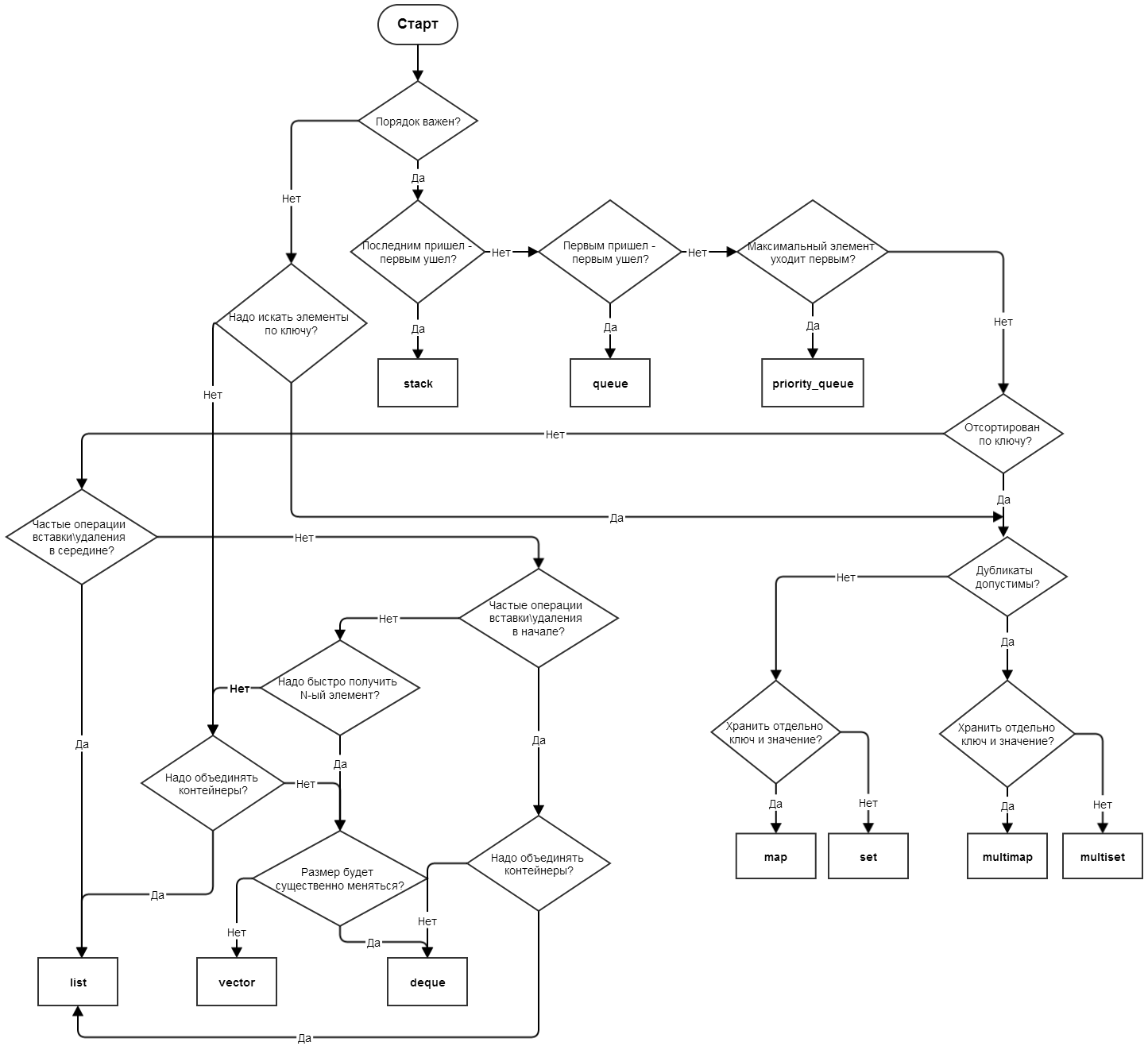
Кто такой аналитик бизнес-данных по стандарту Guide to Business Data Analytics

Закончил перевод стандарта от Международного института бизнес-анализа (IIBA) Руководство по аналитике бизнес-данных. Стандарт выстроен примерно по той же схеме что и другие стандарты IIBA:
• Введение
• Области знаний (домены).
• Типовые задачи, которые решают аналитики.
• Техники (методы работы), которые используются для решения задач.
Кроме того, в отличие, например, от стандарта BABOK Guide, здесь присутствуют значительное количество практических примеров из реальной жизни – как та или иная компания решали свои проблемы с помощью аналитики данных, а также по каждому домену приводится разбор учебного кейса – в этом Руководство по аналитике бизнес-данных легче использовать как учебник, чем BABOK Guide.
Роль аналитика бизнес-данных в данном стандарте занимает примерно такое же место как роль бизнес-аналитика в BABOK Guide.

 СУБД Neo4j — это NoSQL база данных, ориентированная на хранение графов. Изюминкой продукта является декларативный язык запросов Cypher.
СУБД Neo4j — это NoSQL база данных, ориентированная на хранение графов. Изюминкой продукта является декларативный язык запросов Cypher.




 В случае если вы разделяете данные по нескольким физическим базам данных,
В случае если вы разделяете данные по нескольким физическим базам данных,