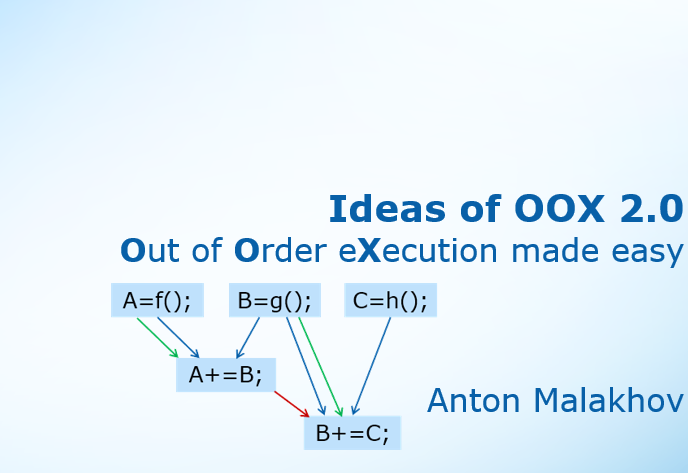
 Since 2011 all Intel GPUs (integrated and discrete Intel Graphics products) include Intel Quick Sync Video (QSV) — the dedicated hardware core for video encoding and decoding. Intel QSV is supported by all popular video processing applications across multiple OSes including FFmpeg. The tutorial focuses on Intel QSV based video encoding and decoding acceleration in Windows native (desktop) applications using FFmpeg/libavcodec for video processing. To illustrate concepts described, the open source 3D Streaming Toolkit is used.
Since 2011 all Intel GPUs (integrated and discrete Intel Graphics products) include Intel Quick Sync Video (QSV) — the dedicated hardware core for video encoding and decoding. Intel QSV is supported by all popular video processing applications across multiple OSes including FFmpeg. The tutorial focuses on Intel QSV based video encoding and decoding acceleration in Windows native (desktop) applications using FFmpeg/libavcodec for video processing. To illustrate concepts described, the open source 3D Streaming Toolkit is used.Access the power of hardware accelerated video codecs in your Windows applications via FFmpeg / libavcodec
8 min
Tutorial
Since 2011 all Intel GPUs (integrated and discrete Intel Graphics products) include Intel Quick Sync Video (QSV) — the dedicated hardware core for video encoding and decoding. Intel QSV is supported by all popular video processing applications across multiple OSes including FFmpeg. The tutorial focuses on Intel QSV based video encoding and decoding acceleration in Windows native (desktop) applications using FFmpeg/libavcodec for video processing. To illustrate concepts described, the open source 3D Streaming Toolkit is used.