По долгу службы мне время от времени приходится копировать, архивировать, разархивировать и проводить другие стандартные действия с большими файлами. Консольные утилиты, типа cp, tar или cat — отлично справляются с поставленной перед ними задачей, но возникает одна маленькая проблема: предположим, что надо заархивировать SQL-дамп на 500 Мб, на среднем железе данная операция может выполняться 5 — 10 минут и при этом, стандартный tar не выводит никакой строки прогресса, т.е. консоль как бы подвисает и только открыв top в соседнем окне можно понять что что-то происходит. Я думаю, что будет намного удобнее, если в консоли появится полоска прогресса как в том же scp и тогда пользователь будет лучше осведомлен о том, как долго ему осталось ждать до завершения операции.

Михаил Крестьянинов @krestjaninoff
Пользователь
OCaml и PHP — эзотерика для вашего удобства
9 мин
NB: читая этот топик, желательно не есть — можно поперхнуться от неожиданности.
NB: менее ценные куски кода пришлось вынести на пастебин, из-за того что хабр обрезает пост. Следите за ссылками в тексте.
Многие причисляют OCaml к маргинальным и даже эзотерическим языкам. Возможно они и правы, хотя множество людей с ними не согласны. Для меня знакомство с ним началось с полгода назад, когда мне в очередной раз захотелось научиться чему-то новому и я подумал, что хоть один функциональный язык надо освоить. Из множества языков я выбрал Objective Caml. Язык покорил меня человеческим синтаксисом и идеей: есть все функциональные радости жизни, но если хочешь императивный стиль и ООП — бери, их есть у меня! Оказалось, что разработчики прекрасно понимали, что для разных задач нужны разные средства. Три дня чтения мануала для C++ и Perl-программистов и я уже вполне мог читать код и писать хеллоуворлды. На этом моё знакомство с языком закончилось, потому что изучать язык не на реальной задаче — дело глупое.
NB: менее ценные куски кода пришлось вынести на пастебин, из-за того что хабр обрезает пост. Следите за ссылками в тексте.
Многие причисляют OCaml к маргинальным и даже эзотерическим языкам. Возможно они и правы, хотя множество людей с ними не согласны. Для меня знакомство с ним началось с полгода назад, когда мне в очередной раз захотелось научиться чему-то новому и я подумал, что хоть один функциональный язык надо освоить. Из множества языков я выбрал Objective Caml. Язык покорил меня человеческим синтаксисом и идеей: есть все функциональные радости жизни, но если хочешь императивный стиль и ООП — бери, их есть у меня! Оказалось, что разработчики прекрасно понимали, что для разных задач нужны разные средства. Три дня чтения мануала для C++ и Perl-программистов и я уже вполне мог читать код и писать хеллоуворлды. На этом моё знакомство с языком закончилось, потому что изучать язык не на реальной задаче — дело глупое.
Что интересного нам расскажет EXPLAIN EXTENDED?
6 мин
Перевод
Большинство разработчиков на MySQL знакомы с командой EXPLAIN, однако значительно меньше людей знают о команде EXPLAIN EXTENDED, появившуюся ещё в MySQL 4.1, и ещё меньше умеют ею пользоваться.
EXPLAIN EXTENDED умеет показывать, что же конкретно делает с Вашим запросом оптимизатор MySQL. Для разработчика может быть совсем не очевидно, насколько сильно может отличаться написанный им запрос от того, который в действительности будет выполнен сервером. Этот процесс называется механизмом перезаписи запросов (query-rewrite), и он является частью любого хорошего SQL-оптимизатора. Команда EXPLAIN EXTENDED добавляет дополнительные предупреждения (warnings) к выводу команды EXPLAIN, в том числе и переписанный SQL-запрос.
EXPLAIN EXTENDED умеет показывать, что же конкретно делает с Вашим запросом оптимизатор MySQL. Для разработчика может быть совсем не очевидно, насколько сильно может отличаться написанный им запрос от того, который в действительности будет выполнен сервером. Этот процесс называется механизмом перезаписи запросов (query-rewrite), и он является частью любого хорошего SQL-оптимизатора. Команда EXPLAIN EXTENDED добавляет дополнительные предупреждения (warnings) к выводу команды EXPLAIN, в том числе и переписанный SQL-запрос.
PHP модуль — это просто
3 мин
Недавно мы опубликовали визард для VisualStudio, с помощью которого можно создать экстеншн в пару кликов мыши. Теперь с помощью него мы напишем наши два первых расширения: «Привет, мир» и «вытащим иконку из exe».
Сразу прошу прощение, что очень сильно задержал статью, но жизненные обстоятельства вынудили это сделать, но они исключительно уважительные.


Сразу прошу прощение, что очень сильно задержал статью, но жизненные обстоятельства вынудили это сделать, но они исключительно уважительные.
Мемоизация в Java
9 мин
Мемоизация — (Memoization, англ) вариант кеширования, заключающийся в том, что для функции создаётся таблица результатов, и будучи вычисленной при определённых значениях параметров результат заносится в эту таблицу. В дальнейшем результат берётся из данной таблицы.
Эта техника позволяет засчёт использования дополнительной памяти ускорить работу программы.Данный подход очень частно применяется в функциональных языках программирования, однако и в императивных ему так же можно найти применение. В данном топике рассматривается использование мемоизации в языке java приводятся различные примеры мемоизации и в конце производится небольшое сравнение производительности данных методов.
Эта техника позволяет засчёт использования дополнительной памяти ускорить работу программы.Данный подход очень частно применяется в функциональных языках программирования, однако и в императивных ему так же можно найти применение. В данном топике рассматривается использование мемоизации в языке java приводятся различные примеры мемоизации и в конце производится небольшое сравнение производительности данных методов.
Сервер на стероидах: FreeBSD, nginx, MySQL, PostgreSQL, PHP и многое другое
16 мин

Введение
С момента написания мной предыдущей статьи по оптимизации этой связки прошло довольно много времени. Тот многострадальный Pentium 4 c 512Мб памяти, обслуживающий одновременно до тысячи человек на форуме и до 150,000 пиров на трекере уже давно покоится на какой-нить немецкой, свалке, а клуб сменил уже не один сервер. Всё сказанное в ней всё ещё остаётся актуальным, однако есть вещи которые стоит добавить.
Статья большая, так что будет поделена на логические блоки:
0. Зачем вообще что-то оптимизировать? 1. Оптимизация ОС (FreeBSD) 1.1 Переход на 7.х 1.2 Переход на 7.2 1.3 Переход на amd64 1.4 Разгрузка сетевой подсистемы 1.5 FreeBSD и большое кол-во файлов 1.6 Softupdates, gjournal и mount options 2. Оптимизация фронтенда (nginx) 2.1 Accept Filters 2.2 Кеширование 2.3 AIO 3. Оптимизация бэкенда 3.1 APC 3.1.1 APC locking 3.1.2 APC hints 3.1.3 APC fragmentation 3.2 PHP 5.3 4. Оптимизация базы данных 4.1 MySQL 4.1.1 Переход на 5.1 4.1.2 Переход на InnoDB 4.1.3 Встроеный кеш MySQL - Query Cache 4.1.4 Индексы 4.2 PostgreSQL 4.2.1 Индексы 4.2.2 pgBouncer и другие. 4.2.3 pgFouine 4.3 Разгрузка базы данных 4.3.1 SphinxQL 4.3.2 Не-RDBMS хранилище 4.4 Кодировки 4.5 Асинхронность Приложение. Мелочи. 1. SSHGuard или альтернатива. 2. xtrabackup 3. Перенос почты на другой хост 4. Интеграция со сторонним ПО 5. Мониторинг 6. Минусы оптимизации
Тестирование Spring приложений. Транзакции в тестировании
6 мин

Про полезность подхода TDD (разработка через тестирование, test driven development) не слышал только ленивый или глухой. Но сегодня мы не будем обсуждать всю его полезность и красоту, а также проблемы и недостатки. Сегодня мы попробуем посмотреть, как разрабатывать unit-тесты для spring приложений. Также мы немного тронем ручное управление транзакциями в unit-тестах.
Горячие клавиши ctrl+shift+[key] и переключение языков по ctrl+shift (решено)
1 мин
Проблема: При настройке переключения раскладок на ctrl+shift горячие клавиши вида ctrl+shift+ отказываются работать.
Оказывается совсем недавно (буквально месяц назад) Илья Муравьев написал патч, исправляющий данное недоразумение. Суть сводится к тому что переключение языка после патча срабатывает не на нажатие, а на отпускание кнопок ctrl+shift.
Тема про баг четырехлетней давности на лаунчпаде и на фридесктоп.орг. Сам патч.
Оказывается совсем недавно (буквально месяц назад) Илья Муравьев написал патч, исправляющий данное недоразумение. Суть сводится к тому что переключение языка после патча срабатывает не на нажатие, а на отпускание кнопок ctrl+shift.
Тема про баг четырехлетней давности на лаунчпаде и на фридесктоп.орг. Сам патч.
Пример web-проекта на VS2010
9 мин
Выход VS 2010 для меня, в первую очередь, это возможность работать с .Net 4, Entity Framework 4, ASP.NET MVC 2.
Все полученные теоретические знания, на мой взгляд должны быть выражены в практическом опыте. Поэтому как только представилась возможность, я реализовал проект с использованием VS 2010. И теперь готов поделиться своими впечатлениями от новых возможностей.
Статья рассчитана на искушенных разработчиков )
Все полученные теоретические знания, на мой взгляд должны быть выражены в практическом опыте. Поэтому как только представилась возможность, я реализовал проект с использованием VS 2010. И теперь готов поделиться своими впечатлениями от новых возможностей.
Статья рассчитана на искушенных разработчиков )
XSD — умный XML
3 мин
XSD — это язык описания структуры XML документа. Его также называют XML Schema. При использовании XML Schema XML парсер может проверить не только правильность синтаксиса XML документа, но также его структуру, модель содержания и типы данных.
Такой подход позволяет объектно-ориентированным языкам программирования легко создавать объекты в памяти, что, несомненно, удобнее, чем разбирать XML как обычный текстовый файл.
Кроме того, XSD расширяем, и позволяет подключать уже готовые словари для описания типовых задач, например веб-сервисов, таких как SOAP.
Стоит также упомянуть о том, что в XSD есть встроенные средства документирования, что позволяет создавать самодостаточные документы, не требующие дополнительного описания.
Рассмотрим в качестве примера XSD документ, описывающий часть структуры аккаунта на хабре.
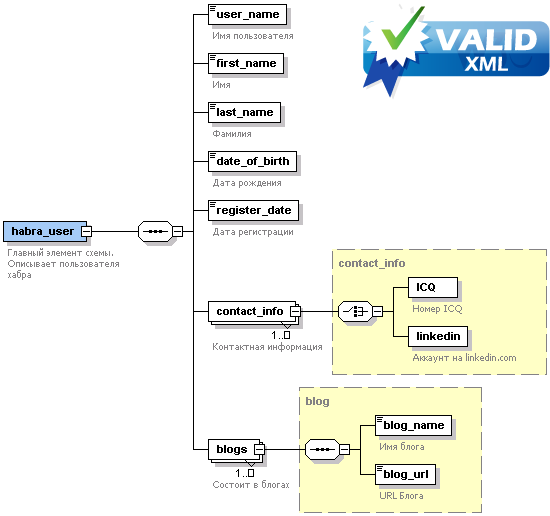
Такой подход позволяет объектно-ориентированным языкам программирования легко создавать объекты в памяти, что, несомненно, удобнее, чем разбирать XML как обычный текстовый файл.
Кроме того, XSD расширяем, и позволяет подключать уже готовые словари для описания типовых задач, например веб-сервисов, таких как SOAP.
Стоит также упомянуть о том, что в XSD есть встроенные средства документирования, что позволяет создавать самодостаточные документы, не требующие дополнительного описания.
Рассмотрим в качестве примера XSD документ, описывающий часть структуры аккаунта на хабре.
Защищаем SSH от брутфорса на любом порту
3 мин
Сегодня меня заинтересовал опрос надо ли перевешивать SSH на нестандартный порт. Сам опрос не так интересен как способ автора zivot_je_cudo защищать SSH от подбора пароля: после неверной попытки подключения блокировать новые попытки в течение 20 секунд. Задержка, видимо, выбрана эмпирически, исходя их двух противположных пожеланий: чтобы не заблокировать в случае опечатки себя надолго, и в тоже время усложнить жизнь подбиральщика. Я хочу поделиться своим способом противодействия брут-форсу, который применяю уже несколько лет. Он имеет два преимущества:
— дает мне больше попыток для набора правильного пароля
— но при этом блокирует брутфорсеров «навечно».
Как можно достичь этих двух противоположных целей?
— дает мне больше попыток для набора правильного пароля
— но при этом блокирует брутфорсеров «навечно».
Как можно достичь этих двух противоположных целей?
Как FriendFeed использует MySQL для хранения данных без схемы
7 мин
Перевод
Условия
Мы используем MySQL для хранения любых данных FriendFeed. Наша база данных растёт вместе с числом пользователей. Сейчас у нас более 250 миллионов записей, это записи пользователей (post'ы), комментарии, оценки («likes»)
По мере того как росла база данных, мы время от времени имели дело с проблемами масштабируемости. Мы решали проблемы стандартными путями: slave-сервера, используемые только для чтения, memcache для увеличения пропускной способности чтения и секционирование для увеличения пропускной способности записи. Однако, по мере роста, использованные методы масштабируемости привели к затруднению добавлению новой функциональности.
В частности, изменение схемы базы данных или добавление индексов к существующим 10-20 миллионов записей приводили к полной блокировке сервера на несколько часов. Удаление старых индексов требовало времени, а не удаление ударяло по производительности, так как база данных продолжала использовать их на каждом INSERT. Существуют сложные процедуры с помощью которых можно обойти эти проблемы (например создание нового индекса на slave-сервере, и последующий обмен местами master'a и slave), однако эти процедуры настолько тяжелые и опасные, что они окончательно лишили нас желания добавлять что-то новое, требующее изменение схемы или индекса. А так как наши базы сильно распределены, реляционные вещи MySQL как например JOIN никогда не работали для нас. Тогда мы решили поискать решение проблем, лежащее вне реляционных баз данных.
Существует множество проектов, призванных решить проблему хранения данных с гибкой схемой и построением индексов на лету (например CouchDB). Однако, по-видимому ни один из них не используется крупными сайтами. В тестах о которых мы читали и прогоняли сами, ни один из проектов не показал себя стабильным, достаточно зрелым для наших целей (см. this somewhat outdated article on CouchDB, например). А все это время MySQL работал. Он не портил данные. Репликация работала. Мы уже в достаточной мере понимали все его узкие места. Нам нравился MySQL именно как хранилище, вне реляционных шаблонов.
Все взвесив, мы решили создать систему хранения данных без схемы поверх MySQL, вместо использования полностью нового решения. В этой статье я попытаюсь описать основные детали системы. Так же нам любопытно как другие сайты решили эти проблемы. Ну и мы думаем, что наша работа будет полезна другим разработчикам.
Биометрическая идентификация: о надежности технологии
4 мин
Бытует мнение, что биометрическая идентификация — это очень надежная и безопасная штука. Я не первый год работаю в этой области, и предлагаю разобраться в этом вопросе подробнее на примере идентификации человека по отпечатку пальца.
Что же она из себя представляет? Взгляните на свой палец. Вы видите множество линий, которые то сходятся, то расходятся. Вот по точкам этих самых схождений-расхождений строится так называемая «биометрическая модель». Она у всех разная и дактилоскописты могут практически безошибочно подтвердить или опровергнуть причастность того или иного человека к отпечатку. Но, во-первых, дактилоскописты берут полную прокатную модель пальца; во-вторых, с учетом всех линий, рисунка, и прочего. Мы же можем руководствоваться только отсканированной частью отпечатка. В которую входит определенное количество точек («основные»), но далеко не все.
Что же она из себя представляет? Взгляните на свой палец. Вы видите множество линий, которые то сходятся, то расходятся. Вот по точкам этих самых схождений-расхождений строится так называемая «биометрическая модель». Она у всех разная и дактилоскописты могут практически безошибочно подтвердить или опровергнуть причастность того или иного человека к отпечатку. Но, во-первых, дактилоскописты берут полную прокатную модель пальца; во-вторых, с учетом всех линий, рисунка, и прочего. Мы же можем руководствоваться только отсканированной частью отпечатка. В которую входит определенное количество точек («основные»), но далеко не все.
Ограничение доступа в интернет для приложений в Linux
2 мин
Иногда бывает необходимо запустить программу, предварительно заблокировав для неё доступ в интернет. Существует довольно простой трюк для решения этой задачи.
Итак, идея заключается в том, чтобы при запуске приложения устанавливать особый ID группы, который будет сигналом блокировки доступа для netfilter.
Создаём группу (В нашем случае группа будет называться
Добавляем в неё текущего пользователя:
Итак, идея заключается в том, чтобы при запуске приложения устанавливать особый ID группы, который будет сигналом блокировки доступа для netfilter.
Шаг 1. Создаём группу-маркер и добавляем себя в неё
Создаём группу (В нашем случае группа будет называться
noinet):sudo groupadd noinetДобавляем в неё текущего пользователя:
sudo gpasswd -a `id -un` noinetКириллица в именах переменных и функций
2 мин
Здравствуй, сообщество.
Вероятно, то, что я сейчас напишу, кому-то было известно, но буквально недавно с этим столкнулись впервые.
Я сейчас тут код приложу, в принципе, там всё понятно. У меня и моих бывших коллег вчера был культурный шок. Сегодня немного набросал тестового кода, для проверки.
Работает в кодировках cp1251 и в UTF, проверяли на версиях php 4.4.7, 5.2.9, 5.2.10–2ubuntu6.4
Вообщем, вы посмотрите на это и выскажите своё мнение.
Вероятно, то, что я сейчас напишу, кому-то было известно, но буквально недавно с этим столкнулись впервые.
Я сейчас тут код приложу, в принципе, там всё понятно. У меня и моих бывших коллег вчера был культурный шок. Сегодня немного набросал тестового кода, для проверки.
Работает в кодировках cp1251 и в UTF, проверяли на версиях php 4.4.7, 5.2.9, 5.2.10–2ubuntu6.4
Вообщем, вы посмотрите на это и выскажите своё мнение.
WebSockets — полноценный асинхронный веб
7 мин
 Пару недель назад разработчики Google Chromium опубликовали новость о поддержке технологии WebSocket. В айтишном буржунете новость произвела эффект разорвавшейся бомбы. В тот же день различные очень известные айтишники опробовали новинку и оставили восторженные отзывы в своих блогах. Моментально разработчики самых разных серверов/библиотек/фреймворков (в их числе Apache, EventMachine, Twisted, MochiWeb и т.д.) объявили о том, что поддержка ВебСокетов будет реализована в их продуктах в ближайшее время.
Пару недель назад разработчики Google Chromium опубликовали новость о поддержке технологии WebSocket. В айтишном буржунете новость произвела эффект разорвавшейся бомбы. В тот же день различные очень известные айтишники опробовали новинку и оставили восторженные отзывы в своих блогах. Моментально разработчики самых разных серверов/библиотек/фреймворков (в их числе Apache, EventMachine, Twisted, MochiWeb и т.д.) объявили о том, что поддержка ВебСокетов будет реализована в их продуктах в ближайшее время.Что же такого интересного сулит нам технология? На мой взгляд, WebSocket — это самое кардинальное расширение протокола HTTP с его появления. Это не финтифлюшки, это сдвиг парадигмы HTTP. Изначально синхронный протокол, построенный по модели «запрос — ответ», становится полностью асинхронным и симметричным. Теперь уже нет клиента и сервера с фиксированными ролями, а есть два равноправных участника обмена данными. Каждый работает сам по себе, и когда надо отправляет данные другому. Отправил — и пошел дальше, ничего ждать не надо. Вторая сторона ответит, когда захочет — может не сразу, а может и вообще не ответит. Протокол дает полную свободу в обмене данными, вам решать как это использовать.
Я считаю, что веб сокеты придутся ко двору, если вы разрабатываете:
— веб-приложения с интенсивным обменом данными, требовательные к скорости обмена и каналу;
— приложения, следующие стандартам;
— «долгоиграющие» веб-приложения;
— комплексные приложения со множеством различных асинхронных блоков на странице;
— кросс-доменные приложения.
Профилирование PHP-кода
3 мин
Профилирование PHP-кода
Рано или поздно каждый из нас сталкивается с унаследованным кодом и его оптимизацией. Дебаггер и профилировшик в такой ситуации — лучшие помощники программиста. У тех кто работает с PHP, благодаря Дерику Ретансу (Derick Rethans) есть хороший инструмент — xDebug. Информации касательно xDebug много даже в рунете, поэтому речь в этой статье пойдет не о нем.
Наткнувшись на упоминание о профилировщике для PHP я сразу подумал об xDebug ( о проприетарных инструментах от Zend я давно уже успел позабыть ), но на этот раз ошибся — речь пойдет об XHProf.
XHProf
Этот профилировшик был разработан специально для Facebook, а исходный код его был открыт в марте 2009 года.
Рано или поздно каждый из нас сталкивается с унаследованным кодом и его оптимизацией. Дебаггер и профилировшик в такой ситуации — лучшие помощники программиста. У тех кто работает с PHP, благодаря Дерику Ретансу (Derick Rethans) есть хороший инструмент — xDebug. Информации касательно xDebug много даже в рунете, поэтому речь в этой статье пойдет не о нем.
Наткнувшись на упоминание о профилировщике для PHP я сразу подумал об xDebug ( о проприетарных инструментах от Zend я давно уже успел позабыть ), но на этот раз ошибся — речь пойдет об XHProf.
XHProf
Этот профилировшик был разработан специально для Facebook, а исходный код его был открыт в марте 2009 года.
Gource — визуализируем историю работы над проектом
1 мин
Спешу рассказать хабрасообществу о, относительно новом, дьявольски завораживающем проекте Gource которое еще не упоминалось. Это приложение позволяет визуализировать историю изменений в системе контроля версии. Отрисовывает невероятно красиво при помощи OpenGL.
Триграммный индекс или «Поиск с опечатками»
4 мин
Как-то по долгу службы появилась необходимость добавить к поиску на сайте всем известную фичу, сервис «Возможно вы имели в виду…» или «Поиск с опечатками». Стали думать как реализовывать. Сторонние сервисы и api использовать не хотелось, ибо время до чужого сервера и назад, да и в целом не очень хорошо. Как раз кстати пришелся модуль pg_trgm, который ищет близкие к запросу слову на основе триграммного индекса.
Как собрать бинарный deb пакет: подробное HowTo
15 мин
Сегодня я расскажу на абстрактном примере как правильно создать *.deb пакет для Ubuntu/Debian. Пакет мы будем делать бинарный. Пакеты, компилирующие бинарники из исходников здесь не рассматриваются: осилив изложенные ниже знания, в дальнейшем по готовым примерам можно понять суть и действовать по аналогии :)
В статье не будет никакой лишней возни «вручную»: формат пакета эволюционировал в достаточно простую, а главное — логичную структуру, и всё делается буквально на коленке, с применением пары специализированных утилит.
В качестве бонуса в конце статьи будет пример быстрого создания собственного локального репозитория: установка пакетов из репозитория позволяет автоматически отслеживать зависимости, и конечно же! — устанавливать всё одной консольной командой на нескольких машинах :)
Для тех, кто не хочет вдаваться в мощную систему установки софта в Linux, рекомендую посетить сайт проги CheckInstall: она автоматически создаёт deb-пакет из команды «make install» ;) А мы вместе с любопытными —
В статье не будет никакой лишней возни «вручную»: формат пакета эволюционировал в достаточно простую, а главное — логичную структуру, и всё делается буквально на коленке, с применением пары специализированных утилит.
В качестве бонуса в конце статьи будет пример быстрого создания собственного локального репозитория: установка пакетов из репозитория позволяет автоматически отслеживать зависимости, и конечно же! — устанавливать всё одной консольной командой на нескольких машинах :)
Для тех, кто не хочет вдаваться в мощную систему установки софта в Linux, рекомендую посетить сайт проги CheckInstall: она автоматически создаёт deb-пакет из команды «make install» ;) А мы вместе с любопытными —