В первой части нашей темы мы рассмотрели решение задачи static RMQ за (O(nlogn), O(1)). Теперь мы разберёмся со структурой данных, называемой дерево отрезков, или интервалов (в англоязычной литературе – segment tree или interval tree). С помощью неё можно решать dynamic RMQ за (O(n), O(logn)).
Введём понятие дерева отрезков. Для удобства дополним длину массива до степени двойки. В добавленные элементы массива допишем бесконечности (за бесконечностью стоит понимать, например, число, больше которого в данных ничего не появится). Итак, дерево отрезков это двоичное дерево, в каждой вершине которого написано значение заданной функции на некотором отрезке. Функция в нашем случае – это минимум.
Каждому листу будет соответствовать элемент массива с номером, равным порядковому номеру листа в дереве. А каждой вершине, не являющейся листом, будет соответствовать отрезок из элементов массива соответствующих листам-потомкам этой вершины.
Определение
Введём понятие дерева отрезков. Для удобства дополним длину массива до степени двойки. В добавленные элементы массива допишем бесконечности (за бесконечностью стоит понимать, например, число, больше которого в данных ничего не появится). Итак, дерево отрезков это двоичное дерево, в каждой вершине которого написано значение заданной функции на некотором отрезке. Функция в нашем случае – это минимум.
Каждому листу будет соответствовать элемент массива с номером, равным порядковому номеру листа в дереве. А каждой вершине, не являющейся листом, будет соответствовать отрезок из элементов массива соответствующих листам-потомкам этой вершины.
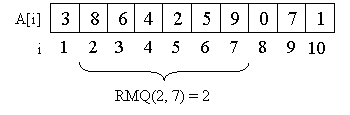

 Вы PM. Как узнать – готова ли вёрстка к реальному использованию?
Вы PM. Как узнать – готова ли вёрстка к реальному использованию?