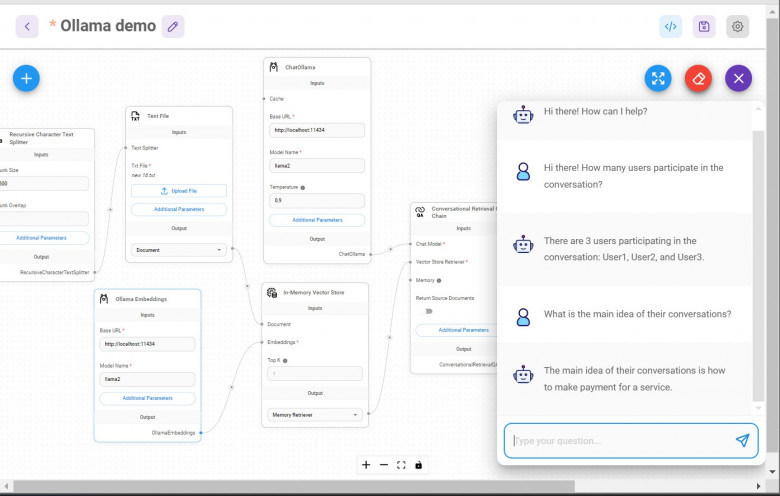
В этой статье о том, как без написания кода поставить себе локально и использовать LLM без подключения к сети. Для меня это удобный способ использования в самолёте или in the middle of nowhere. Заранее выгрузив себе нужные файлы, можно делать анализ бесед саппорта с клиентами, или получить саммарайз отзывов из стора на приложение, или оценить резюме/тестовое задание кандидата...
Анализ текстовых данных становится все более важным в наше время, когда огромные объемы информации генерируются и обмениваются каждую секунду. От социальных медиа до новостных порталов, от клиентских отзывов до академических статей — текстовые данные содержат бесценные знания и инсайты. Однако извлечение значимой информации из таких объемов текста может быть огромным вызовом.
Компании хотят понимать общественное мнение о своих продуктах и брендах, но анализировать миллионы постов и комментариев вручную практически невозможно. Вот где анализ текстовых данных и тематическое моделирование приходят на помощь. Эти методы позволяют автоматически выявлять темы, тональность и структуру текста, делая процесс анализа эффективным и масштабируемым.
Poetry - это инструмент для управления зависимостями в Python проектах (аналог встроенного pip). Идея реализации данного инструмента пришла его создателю в связи с тем, что различные способы менеджмента пакетов (requirements.txt, setup.cfg, MANIFEST.ini и другие) показались создателю Poetry не очень-то удобными.
Предлагаю тем, кто пишет на Python, познакомиться с данным инструментом, так как это очень простой и удобный в использовании инструмент, применение которого может упростить ведение и разработку проекта.
Мы команда разработчиков Института Системного Программирования РАН, занимаемся Computer Vision в обработке электронных документов. Мы разработали open-source библиотеку dedoc, которая помогает разработчикам и дата-сайентистам в пару строк кода читать различные форматы текстовых документов и изображений с текстом, и далее приводить информацию к единой аккуратной структуре.
Чтобы найти настоящие таланты, компаниям приходится придумывать самые необычные способы поиска. В EPAM тоже любят искать новые пути решения привычных задач. Этот эксперимент начался с того, что наши рекрутеры обратились к коллегам из Data-практики и попросили подумать над тем, как можно было бы создать систему поиска кандидатов на открытые вакансии в компании. Систему, которая бы помогла снизить временные затраты на поиск релевантного кандидата в открытых источниках*, а также увеличила бы качество и количество хороших кандидатов. За задачу взялась наша Data Science команда совместно со студентами Тренинг-центра EPAM. Далее я расскажу об основных подходах, которыми можно решать подобную задачу, нашем решении и результатах. В целом пост получился скорее справочный, но через призму конкретного бизнес-кейса. Также я постарался оставить ссылки, где это мне кажется релевантным, чтобы можно было подробнее узнать про ту или иную технологию или подход.
* — сайты и ресурсы, где кандидаты, пользователи сами размещают о себе информацию. Доступ к этим ресурсам не ограничен, в том числе лицензиями и условиями предоставления услуг этих ресурсов (Terms of service).