
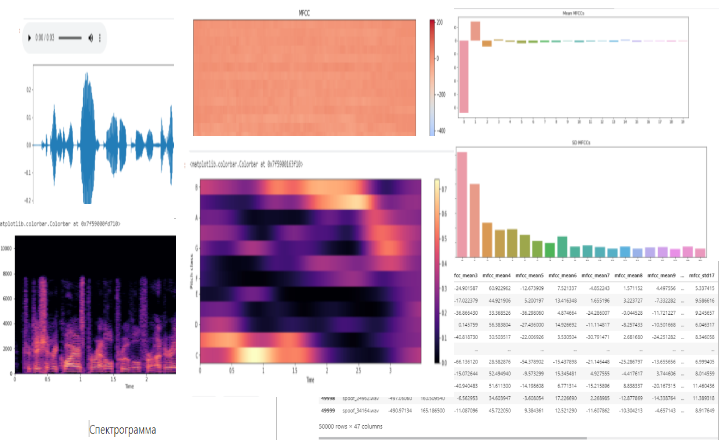
Каждый аудиосигнал содержит характеристики. Из MFCC (Мел-кепстральных коэффициентов), Spectral Centroid (Спектрального центроида) и Spectral Rolloff (Спектрального спада) я провела анализ аудиоданных и извлекла характеристики в виде среднего значения, стандартного отклонения и skew (наклон) с помощью библиотеки librosa.
Для классификации “живого” голоса (класс 1) и его отделению от синтетического/конвертированного/перезаписанного голоса (класс 2) я использовала алгоритм машинного обучения - SVM (Support Vector Machines) / машины опорных векторов. SVM работает путем сопоставления данных с многомерным пространством функций, чтобы точки данных можно было классифицировать, даже если данные не могут быть линейно разделены иным образом. Для работы я использовала математическую функцию, используемой для преобразования (известна как функция ядра) - RBF (радиальную базисную функцию).
В первой части анализа аудиоданных разберем: