В данном топике я собираюсь свести все свои знания об анимации в MooTools воедино и рассмотреть темы, более углубленные, чем просто примеры использования плагинов. Теоретическая информация справедлива не только для MooTools, но и для других фреймворков. Начинающим будет интересно ознакомиться с возможностями фреймворка, а продолжающим — понять, как все это работает :). В статье приведено много примеров, есть довольно оригинальные, вот некоторые из них: 1, 2, 3. Приятного вам чтения.

encore @encore
Пользователь
Фильтр для типографики
2 мин
Недавно Игорь Кононученко выложил версию типографа, написанного на Питоне. Игорю большое человеческое спасибо. А я скромно решил сделать из библиотеки типографический фильтр для django. Не то, чтобы это сложно — но новичкам, вроде меня, может пригодиться. Что, собственно, получилось.
120 dpi и шрифты в em
8 мин
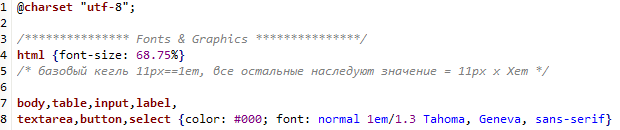
Шрифты в Em/% хороши всем — возможностью пользователей IE увеличивать кегль, заботой о пользователях, что предпочитают увеличивать размер шрифта браузера по-умолчанию, чтоб лучше видеть текст, да и просто являются нормой для профессиональных верстальщиков.
Минусы: … их вроде как нет, но!
А что если у пользователя разрешение экрана выставлено не в стандартное 96 dpi, а в 120?
Сайт с увеличенными шрифтами смотрится уже не так красиво, как нарисовал дизайнер — ведь масштабируются только шрифты, а не весь сайт! А разрешение 120dpi становится всё популярней, особенно на ноутбуках! Что же делать? Возвращаться к px?
Нет!
Expert Python Programming
2 мин
 Совсем недавно (24.09.08) Tarek Ziadé анонсировал публикацию своей замечательной книги (IMHO).
Совсем недавно (24.09.08) Tarek Ziadé анонсировал публикацию своей замечательной книги (IMHO). Для кого написана
В первую очередь она предназначена для людей, обладающих опытом программирования на языке Python, и желающих повысить свои навыки.
Expert Python Programming это не очередная книга о синтаксисе языка программирования Python, это книга о платформе Python, об основных библиотеках и инструментах, используемых для написания профессиональных приложений. В ней рассматриваются такие процессы разработки программного обеспечения, как непрерывная интеграция, документация, тестирование, релизинг, рефакторинг и прочее.
Из книги вы узнаете какие использовать IDE, DVCS, фреймворки тестирования, технику оптимизации; как выпускать и поддерживать разработанные приложения; как документировать код, используя reStructuredText и Sphynx; как распространять с помощью setuptools и других инструментов (PasteScript, zc.buildout, builbots); как использовать систему issue/bag трекинга Trac.
Ссылки
* Детальная информация о книге
* Подробный обзор Мишеля Симонато (Michele Simionato)
* Блог автора
* Chapter 10, Documenting Your Project. [PDF 3MB]
Делаем вращательный регулятор.
11 мин
Этим топиком я продолжаю цикл статей о написании всяких вкусностей для MooTools. Сегодня мы на чистом JavaScript сделаем вращательный регулятор — контрол, который часто используют в работающих со звуком программах для регулировки громкости или баланса. Вот примерно такой:

Некоторые инженерные практики для улучшения качества web application на PHP
2 мин
Этот топик мой ответ на жалобу одного человека, что «баги достали».
Для начала, никакая методология положения не спасет. Начинать нужно с инженерных практик – внедрив их и почувствовав уверенность в своем коде можно внедрять любую методологию.
Первые задачи могут быть такие:
Для начала, никакая методология положения не спасет. Начинать нужно с инженерных практик – внедрив их и почувствовав уверенность в своем коде можно внедрять любую методологию.
Первые задачи могут быть такие:
- Обеспечить интеграционное тестирование, чтобы каждое обновление на production не было головной болью.
- Обеспечить регрессионное тестирование – чтобы выявленные ошибки не возникали опять (отслеживались автоматически).
Компоненты Zend Framework отдельно
1 мин
Яни Хартикайнен практикуясь в использовании Tokenizer-а PHP написал очень полезную штуку, позволяющую скачать в ZIP отдельные части Zend Framework со всеми зависимостями. Например, для Zend_Acl скачаются
Пользуемся
Zend/Acl.php Zend/Acl/Resource/Interface.php Zend/Acl/Role/Registry.php Zend/Acl/Role/Interface.php Zend/Acl/Role/Registry/Exception.php Zend/Acl/Exception.php Zend/Exception.php Zend/Acl/Assert/Interface.php
Пользуемся
Bit Mask Resurrection
3 мин
По мотивам топиков:
Упаковка булевых переменных для хранения и поиска в базе
Хранение набора чекбоксов в одном поле БД. Битовая маска.
В этих топиках была похоронена замечательная идея. Что ж, попробуем её возродить ещё раз…
Упаковка булевых переменных для хранения и поиска в базе
Хранение набора чекбоксов в одном поле БД. Битовая маска.
В этих топиках была похоронена замечательная идея. Что ж, попробуем её возродить ещё раз…
Nginx UploadProgress Module
2 мин
Модуль для nginx, с помощью которого достаточно просто мониторить прогресс загрузки файлов на сервер. Ранее были подобные решения, через модули к php, ruby, через стороние скрипты, flash объекты итп. Автор предлагает универсальное решение на уровне web сервера. Подробную информацию и инструкции вы можете найти на wiki.codemongers.com (кстати, один из лучших проектов, посвященных nginx`у). Тут я хотел обратить внимание на другое.
Использовал модуль совместно с nginx upload module, работает на ура. Однако файлы, что я заливаю, достаточно большие (поддерживаю файлообменник), пытался запихнуть в директиву upload_progress размер обрабатываемых файлов — 1g, при релоаде nginx`а получил варнинг, мол непонятный размер вы поставили. Странно, т.к. в client_max_body_size у меня стоит 1g и нормально себя чувствует. Глянул исходники nginx`а и модуля, выяснелось, что модуль обрабатывает директиву upload_progress функцией ngx_parse_size, тогда как сам nginx обрабатывает ту же client_max_body_size соседней функцией ngx_parse_offset, функции абсолютно идентичны (на мой взгляд), разве что первая не понимает размерность «g», а вторая понимает =) Для того, чтобы модуль нормально обрабатывал размерность в директиве upload_progress, надо в исходнике модуля (ngx_http_uploadprogress_module.c) в строчке 1151 исправить ngx_parse_size на ngx_parse_offset.
В общем это не критично, т.к. директива нормально обрабатывает значение 1024m, но как-то нелепо выглядит подобная запись =)))
А вообще модуль очень понравился, очень удобное решение, не зависящее от бэк-енда.
update: Внимание, совершил глупую ошибку. Стыдно. Деректива upload_progress задает не максимальный размер загружаемых файлов для указанной зоны, как я думал, а размер оперативной памяти, выделяемой для обсчета одной загрузки в эту зону. Значение для этой дерективы — 1,2m, максимум 10-20m. Задавая 1g вы будете тратить гигабайт оперативки на каждую загрузку. Стыдно, ошибку не повторяйте.
p.s. тем не менее баг найден, автору сообщил, он обещал исправить.
Использовал модуль совместно с nginx upload module, работает на ура. Однако файлы, что я заливаю, достаточно большие (поддерживаю файлообменник), пытался запихнуть в директиву upload_progress размер обрабатываемых файлов — 1g, при релоаде nginx`а получил варнинг, мол непонятный размер вы поставили. Странно, т.к. в client_max_body_size у меня стоит 1g и нормально себя чувствует. Глянул исходники nginx`а и модуля, выяснелось, что модуль обрабатывает директиву upload_progress функцией ngx_parse_size, тогда как сам nginx обрабатывает ту же client_max_body_size соседней функцией ngx_parse_offset, функции абсолютно идентичны (на мой взгляд), разве что первая не понимает размерность «g», а вторая понимает =) Для того, чтобы модуль нормально обрабатывал размерность в директиве upload_progress, надо в исходнике модуля (ngx_http_uploadprogress_module.c) в строчке 1151 исправить ngx_parse_size на ngx_parse_offset.
В общем это не критично, т.к. директива нормально обрабатывает значение 1024m, но как-то нелепо выглядит подобная запись =)))
А вообще модуль очень понравился, очень удобное решение, не зависящее от бэк-енда.
update: Внимание, совершил глупую ошибку. Стыдно. Деректива upload_progress задает не максимальный размер загружаемых файлов для указанной зоны, как я думал, а размер оперативной памяти, выделяемой для обсчета одной загрузки в эту зону. Значение для этой дерективы — 1,2m, максимум 10-20m. Задавая 1g вы будете тратить гигабайт оперативки на каждую загрузку. Стыдно, ошибку не повторяйте.
p.s. тем не менее баг найден, автору сообщил, он обещал исправить.
MemcacheDB и MemcacheQ — ключевые компоненты высокопроизводительной инфраструктуры
5 мин
Cегодня мы поговорим о компонентах для высокопроизводительной и масштабируемой архитектуре на основе сервера memcached, а именно — распределённой базе для хранения данных MemcacheDB и системы очередей сообщений MemcacheQ.

Сначала рассмотрим, а что у нас есть в распоряжении для создания распределённой инфраструктуры хранения данных для веб-приложения. Ну, первое, что приходит в голову — кластеризация базы данных, это теперь поддерживается во всех распространённых системах, а также различные технологии репликации. Например, самая популярная СУБД для веб-проектов, MySQL поддерживает как репликации так и кластеризацию. Ещё можно обратится к традиционным файловым система и хранить данные в файловой системе, к примеру, Apache Hadoop. Но часто это слишком высокоуровневое решение, обычно же требуется гораздо проще варианты — когда нужно хранить и оперировать просто парами ключ-значение. Если серьёзно посмотреть, такая функциональность позволит покрыть потребности 90% веб-приложений. А если мы прибавим к этому возможность очень и очень быстро оперировать данными, хранить их в виде распределённой многосерверной системе и возможность постоянного хранения, устойчивого к сбоям — получим очень привлекательную платформу.
Сначала рассмотрим, а что у нас есть в распоряжении для создания распределённой инфраструктуры хранения данных для веб-приложения. Ну, первое, что приходит в голову — кластеризация базы данных, это теперь поддерживается во всех распространённых системах, а также различные технологии репликации. Например, самая популярная СУБД для веб-проектов, MySQL поддерживает как репликации так и кластеризацию. Ещё можно обратится к традиционным файловым система и хранить данные в файловой системе, к примеру, Apache Hadoop. Но часто это слишком высокоуровневое решение, обычно же требуется гораздо проще варианты — когда нужно хранить и оперировать просто парами ключ-значение. Если серьёзно посмотреть, такая функциональность позволит покрыть потребности 90% веб-приложений. А если мы прибавим к этому возможность очень и очень быстро оперировать данными, хранить их в виде распределённой многосерверной системе и возможность постоянного хранения, устойчивого к сбоям — получим очень привлекательную платформу.
Автоматизация разработки web проектов в среде UNIX
2 мин
С какого боку не посмотри, а процесс автоматизации всегда важен. Компаниям он помогает экономить уйму времени-денег, администраторов избавляет от рутины, а людей не посвящённых в детали чужой работы от головной боли.
Я хочу поделиться своим решением по задаче частичной оптимизации и снижения производственных издержек. Мне пришлось написать данный bash скрипт по причинам, которые были озвучены выше. Есть ещё причина,
Хочу сразу предупредить непосвящённых о том, что конфигурация Apache, MySQL может отличаться от приведённой ниже( а так скорее всего и будет). Будьте внимательнее в корректировке путей, когда решите адаптировать этот скрипт под свои цели.
Я хочу поделиться своим решением по задаче частичной оптимизации и снижения производственных издержек. Мне пришлось написать данный bash скрипт по причинам, которые были озвучены выше. Есть ещё причина,
Хочу сразу предупредить непосвящённых о том, что конфигурация Apache, MySQL может отличаться от приведённой ниже( а так скорее всего и будет). Будьте внимательнее в корректировке путей, когда решите адаптировать этот скрипт под свои цели.
MySQL Query Cache
5 мин
В MySQL есть очень полезная функциональность — кеш запросов. Кеш запросов доступен в MySQL начиная с версии 4.0.
Многие СУБД имеют подобную функциональность, но в отличие от MySQL они кешируют планы выполнения запросов, тогда как MySQL кеширует результаты запросов.
Дальше о том, как работает кеш запросов, как его настраивать и оптимально использовать.
Многие СУБД имеют подобную функциональность, но в отличие от MySQL они кешируют планы выполнения запросов, тогда как MySQL кеширует результаты запросов.
Дальше о том, как работает кеш запросов, как его настраивать и оптимально использовать.
Пишем RSS-читалку на Flex
5 мин
Перевод
Попробуем сделать при помощи Flex простое приложение. Впрочем, это не будет обычный Hello World, это будет нечто более полезное.
Но перед тем, как попробовать сделать что-нибудь с помощью Flex, разберемся, какие возможности появились в новой версии.
Но перед тем, как попробовать сделать что-нибудь с помощью Flex, разберемся, какие возможности появились в новой версии.
Многопроцессовые демоны на PHP
3 мин
Зачем может понадобиться писать демоны на PHP?
- Выполнение трудоемких фоновых задач;
- выполнение задач, которые длятся больше, чем время ожидания при HTTP-запросе (30 секунд);
- выполнение задач на более высоком уровне доступа, чем серверный процесс (читай — под рутом).
MySQL Performance real life Tips and Tricks. Part 3-rd.
14 мин
Решил продолжить цикл заметок по данной тематике. В данной статье особое место хотел уделить профайлингу MySQL запросов. Описать средства, которые предоставляются MySQL для профайлинга, и что нужно делать для определения узких мест запроса.
Также, после опубликования первых двух статей я получил пару отзывов и вопросов, связанных с проектированием БД / расстановкой индексов / составлением запросов. На многие вопросы старался отвечать. С некоторыми из них поделюсь и в этой статье.
Также, после опубликования первых двух статей я получил пару отзывов и вопросов, связанных с проектированием БД / расстановкой индексов / составлением запросов. На многие вопросы старался отвечать. С некоторыми из них поделюсь и в этой статье.
Что нового в MySQL 5.1
3 мин
Осталось совсем немного времени до выхода MySQL 5.1. В статье будут рассмотрены изменения и новые возможности этой версии.
На чем работает Digg
2 мин
Главный архитектор Digg.com Джо Стамп (Joe Stump) рассказал в корпоративном блоге о том, как на данный момент устроен и работает крупнейший новостной агрегатор, находящийся на 142 месте по посещаемости в рейтинге Alexa.com.

Защита от DDos. Простой, но эффективный скрипт
1 мин
Недавно озаботился поиском адекватного решения для защиты некоторых подконтрольных ресурсов от DDos атак.
Первое что посоветовали — Cisco Guard. Но так как требовалось что то легкое и не столь дорогое, то решил посмотреть в сторону софтверных продуктов.
После непродолжительного гугления наткнулся на небольшой скриптик (D)DoS-Deflate
Первое что посоветовали — Cisco Guard. Но так как требовалось что то легкое и не столь дорогое, то решил посмотреть в сторону софтверных продуктов.
После непродолжительного гугления наткнулся на небольшой скриптик (D)DoS-Deflate
MySQL Performance real life Tips and Tricks
9 мин
Пообещал вчера написать статью о реальных случаях оптимизации БД MySQL.
Пришлось сегодня вставать утром пораньше чтобы воплотить обещанное в жизнь.
Централизованное управление мыслями поддерживать еще сложно, поэтому не судите строго за казусы и ляпсусы в моей статье.
В последнее время приходится достаточно часто заниматься оптимизацией производительности сайтов. И как правило «бутылочным горлышком» в производительности работы этих сайтов является именно БД, ошибки как в архитектуре так и в выполнении запросов. Начиная от неправильной расстановки индексов, либо совершенным их отсутствием, неправильным (неэкономным) выбором типов данных под определенное поле, заканчивая абсолютно нелогичной архитектурой БД и такими же нелогичными запросами.
В данной статье опишу несколько приемов, которые были использованы для приложения с 4млн+ пользователей и которое имея порядка 100млн+ хитов в сутки, а в конце опишу задачу, которая решалась недавно и может быть многоуважаемое сообщество предложит мне решения этой задачи более эффективное нежели то, к которому пришел я.
Пришлось сегодня вставать утром пораньше чтобы воплотить обещанное в жизнь.
Централизованное управление мыслями поддерживать еще сложно, поэтому не судите строго за казусы и ляпсусы в моей статье.
В последнее время приходится достаточно часто заниматься оптимизацией производительности сайтов. И как правило «бутылочным горлышком» в производительности работы этих сайтов является именно БД, ошибки как в архитектуре так и в выполнении запросов. Начиная от неправильной расстановки индексов, либо совершенным их отсутствием, неправильным (неэкономным) выбором типов данных под определенное поле, заканчивая абсолютно нелогичной архитектурой БД и такими же нелогичными запросами.
В данной статье опишу несколько приемов, которые были использованы для приложения с 4млн+ пользователей и которое имея порядка 100млн+ хитов в сутки, а в конце опишу задачу, которая решалась недавно и может быть многоуважаемое сообщество предложит мне решения этой задачи более эффективное нежели то, к которому пришел я.