Привет! Меня зовут Никита Учителев. Я представляю отдел Research & Development компании Lamoda. Нас 20+ человек, и мы работаем над различными рекомендациями на сайте и в приложениях, разрабатываем поиск, определяем сортировку товаров в каталогах, обеспечиваем возможность АБ-тестирования разнообразного функционала, а также поддерживаем несколько внутренних разработок вроде системы прогнозирования эластичности спроса и оптимизации логистики доставки.
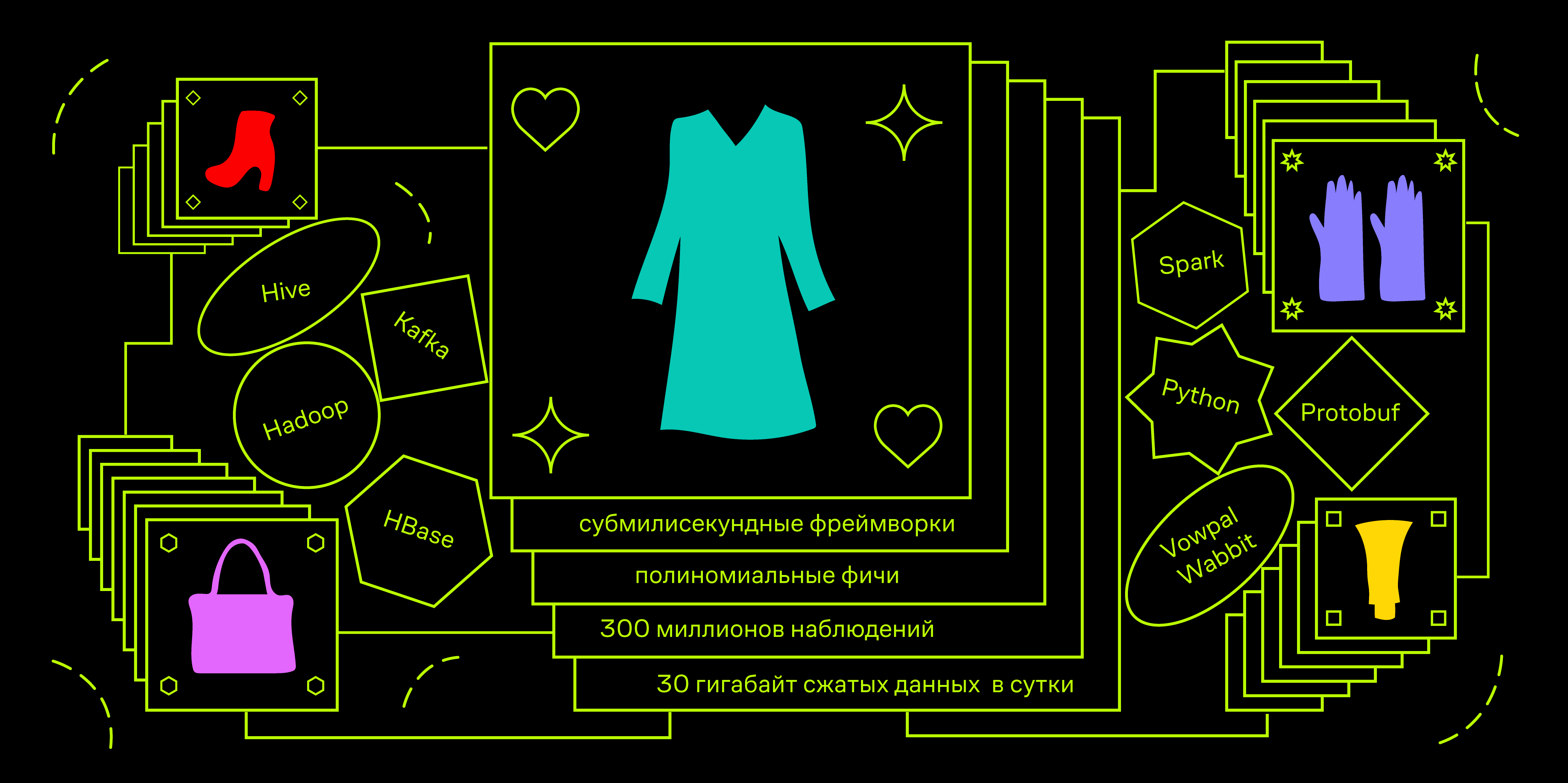
Одним из основных направлений развития всей компании на ближайшие годы выбрана персонализация наших продуктов и услуг. Подобные инициативы тестируются и внедряются повсеместно — начиная от составления персональных подборок товаров до выбора конкретного торгового представителя, который доставит наш товар именно вам. В рамках процесса персонализации продуктов R&D я выступаю в роли тимлида и хочу в этой статье рассказать про платформу, проектированием и разработкой которой я со своей командой занимался последний год, а также про первые персонализированные продукты R&D, которые проходят АБ-тестирование в настоящее время.