
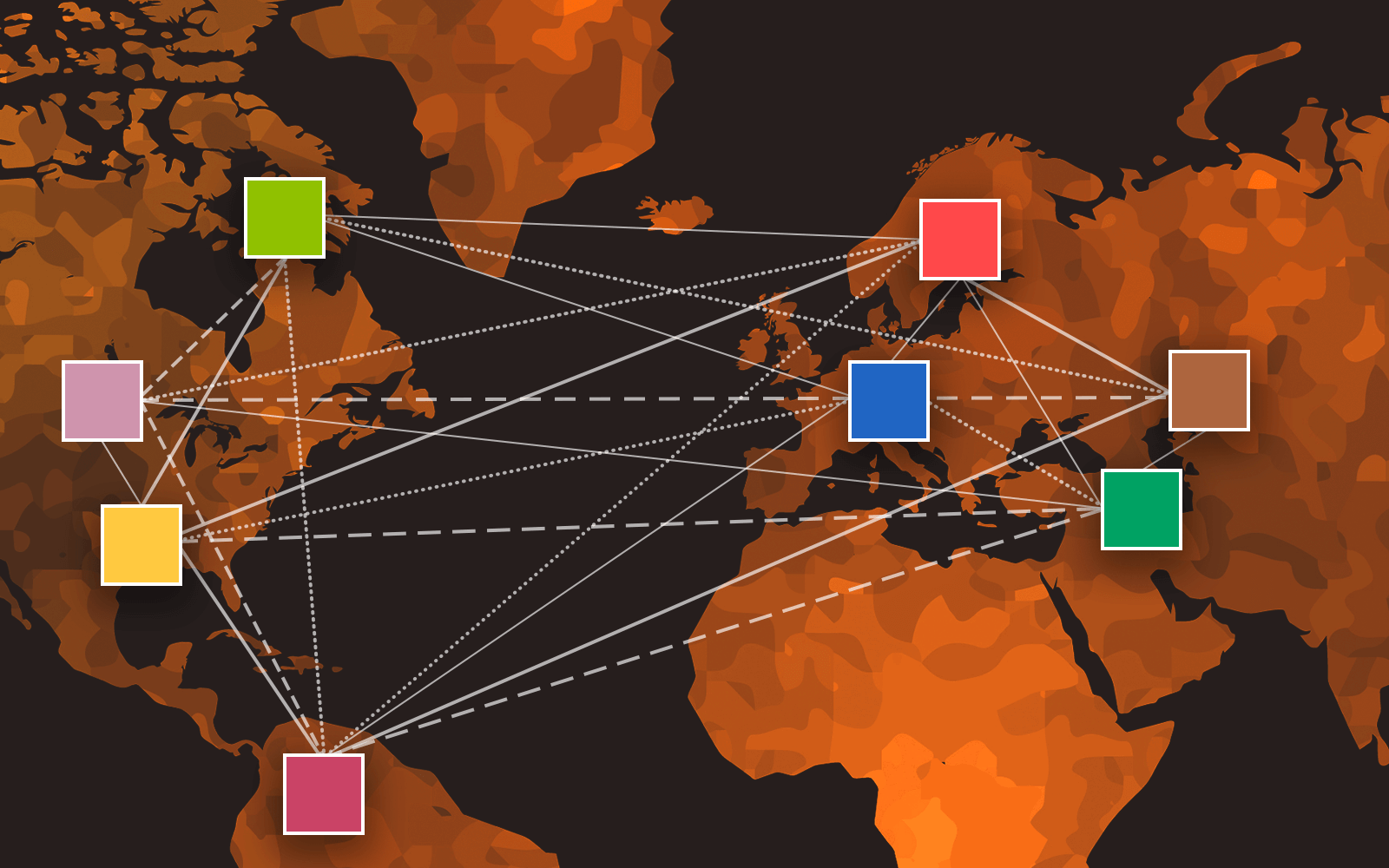
Как показывает опыт последних лет, самые интересные результаты в deep learning получаются при использовании больших нейросетей, обученных на массивах неразмеченных данных. Правда, для создания этих моделей нужен суперкомпьютер с десятками или сотнями мощных видеокарт, а также быстрым соединением между серверами. Но что делать, если таких ресурсов нет, а в открытом доступе хорошей модели под вашу задачу не нашлось?
Сегодня я расскажу про технологию, которая позволяет учить нейросети, объединяя через интернет вычислительные мощности энтузиастов из любой точки мира. В её основе лежит совместная научная работа Yandex Research, Hugging Face, студентов ШАД, ВШЭ и МФТИ, а также профессора Университета Торонто. Технология уже получила боевое крещение в ходе реального эксперимента, подробно описанного ниже. В конце статьи вы узнаете, как поставить такой эксперимент самостоятельно — модель и код доступны всем желающим.
Претрейн для всех, и пусть никто не уйдёт обиженным
За последние несколько лет во многих областях deep learning (например, в обработке естественного языка) стала популярной идея self-supervised learning. Оказалось, что для получения полезных в целевой задаче представлений не нужна большая размеченная выборка. Достаточно обучить модель на какой-то простой сигнал, построенный из неразмеченных данных, которых чаще всего в достатке. В частности, известные многим архитектуры BERT, GPT и языковая модель YaLM обучаются именно так.


 Не знаю, все ли программисты всесторонне любознательные люди, но я всегда пытаюсь получить фундаментальные знания во всех областях, которые могут быть практически полезны. В то время, когда мне в голову пришла эта идея я изучал анатомию и физиологию по журналам «Тело человека. Снаружи и внутри», ну а по работе я занимался стерео-варио фотографиями (для тех кто не знает — были такие советские календарики с ребристой поверхностью, где картинка либо казалась объемной, либо менялась). Так вот, в один из вечеров мне пришла в голову замечательная идея, которую я на протяжении уже 4х лет использую для поддержания своего зрения.
Не знаю, все ли программисты всесторонне любознательные люди, но я всегда пытаюсь получить фундаментальные знания во всех областях, которые могут быть практически полезны. В то время, когда мне в голову пришла эта идея я изучал анатомию и физиологию по журналам «Тело человека. Снаружи и внутри», ну а по работе я занимался стерео-варио фотографиями (для тех кто не знает — были такие советские календарики с ребристой поверхностью, где картинка либо казалась объемной, либо менялась). Так вот, в один из вечеров мне пришла в голову замечательная идея, которую я на протяжении уже 4х лет использую для поддержания своего зрения.

 Занявшись делами вне отрасли ИТ, я вдруг обнаружил, что делаю всё по-айтишному и неэффективно. Чуть позже я поговорил с другом, который руководит айтишниками, и с позиции мудрости должен бы принять лучшие решения, но, несмотря на опыт больший, чем мой, он с порога предложил делать то же самое, и, будучи руководителем, только активнее отстаивал эти идеи.
Занявшись делами вне отрасли ИТ, я вдруг обнаружил, что делаю всё по-айтишному и неэффективно. Чуть позже я поговорил с другом, который руководит айтишниками, и с позиции мудрости должен бы принять лучшие решения, но, несмотря на опыт больший, чем мой, он с порога предложил делать то же самое, и, будучи руководителем, только активнее отстаивал эти идеи.
 Многие пытаются собрать «Умный дом» своими руками. При выборе системы стоит учитывать не только ассортимент и стоимость конечных устройств, но и возможности контроллера. Большинство контроллеров сразу готовы к работе «из коробки», но представляют ограниченные возможности. Однако нередко именно гибкость и возможность лёгкой интеграции является основополагающим критерием при выборе.
Многие пытаются собрать «Умный дом» своими руками. При выборе системы стоит учитывать не только ассортимент и стоимость конечных устройств, но и возможности контроллера. Большинство контроллеров сразу готовы к работе «из коробки», но представляют ограниченные возможности. Однако нередко именно гибкость и возможность лёгкой интеграции является основополагающим критерием при выборе.

