
ML-Блиц: разбор задач первого квалификационного раунда
23 июня 2018 года состоялся финал ML-Блица, конкурса по машинному обучению, организованного Яндексом. Ранее мы анонсировали его на Хабре и рассказывали, какие примерно задачи могут встретиться на реальном соревновании.
Теперь мы хотим поделиться с вами разборами задач одного из квалификационных раундов — самого первого. Двое участников сумели решить все задачи этого соревнования; 57 участников решили хотя бы одну задачу, а 110 совершили хотя бы по одной попытке сдать задание.
Хотя автор этих строк принимал участие в составлении задач конкурса, именно в первой квалификации его задачи не принимали участие. Так что я пишу этот разбор с позиции участника конкурса, который впервые увидел условия и хотел как можно быстрее получить как можно больше баллов.
Самым популярным языком программирования среди участников соревнования ожидаемо оказался python, поэтому я также использовал именно этот язык во всех случаях, когда требовалось написать код.
Все мои решения доступны на GitHub





 Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.
Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.
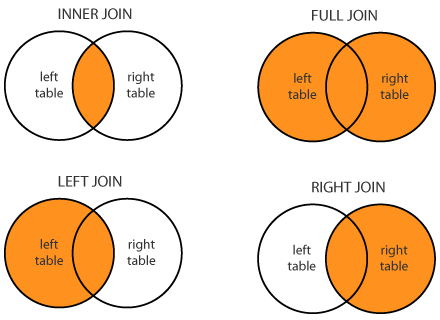
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
