Чувство боли как программная основа сильного искусственного интеллекта
4 мин
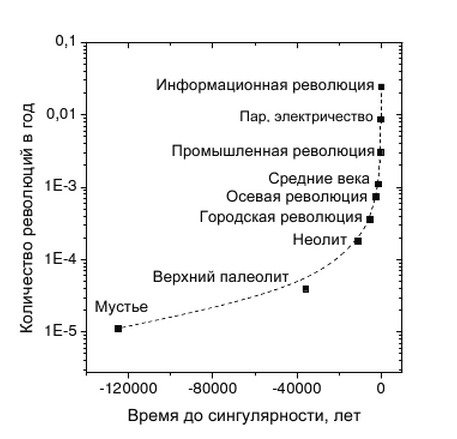
И в чём же, всё-таки, состоит основная проблема создания сильного искусственного интеллекта? «Конечно же, в отсутствии необходимого аппаратного обеспечения достаточной мощности» – скажет кто-то. И будет, конечно же, прав. Ведь если на данный момент попытаться создать хоть чуть-чуть похожий на мозг человека компьютер с триллионами нервных клеток, каждую из которых можно сравнить с отдельным компьютером со своими функциями и свойствами, то мы получим «робомозг» размером с дом. Но если представить, что прогресс всё-таки дошел до момента, когда создание подобной машины лишь вопрос денег и свободного времени, то можно поразмышлять и об алгоритме работы такой машины. Что я и сделал.
По результатам размышлений я забрёл в довольно неожиданный для себя тупик. Но начнём с самого начала, что бы всем было понятно.
По результатам размышлений я забрёл в довольно неожиданный для себя тупик. Но начнём с самого начала, что бы всем было понятно.
 В этом посте я хочу подробно рассказать о моём опыте переезда на работу PHP-разработчиком в Германию — от момента, когда есть просто желание переехать, но не знаешь что и как делать, до момента, когда уже переехал, вселился в квартиру и получил вид на жительство. Кроме того, в конце поста я приведу немного полезной информации и ссылок по переезду в некоторые другие страны.
В этом посте я хочу подробно рассказать о моём опыте переезда на работу PHP-разработчиком в Германию — от момента, когда есть просто желание переехать, но не знаешь что и как делать, до момента, когда уже переехал, вселился в квартиру и получил вид на жительство. Кроме того, в конце поста я приведу немного полезной информации и ссылок по переезду в некоторые другие страны. С завидной регулярностью на Хабре появляются статьи, рассказывающие о тех или иных методах распознавания лиц. Мы решили не просто поддержать эту замечательную тему, но выложить наш внутренний документ, который освещает пусть и не все, но многие подходы к распознаванию лиц, их сильные и слабые места. Он был составлен Андреем Гусаком, нашим инженером, для молодых сотрудников отдела машинного зрения, в образовательных, так сказать, целях. Сегодня предлагаем его все желающим. В конце статьи – впечатляющих размеров список литературы для самых любознательных.
С завидной регулярностью на Хабре появляются статьи, рассказывающие о тех или иных методах распознавания лиц. Мы решили не просто поддержать эту замечательную тему, но выложить наш внутренний документ, который освещает пусть и не все, но многие подходы к распознаванию лиц, их сильные и слабые места. Он был составлен Андреем Гусаком, нашим инженером, для молодых сотрудников отдела машинного зрения, в образовательных, так сказать, целях. Сегодня предлагаем его все желающим. В конце статьи – впечатляющих размеров список литературы для самых любознательных.


 Наверное, на любом сайте есть свои маленькие секреты и хитрости, которые позволяют сделать пользование сайтом более комфортным и удобным. Они не самоочевидны и известны не всем, но те, кто их знают, могут достигнуть желаемого результат с меньшими усилиями или более простым и быстрым способом.
Наверное, на любом сайте есть свои маленькие секреты и хитрости, которые позволяют сделать пользование сайтом более комфортным и удобным. Они не самоочевидны и известны не всем, но те, кто их знают, могут достигнуть желаемого результат с меньшими усилиями или более простым и быстрым способом.
 Недавно у меня состоялся показательный разговор с Алексеем Малановым, сотрудником «Лаборатории» и
Недавно у меня состоялся показательный разговор с Алексеем Малановым, сотрудником «Лаборатории» и