
Одним пятничным вечером несколько лет назад я получил задание от руководителя подготовить за выходные ТЗ на конкурс. Видимо, я слишком уж излучал радость от предстоящих выходных, и боссу просто было приятно занять их чем-то новым и интересным, как он считал – ведь до этого с техническими документами мне работать не доводилось. Сейчас уже не смогу припомнить, какая там была система, но точно какой-то мониторинг. Субботнее утро принесло разочарование. Миллионы ссылок, сотни статей одна другой информативнее. От одной аббревиатуры ГОСТ веяло скукой и пылью. Примерно так и началось мое знакомство с семейством ГОСТ 34 на автоматизированные системы. Под катом удобная памятка по этому самому ГОСТу, которая совершенно случайно когда-то повстречалась на просторах сети и помогла систематизировать данные в знатном ворохе документов.

 CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.
CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.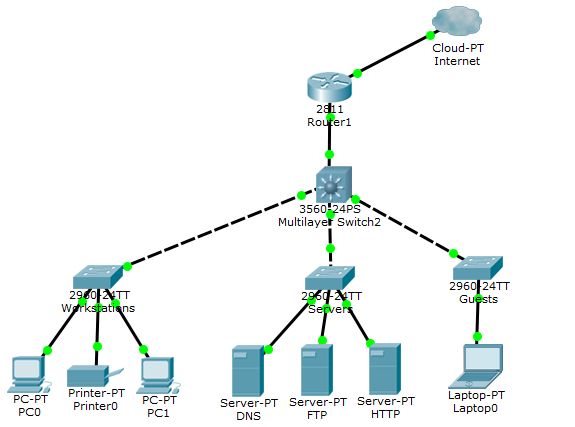
 // <какой-то код>
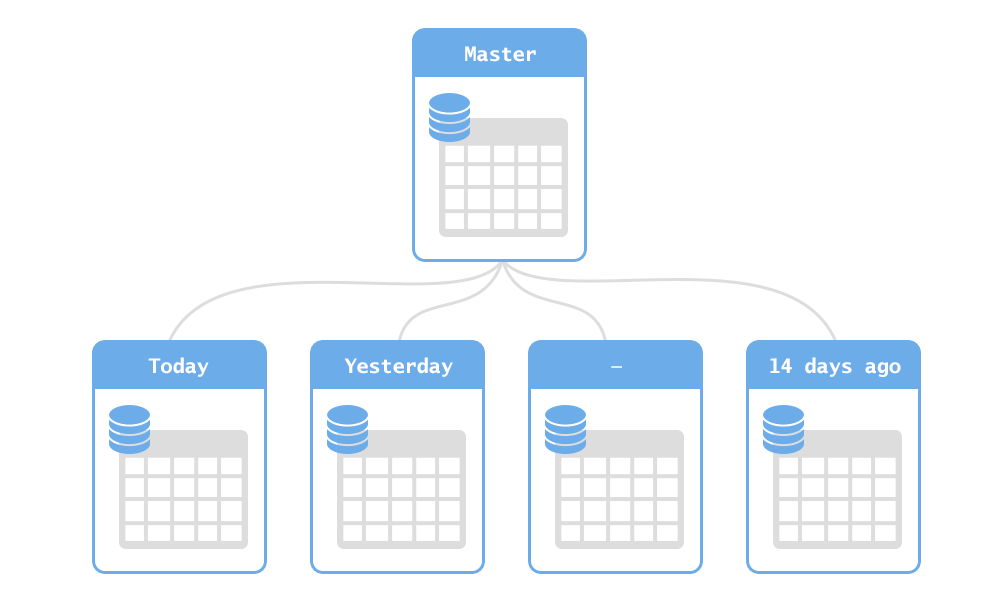
// <какой-то код> Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
