
Каждый, кто пишет парсеры, знает, что можно распарсить сто сайтов, а на сто-первом застрять на несколько дней. Структура очередного отмороженного сайта может быть сколь угодно сложной, и, когда дело касается сжатых javascript-ов и ajax-запросов, расшифровать их и извлечь информацию с помощью обычного curl-а и регекспов становится дороже самой информации.
Грубо говоря, проблема в том, что в браузере работает javascript, а на сервере его нет. Нужно либо писать интерпретатор js на одном из серверных языков (
jParser и jTokenizer), либо ставить на сервер браузер, посылать в него запросы и вытаскивать итоговое dom-дерево.
В древности в таких случаях мы строили свой велосипед: на отдельной машине запускали браузер, в нем js, который постоянно стучался на сервер и получал от него задания (джобы), сам сайт грузился в iframe, а скрипт извне отправлял dom-дерево ифрейма обратно на сервер.
Сейчас появились более продвинутые средства —
xulrunner (
crowbar) и
watir. Первый — безголовый firefox. У crowbar есть даже
ff-плагин для визуального выделения нужных данных, который генерит специальный парсер-js-код, однако там не поддерживаются cookies, а допиливать неохота. Watir позиционируется разработчиками как средство отладки, но мы будем его использовать по прямому назначению и в качестве примера вытащим какие-нибудь данные с сайта
travelocity.com.



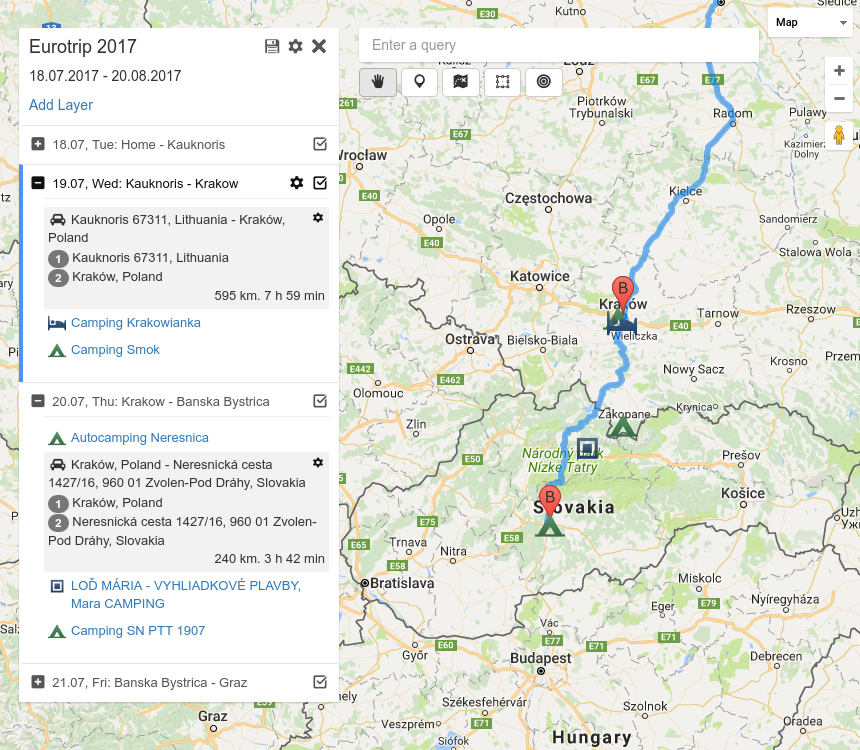
 Недавно написал одно приложение для собственного удобства, и сначала не хотел о нем рассказывать. Потом подумал, что оно может пригодиться кому-то еще. По сути это сервис для планирования автомобильных маршрутов, собранный из готовых компонентов google maps api. Это — клон
Недавно написал одно приложение для собственного удобства, и сначала не хотел о нем рассказывать. Потом подумал, что оно может пригодиться кому-то еще. По сути это сервис для планирования автомобильных маршрутов, собранный из готовых компонентов google maps api. Это — клон 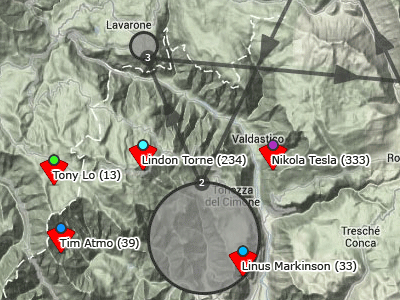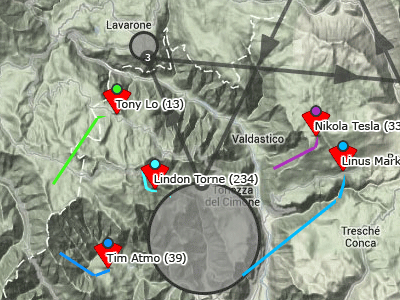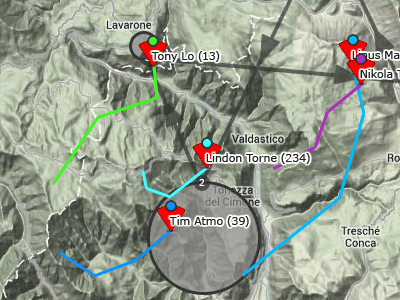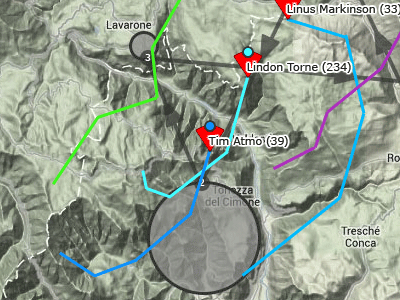
 Я тут пишу одну эпическую мегахрень, которую хочу пропиарить на хабре. Эта штука типа распределенной социальной сети. Там есть ядра с api, которые общаются по некоторому стандарту и фронтенд. Особенностью сети является то, фронтенд живет «отдельно» от ядра, то есть сеть не имеет своего домена — берем html, ставим ссылку на любое ядро и получаем сеть, которая живет поверх сайта. Внешне это похоже на
Я тут пишу одну эпическую мегахрень, которую хочу пропиарить на хабре. Эта штука типа распределенной социальной сети. Там есть ядра с api, которые общаются по некоторому стандарту и фронтенд. Особенностью сети является то, фронтенд живет «отдельно» от ядра, то есть сеть не имеет своего домена — берем html, ставим ссылку на любое ядро и получаем сеть, которая живет поверх сайта. Внешне это похоже на