В этой статье я расскажу о долгом путешествии, в котором простая идея выноса в JavaScript часто меняющихся фрагментов алгоритма постепенно выросла в универсальный фреймворк, позволяющий быстро создавать микросервисы и так же быстро их развивать. Сейчас он служит основой для множества микросервисов в Яндекс Go. Тут не будет много специфики Go. Вместо этого будет много разработки и решений технических задач (а не продуктовых). Ещё я, конечно, расскажу про возникшие в процессе трудности: если вам, например, интересно, как V8 уживается с корутинами или как мы оптимизировали работу с ним для производительности, то добро пожаловать под кат.
Всем привет! Меня зовут Александр, я руковожу отделом Data Team в Badoo. Сегодня я расскажу вам о том, как мы выбирали оптимальный алгоритм для вычисления квантилей в нашей распределённой системе обработки событий.
В последние пару лет я занимаюсь построением различных планировщиков, и мне пришло в голову поделиться своим нелёгким опытом с коллегами. Речь идёт о двух категориях коллег. Первые — это желающие узнать, как разработать свой scheduler за 21 день. Вторые — те, кому нужен новый scheduler совсем без смс и регистрации, просто чтобы работал. Особенно хотелось бы помочь второй категории людей.
Сначала, как водится, стоит сказать несколько общих слов. Что такое scheduler (планировщик, или, для простоты, «шедулер»)? Это такая компонента системы, которая занимается распределением ресурса или ресурсов системы по потребителям. Разделение ресурса может происходить в двух измерениях: в пространстве и времени. Планировщики чаще всего фокусируются на втором измерении. Обычно под ресурсом подразумевают процессор, диск, память и сеть. Но, что греха таить, шедулить можно и любую виртуальную ерунду. Конец общих слов.
Написать сетевой сервис на Go очень просто: в стандартной библиотеке есть куча инструментов, а если чего-то и не хватает, то на Github есть много модных библиотек для удовлетворения большинства нужд.
Но что, если необходимо написать с десяток разных сервисов, работающих в одной инфраструктуре?
Если каждый демон будет использовать все свежие разнообразные «смузи»-технологии, получится «зоопарк», который сложно и дорого поддерживать, не говоря уже о добавлении в них новой функциональности.
У нас в Badoo крутятся >30 самописных демонов, написанных на разных языках, и ~10 из них – на Go. Все эти демоны работают на порядка 300 серверах. Как мы к этому пришли, не получив в итоге «зоопарк», как админы с мониторингом умудряются спать спокойно, не ограничивая при этом никого в смузи, а девелоперы, QA и релизеры живут дружно и до сих пор не переругались – читайте под катом.
В одном из прежних постов я рассказывал, как реализовать «простейшую в мире lock-free хеш-таблицу» на C++. Она была настолько проста, что было невозможно удалять из нее записи или менять ее размерность. С тех пор прошло несколько лет, и не так давно я написал несколько многопоточных ассоциативных массивов без таких ограничений. Их можно найти в моем проекте Junction на GitHub.
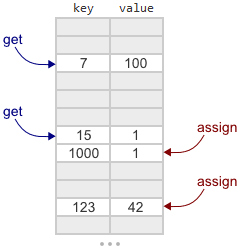
Junction содержит несколько многопоточных реализаций интерфейса map – даже «самая простая в мире» среди них, под названием ConcurrentMap_Crude. Для краткости будем называть ее Crude map. В этом посте я объясню разницу между Crude map и Linear map из библиотеки Junction. Linear — самый простой map в Junction, поддерживающий и изменение размера, и удаление.
Можете ознакомиться с объяснением того, как работает Crude map, в первоначальном посте. Если коротко, то она основана на открытой адресации и линейном пробировании. Это значит, что она по сути является большим массивом ключей и значений, использующим линейный поиск. Во время добавления или поиска заданного ключа мы вычисляем хеш от ключа, чтобы определить, с какого места начать поиск. Добавление и поиск данных возможны в многопоточном режиме.
Привет. Меня зовут Марко, и я системный программист в Badoo. Я очень люблю досконально разбираться в том, как работают те или иные вещи, и тонкости работы разделяемых библиотек в Linux не исключение. Я представляю вам перевод именно такого разбора. Приятного чтения.
Как, наверняка, многие знают, в WinAPI'шную функцию Sleep передаётся число миллисекунд, на сколько мы хотим уснуть. Поэтому минимум, что мы можем запросить — это уснуть на 1 миллисекунду. Но что если мы хотим спать ещё меньше? Для интересующихся, как это сделать в картинках, добро пожаловать, под кат.
Эта статья — частичный перевод исчерпывающего руководства Дэвида Хоуэлса (David Howells) и Пола Маккени (Paul E. McKenney) распространяемого в составе документации Linux (Documentation/memory-barriers.txt онлайн версия).
Must read для разработчиков ядра/драйверов и очень познавательно для прикладных программистов.
Если программист хорошо знаком только с высокоуровневыми языками, например PHP, то ему не так просто освоить некоторые идеи, свойственные низкоуровневым языкам и критичные для понимания возможностей информационно-вычислительных процессов. По большей части причина в том, что в низко- и высокоуровневых языках мы решаем разные проблемы.
Но как можно считать себя профессионалом в каком-либо (высокоуровневом) языке, если даже не знаешь, как именно работает процессор, как он выполняет вычисления, эффективным ли способом? Сегодня автоматическое управление памятью становится главной проблемой в большинстве высокоуровневых языков, и многие программисты подходят к её решению без достаточной теоретической базы. Я уверен, что знание низкоуровневых процессов сильно помогает в разработке эффективных высокоуровневых программ.
Глава из книги "Современное программирование на C++" называется "В сто первый раз об интеллектуальных указателях". Все бы ничего, но книга была издана в 2001 году, так стоит ли в очередной раз возвращаться к этой теме? Мне кажется что как раз сейчас и стоит. За эти пятнадцать лет поменялась сама точка зрения, тот угол под которым мы смотрим на проблему. В те далекие времена только-только вышла первая де-факто стандартная реализация — boost::shared_ptr<>, до этого каждый писал себе реализацию по потребности и как минимум представлял себе детали, сильные и слабые стороны своего кода. Все книги по C++ в то время обязательно описывали одну из вариаций умных указателей в мельчайших деталях.
Сейчас нам дан стандарт, и это хорошо. Но с другой стороны, уже не требуется понимать что там внутри, вместо этого достаточно три раза повторить мантру "используйте умные указатели везде где вы бы использовали обычные указатели", и это уже не так хорошо. Я подозреваю что далеко не все отдают себе отчет что данный стандарт — лишь один из возможных вариантов интерфейса, не говоря уже о разнице между реализациями различных вендоров. При выборе стандарта был сделан выбор между различными возможностями учитывающий разные факторы, но, оптимальный или нет, этот выбор очевидно не единственен.
А еще на stackoverflow например снова и снова задается вопрос — "потокобезопасны ли умные указатели из стандартной библиотеки?". Ответы даются обычно категоричные, но какие-то мало информативные. Если бы я например не знал о чем идет речь, то наверное бы не понял. И кстати, все сравнительно новые книги описывающие новый стандарт C++ этому вопросу тоже уделяют мало внимания.
Так давайте же попробуем сорвать покровы и разберемся с деталями.
Юникод — это очень большой и сложный мир, ведь стандарт позволяет ни много ни мало представлять и работать в компьютере со всеми основными письменностями мира. Некоторые системы письма существуют уже более тысячи лет, причём многие из них развивались почти независимо друг от друга в разных уголках мира. Люди так много всего придумали и оно зачастую настолько непохоже друг на друга, что объединить всё это в единый стандарт было крайне непростой и амбициозной задачей.
Чтобы по-настоящему разобраться с Юникодом нужно хотя бы поверхностно представлять себе особенности всех письменностей, с которыми позволяет работать стандарт. Но так ли это нужно каждому разработчику? Мы скажем, что нет. Для использования Юникода в большинстве повседневных задач, достаточно владеть разумным минимумом сведений, а дальше углубляться в стандарт по мере необходимости.
В статье мы расскажем об основных принципах Юникода и осветим те важные практические вопросы, с которыми разработчики непременно столкнутся в своей повседневной работе.
Большинство программистов представляют вычислительную систему как процессор, который выполняет инструкции, и память, которая хранит инструкции и данные для процессора. В этой простой модели память представляется линейным массивом байтов и процессор может обратиться к любому месту в памяти за константное время. Хотя это эффективная модель для большинства ситуаций, она не отражает того, как в действительности работают современные системы.
В действительности система памяти образует иерархию устройств хранения с разными ёмкостями, стоимостью и временем доступа. Регистры процессора хранят наиболее часто используемые данные. Маленькие быстрые кэш-памяти, расположенные близко к процессору, служат буферными зонами, которые хранят маленькую часть данных, расположеных в относительно медленной оперативной памяти. Оперативная память служит буфером для медленных локальных дисков. А локальные диски служат буфером для данных с удалённых машин, связанных сетью.
Иерархия памяти работает, потому что хорошо написанные программы имеют тенденцию обращаться к хранилищу на каком-то конкретном уровне более часто, чем к хранилищу на более низком уровне. Так что хранилище на более низком уровне может быть медленнее, больше и дешевле. В итоге мы получаем большой объём памяти, который имеет стоимость хранилища в самом низу иерархии, но доставляет данные программе со скоростью быстрого хранилища в самом верху иерархии.
Немаловажный пункт, который очень часто упускают из вида разработчики — это эксплуатация проекта. Как выбрать дата-центр? Как прогнозировать угрозы? Что может произойти на уровне фронтенда? Как балансировать фронтенд? Как мониторить? Как настраивать логи? Какие нужны метрики?
И ведь это только фронтенд, а есть ещё бекенд и база данных. Везде разные законы и логика. Подробнее об эксплуатации highload-проектов в докладе Николая Сивко (okmeter.io) с конференции HighLoad++ Junior.
Одна из основных функций десктопного клиента Облака Mail.Ru — синхронизация данных. Ее целью является приведение папки на ПК и ее представления в Облаке к одинаковому состоянию. При разработке этого механизма мы встретились с некоторыми, с первого взгляда, достаточно очевидными особенностями различных файловых и операционных систем. Однако если о них не знать, можно столкнуться с довольно неприятными последствиями (не получится загрузить или удалить файл). В этой статье мы собрали особенности, знание которых позволит вам правильно работать с данными на дисках и, возможно, убережет от необходимости срочного хотфикса.
Как известно, в современных архитектурах x86(_64) и ARM виртуальная память процесса линейна и непрерывна, ибо, к счастью, прошли времена char near* и int huge*. Виртуальная память поделена на страницы, типичный размер которых 4 KiB, и по умолчанию они не отображены на физическую память (mapping), так что работать с ними не получится. Чтобы посмотреть текущие отображённые интервалы адресов у процесса, в Linux смотрим /proc/<pid>/maps, в OS X vmmap <pid>. У каждого интервала адресов есть три вида защиты: от исполнения, от записи и от чтения. Как видно, самый первый интервал, начинающийся с load address (соответствующий сегменту .text у ELF в Linux, __TEXT у Mach-O в OS X), доступен на чтение и исполнение — очень логично. Ещё можно увидеть, что стек по сути ничем не отличается от других интервалов, и можно быстро вычислить его размер, вычтя из конечного адреса начальный. Отображение страниц выполняется с помощью mmap/munmap, а защита меняется с помощью mprotect. Ещё существуют brk/sbrk, deprecated древние пережитки прошлого, которые изменяют размер одного-единственного интервала «данных» и в современных системах эмулируются mmap’ом.
Все POSIX-реализации malloc так или иначе упираются в перечисленные выше функции. По сравнению с наивным выделением и освобождением страниц, округляя необходимый размер в большую сторону, malloc имеет много преимуществ:
оптимально управляет уже выделенной памятью;
значительно уменьшает количество обращений к ядру (ведь mmap / sbrk — это syscall);
вообще абстрагирует программиста от виртуальной памяти, так что многие пользуются malloc’ом, вообще не подозревая о существовании страниц, таблиц трансляции и т. п.
Довольно теории! Будем щупать malloc на практике. Проведём три эксперимента. Работа будет возможна на POSIX-совместимых операционках, в частности была проверена работа на Linux и на OS X.
Обычно в таких статьях делают заголовок вида «аналог await/async для C++», а их содержимое сводится к описанию ещё одной библиотеки, выложенной где-то в интернете. Но в данном случае нам не требуется ничего подобного и заголовок точно отражает суть статьи. Почему так смотрите ниже.
Однажды появилась необходимость собрать все уроки, обучающие материалы (tutorials) с habrahabr и geektimes в одном месте и немного их систематизировать. В этом сборнике обучаек представлены более 100 статей на тему ардуино с пометкой «tutorial», либо содержащие несложные для новичков проекты на ардуино, а также немного видеоуроков по смежным темам. Статьи разделены на 10 тематик по сферам применения собранных устройств. Также хочется напомнить, что весь обучающий материал, опубликованный на habrahabr и geektimes является интерактивным: в любой момент можно задать вопрос автору в комментариях к статье. Как правило авторы на них отвечают. Этот сборник будет дополняться новыми обучайками (tutorials) по мере их публикации.
Эту статью я написал достаточно давно для своего блога, который теперь заброшен. Мне кажется, в ней есть весьма полезная информация, поэтому не хотелось бы, чтобы она просто исчезла. Очень может быть, что-то уже устарело, буду благодарен, если мне на это укажут.
Как правило, язык C++ используют там, где требуется высокая скорость работы. Но на C++ без особых усилий можно получить код, работающий медленнее какого-нибудь Python/Ruby. Именно подобным кодом оперируют многочисленные сравнения Any-Lang vs C++.
Вообще, оптимизация бывает трех типов:
Оптимизация уже готового, проверенного и работающего кода.
Изначально написание оптимального кода.
Просто использование оптимальных конструкций.
Специально заниматься оптимизацией готового кода следует только после того, как проект закончен и используется. Как правило, оптимизация потребуется только в небольшой части проекта. Поэтому сначала нужно найти места в коде, которые съедают большую часть процессорного времени. Ведь какой смысл ускорять код, пусть даже на 500%, если он отнимает только 1% машинного времени? И следует помнить, что, как правило, гораздо больший выигрыш в скорости дает оптимизация самих алгоритмов, а не кода. Именно про данный ее вид говорят: «преждевременная оптимизация — зло» (с).
Второй тип оптимизации — это изначальное проектирование кода с учетом требований к производительности. Такое проектирование не является ранней оптимизацией.
Третий тип даже не совсем оптимизация. Скорее это избегание неоптимальных языковых конструкций. Язык C++ довольно сложный, при его использовании частенько нужно знать, как реализован используемый код. Он достаточно низкоуровневый, чтобы программисту пришлось учитывать особенности работы процессоров и операционных систем.
Когда я делаю ошибку в коде, то обычно это приводит к появлению сообщения “segmentation fault”, зачастую сокращённого до “segfault”. И тут же мои коллеги и руководство приходят ко мне: «Ха! У нас тут для тебя есть segfault для исправления!» — «Ну да, виноват», — обычно отвечаю я. Но многие ли из вас знают, что на самом деле означает ошибка “segmentation fault”?
Чтобы ответить на этот вопрос, нам нужно вернуться в далёкие 1960-е. Я хочу объяснить, как работает компьютер, а точнее — как в современных компьютерах осуществляется доступ к памяти. Это поможет понять, откуда же берётся это странное сообщение об ошибке.
Вся представленная ниже информация — основы компьютерной архитектуры. И без нужды я не буду сильно углубляться в эту область. Также я буду применять всем известную терминологию, так что мой пост будет понятен всем, кто не совсем на «вы» с вычислительной техникой. Если же вы захотите изучить вопрос работы с памятью подробнее, то можете обратиться к многочисленной доступной литературе. А заодно не забудьте покопаться в исходном коде ядра какой-нибудь ОС, например, Linux. Я не буду излагать здесь историю вычислительной техники, некоторые вещи не будут освещаться, а некоторые сильно упрощены.
Конференции бывают разные. Некоторые собирают огромные толпы зрителей, другие могут быть интересны лишь полутора специалистам.
Забавно другое: часто бывает, что зал собирает большое количество слушателей, которым любопытна тема, они задают вопросы и впоследствии с энтузиазмом рассказывают о пережитом коллегам. В то же время, запись оного мероприятия собирает несоизмеримо меньше просмотров, чем котики на ютубе. Предполагаю, что видео банально теряются на просторах видеохостингов и не могут найти зрителей. Сей досадный факт обязательно надо исправлять!
На самом деле, пост не о том.
Так уж вышло, что мне довелось выступать на означенной конференции, где я на пальцах и с приплясываниями рассказывал, что такое LLVM, чем интересна нотация SSA, что такое IR код и, наконец, как так получается, что детерменированные на первый взгляд C++ программы, оказывается, провоцируют неопределенное поведение.
Кстати, этот доклад можно поставить пятым номером в серии статей про виртуальную машину Smalltalk. Многие просили подробнее рассказать о LLVM. В общем, убиваем всех зайцев сразу. Заинтересовавшимся, предлагаю «откинуться на спинку кресла», опционально налить чего-нибудь интересного и послушать. Обещаю, что больше часа времени я не отниму.
Ах да, под катом можно найти пояснения тех моментов, которым не было уделено должное внимание на конференции. Я постарался ответить на часто задаваемые вопросы и детально разобрать листинги LLVM IR. В принципе, текстовую часть статьи можно читать как самостоятельное произведение, тем не мене я рассчитывал на то, что читатель обратится к нему уже после просмотра видео.







 Глава из книги "Современное программирование на C++" называется "В сто первый раз об интеллектуальных указателях". Все бы ничего, но книга была издана в 2001 году, так стоит ли в очередной раз возвращаться к этой теме? Мне кажется что как раз сейчас и стоит. За эти пятнадцать лет поменялась сама точка зрения, тот угол под которым мы смотрим на проблему. В те далекие времена только-только вышла первая де-факто стандартная реализация — boost::shared_ptr<>, до этого каждый писал себе реализацию по потребности и как минимум представлял себе детали, сильные и слабые стороны своего кода. Все книги по C++ в то время обязательно описывали одну из вариаций умных указателей в мельчайших деталях.
Глава из книги "Современное программирование на C++" называется "В сто первый раз об интеллектуальных указателях". Все бы ничего, но книга была издана в 2001 году, так стоит ли в очередной раз возвращаться к этой теме? Мне кажется что как раз сейчас и стоит. За эти пятнадцать лет поменялась сама точка зрения, тот угол под которым мы смотрим на проблему. В те далекие времена только-только вышла первая де-факто стандартная реализация — boost::shared_ptr<>, до этого каждый писал себе реализацию по потребности и как минимум представлял себе детали, сильные и слабые стороны своего кода. Все книги по C++ в то время обязательно описывали одну из вариаций умных указателей в мельчайших деталях.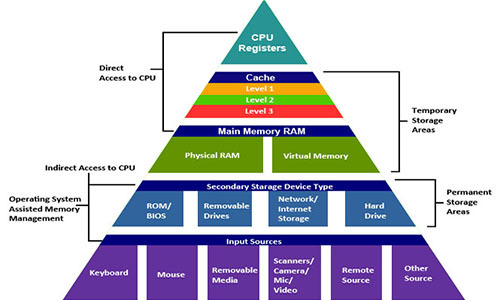






 Конференции бывают разные. Некоторые собирают огромные толпы зрителей, другие могут быть интересны лишь полутора специалистам.
Конференции бывают разные. Некоторые собирают огромные толпы зрителей, другие могут быть интересны лишь полутора специалистам.