O Sysdig —инструменте для трассировки ядра — мы рассказывали два года назад. Совсем недавно, в мае этого года, разработчики Sysdig представили ещё один интересный продукт: систему обнаружения аномалий Falco.

Пользователь




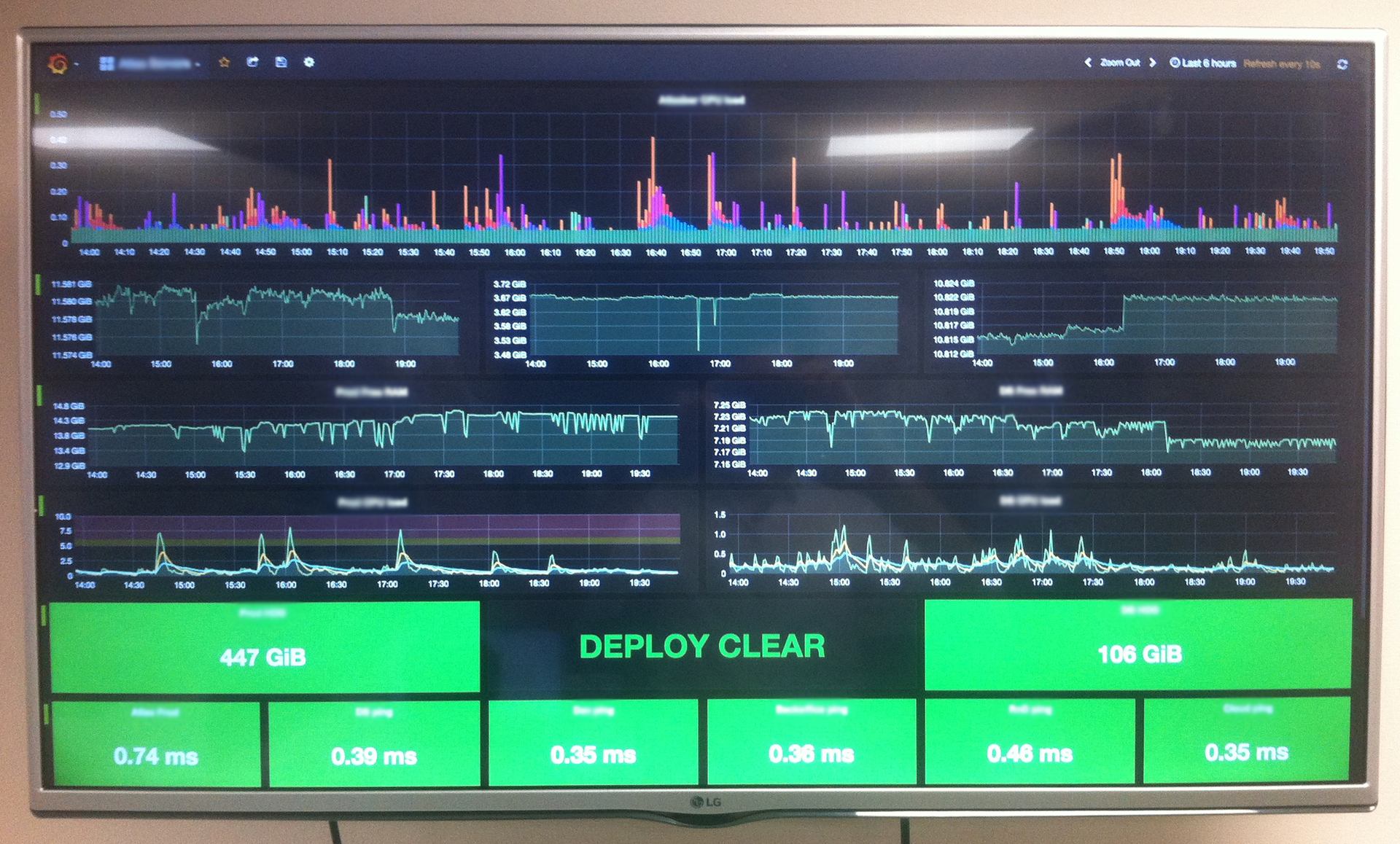
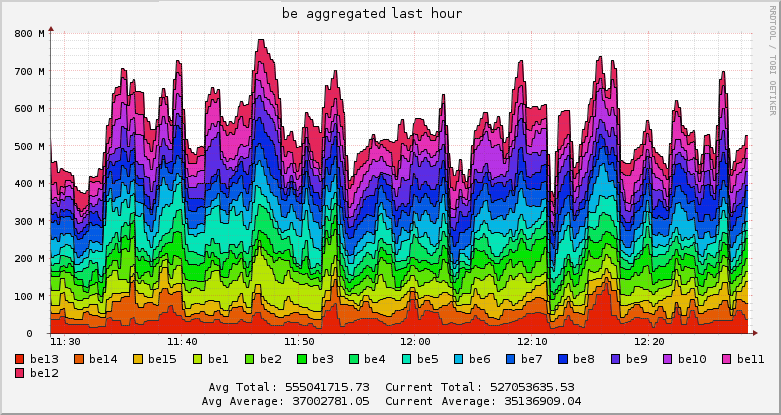
Мы в Атласе любим, когда все находится под контролем. Это касается и всей серверной инфраструктуры, которая, с годами, превратилась в живой организм из многочисленных виртуальных машин, сервисов и служб. Появилась потребность наблюдать за жизненно важными аспектами IT-составляющей нашей деятельности: мониторить боевой сервер, отслеживать изменения системных ресурсов на виртуалках баз данных, следить за ходом бизнес-процессов и тд. Встал вопрос — как же этого добиться и главное какими инструментами? Стали искать какие-то готовые решения. Перепробовали кучу платных/бесплатных сервисов, которые, якобы, предоставляли бы нам "самую ценную" информацию о состоянии нашей системы. Но, в конечном итоге, все сводилось к каким-то непонятных диаграммам, схемам и цифрам, которые, по сути, для нас не имели никакой ценности.
Так мы пришли к пониманию, что надо собирать что-то самостоятельно. За основу решили взять самую гибкую и продвинутую систему, которую можно настроить для мониторинга чего и как угодно — Nagios. Настроили, поставили, работает — круто! Жаль только интерфейс сего чуда застрял где-то в середине 90-х, а нам хотелось, чтобы еще и визуальная составляющая была на уровне.
Недолгий поиск показал, что лидером среди решений по созданию красивых дашбордов является Grafana. Так и решили выводить весь наш мониторинг из Nagios на мониторах в виде красивых графиков в Grafana. Вопрос остался только в том — как их подружить друг с другом?

Фото из Гугла, это не мама автора
Моя мама начала работать в одном из крупнейших банков ЕС ещё до моего рождения, а я всегда был неравнодушен к её специальности, особенно в последние годы, поскольку сам стал программистом. Меня много раз просили взять у нее интервью, и я, наконец, решил это сделать.
Мир банковского программного обеспечения — это другая вселенная. Она сильно отличается от той, к которой привыкло большинство из нас. Я публикую этот пост на HN и на Reddit. Публикую интервью не в виде вопросов-ответов, а в виде рассказа. Я добавил некоторые вопросы и ответы в нижнюю часть поста.
Год, когда она начала внутреннее обучение в банке Nordea, который тогда назывался Nordbanken (Северный банк). В 2001 году его переименовали в Nordea. Во время обучения она должна была проходить различные тесты, в первую очередь тест IQ, чтобы показать, что она обладает интеллектом, достаточным для работы в этой области. Тест на психологическую устойчивость — что у неё достаточно нервов для этой специфической работы и тест на многозадачность, который она завалила с оценкой 22/100. Остальные тесты она прошла успешно и заняла одну из 16 доступных позиций.
Должность звучала «как программист мэйнфреймов IBM на языке COBOL», и до сих пор, уже 25 лет, моя мама работает на этой должности в том же банке.
Эта позиция в банке самая важная, по крайней мере, с технической точки зрения. Если, скажем, мама и члены её команды одновременно бросят работу, банк разорится в лучшем случае в течение нескольких недель. Её коллектив работает посменно с круглосуточной доступностью.