
Александр (alexbel) Белокрылов и Леша Войтылов, совместно с Григорием Лабзовским, который руководил центром разработки Oracle в Санкт-Петербурге, чуть более года назад основали компанию BellSoft. Сейчас компания успешно работает, развивается и уже успела получить известность в Java-мире.
По объему коммитов в OpenJDK за прошлый год они вышли на пятое место, и теперь впереди только Oracle, Red Hat, SAP и Google:
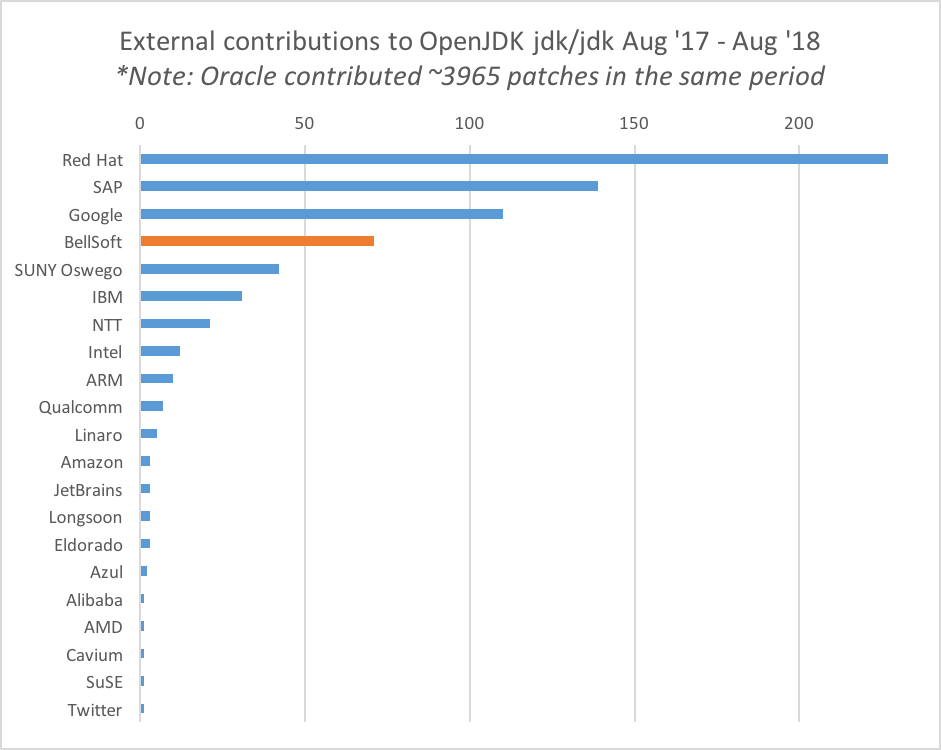
Надо понимать, что BellSoft — это не только Arm:
- Вышла Liberica JDK 11, поддерживаются Linux x86_64, Windows, Linux ARMv8, Linux ARMv7 (включая Raspberry Pi). Будут выкладываться сборки для Mac и Solaris Sparc.
- Публикуются образы под все архитектуры на Docker Hub для Debian, CentOS, Alpine. Образ для Alpine делается из lite версии с
--compress 2поэтому существенно меньше обычного JDK.
В этом интервью мы коснемся только Arm, а всё остальное оставим на следующий раз.
Итак, сегодня у нас в виртуальной студии:
 Александр Белокрылов
Александр Белокрылов
 Леша Войтылов
Леша Войтылов
 Олег Чирухин — редакция JUG.ru Group
Олег Чирухин — редакция JUG.ru Group
Расскажите о компании подробнее?
Компания BellSoft занимается несколькими направлениями. Все, наверное знают, что компания Oracle в Санкт-Петербурге обладала очень серьезной низкоуровневой экспертизой в разработке Java Runtime, в разработке компиляторов, в разработке систем Cloud-сервисов Oracle. И эта экспертиза из Oracle перекочевала в компанию BellSoft. Сегодня наша компания занимается разработкой Java Runtime, мы активный OpenJDK contributor, занимаемся разработкой компиляторов gcc и llvm, контрибьютим в стек Apache, Graal. Занимаемся построением систем анализа больших данных, рекомендательных систем и построили небольшой проект по IoT, по сбору данных с устройств из реального мира. В какой-то момент мы увидели, что Oracle перестал выпускать дистрибутив Java для Arm-платформ, и мы выпустили свой дистрибутив, который назвали Liberica JDK для Raspberry Pi. С тех пор успешно его поддерживаем.
Давай разберем подробней. Что такое, например, стек Apache?
Мы начали контрибьютить в Apache Foundation с Hadoop — на определенные части этого проекта многое завязано. OpenJDK и большие Apache проекты, пусть и не напрямую, но сильно взаимосвязаны.
Зачем всё это может быть нужно? Например, какие-то классы, которые тормозят их, их можно разогнать?
Да, это одно из направлений, которыми мы занимаемся — улучшение производительности. Например, платформенно-специфичные части, ускорение которых в OpenJDK может помочь ускорить Hadoop. Если интересно, можем поговорить об этом.
Когда ты решаешь проблемы с перформансом, имеет смысл посмотреть что-то близкое. Может быть, где-то есть такая же проблема. Очень часто видишь, что поправив в одном месте, нужно поправить еще в паре мест, чтобы в общем стало лучше. Иногда (и очень часто) оптимизации производительности раскладывается на contributions в несколько проектов. Если хочется улучшить, например, производительность checksum, вы посмотрите в самый низ стека. Допустим, это Java. Если посмотреть чуть выше, это будет Hadoop, Spark или что-то еще. Обычно поняв, как улучшить одно место, можно понять, как сделать и в другом месте. Разумеется, имеет смысл в таком случае пойти и улучшить там тоже.
Все знают, что вы — Liberica :-) Давайте поговорим вот об этом.
Да, мы — Liberica JDK. Liberica начиналась с того, что мы увидели, что нет порта для ARM32, и его срочно нужно сделать, потому что Raspberry Pi осталась без Java 9 и Java 10. Это было в 2017 году, когда вышла Java 9. Теперь Liberica JDK поддерживает много архитектур и операционных систем.
Стало понятно, что Oracle не собирается дальше развивать код для Arm, и мы стали активно контрибьютить и выпускать свой дистрибутив, чтобы закрыть эту брешь. Стало понятно, что людям это нужно.
Получается, сейчас есть несколько дистрибутивов Arm?
Да, есть несколько дистрибутивов Java для Arm, они отличаются. В нашем вы получаете фактически то, что раньше было частью дистрибутива порта Oracle. В нашем дистрибутиве присутствует JavaFX, device input/output и API для эмбеддеда. Это некий пакет, и все это работает с модулями, начиная с JDK 9. Используя модульную систему, вы можете собрать Runtime, как вы хотите. Если хотите, можете сделать маленький Runtime размером 16 мегабайт. Если хотите включить больше фич, например, web-сервер, тогда нужно потратить примерно 32 мегабайта статического места. Можете получить работающий Runtime под ваши нужды.
Насколько понял, речь пошла об армовых серверах. Не сказать, чтобы ими у нас пользовались массово. Расскажи про сервера? В реальной жизни они есть вообще?
Этой истории уже много лет. Самый первый Arm-сервер был сделан на основе архитектуры ARMv7, 32-битной. Это была жутко шумящая коробка, которая практически не работала, потому что там не работал BIOS, Linux, все что угодно через несколько часов отпадало. Та компания, которая это начинала, Calxeda, со временем закрылась. Но идея развития альтернативной архитектуры для серверов была посеяна в общество. Arm со временем выпустил новую спецификацию архитектуры ARMv8, которая поддерживает как 32, так и 64 бит. На основе 64-битной версии этой спецификации сейчас несколько производителей строят свои реализации процессоров для серверов. Например, Ampere Computing, Cavium, который нынче куплен компанией Marvell, и еще Qualcomm. И есть еще одна компания — AMD несколько лет назад выпускал тоже сервера на основе Arm-архитектуры. По-моему, до сих пор продолжают это делать.
Если убрать из Marvell одну букву L, получатся супергерои. Хороший способ запомнить названия всех этих контор.
Супергерои там на самом деле Cavium/Marvell, потому что из всех именно им удалось собрать наиболее производительный чип вплоть до 128 тредов на одном CPU, и сравнимый или лучший по производительности с Xeon Gold и Platinum. Можно ставить несколько CPU в один сервер, у вас получается монструозная штука с быстрой памятью, которую можно применять для серьезных задач.
Как растет предел масштабирования для обычного применения? Сколько CPU имеет смысл втыкать в один сервер?
Все зависит от того, для какой задачи вы хотите построить сервер. Разные производители ориентируются на разные ниши, но если мы говорим про Cavium/Marvell, они четко ориентируются на нишу компьютинга, где нужно достаточно быстро прожевать большой объем данных в параллель. Они не ориентируются на супер большую производительность одной нитки (вместе с тем, она очень неплоха), а именно, чтобы в целом данный CPU показывал большую производительность при низком потреблении стоимости.
А почему Arm, а не Intel? Есть у нас замечательные интеловские сервера, зачем придумывать что-то еще?
На этот вопрос и сложно, и просто ответить. Во-первых, свято место пусто не бывает. Мы видим, что и AMD пытается построить какую-то альтернативу Intel для серверных применений. И понятное дело, всегда будет какой-то альтернативный кусок рынка у альтернативных производителей.
Никто не хочет жить с одним монополистом.
Очень верное замечание. Все потребители процессоров, а это в в основном, Cloud-провайдеры, хотят иметь возможность альтернативы. Чтобы можно было выбирать, сравнивать стоимость с затратами и под конкретные применения выбирать более выгодную архитектуру.
А что по затратам? Насколько это дороже, чем решения от Intel?
Сложный вопрос. Во-первых, как Алексей сказал, производителей — достаточно. Понятно, что сейчас производители Arm-процессоров не конкурируют друг с другом, а конкурируют с кем-то другим. Занимают немного разные ниши. Если Cavium — это high performance computing, то Qualcomm — mid-range servers, Ampere — это либо workstations, либо low-end servers.
Если правильно помню, цена самого CPU от Ampere Computing — 600-900 долларов, и они конкурируют с Intel, CPU стоимостью около 1500 долларов. Cavium чуть дороже. Опять же, они будут конкурировать с Intel, который существенно дороже. Нужно понимать, что цена сервера складывается не только из цены CPU. Цена сервера — это еще память, диски, поддержка, потребление. Если вы выигрываете по одному параметру, например, стоимости CPU — это прекрасно, но вы будете лишь чуть-чуть дешевле. Если выигрываете по двум параметрам, например, будучи дешевле, предлагать еще и лучшую производительность, на вас будут смотреть уже более пристально. А если по трем, например, еще и делать все это при меньшем потреблении электроэнергии, то это уже заявка на победу.
Кроме железа и его поддержки еще важна поддержка в софте. Нельзя на Arm запустить всё что у тебя сейчас крутится на Intel.
Разумеется. Нужно сказать, что Arm-экосистема софта шагнула далеко вперед. Если пять лет назад были проблемы с тем, чтобы поднять железку, то сейчас таких проблем нет. Вы просто приходите, и у вас всё работает out of the box. Работает всё, к чему вы привыкли — Linux, Docker, Kubernetes, Xen, Java, Hadoop, Spark, Kafka, все что угодно.
Что насчет Java? Расскажите, как она работает, чем отличается от «обычной»?
Ничем не отличается, в этом и есть ее основное преимущество. Она достаточно производительная для того, чтобы справляться с теми задачами, которые возложены на Java для серверов. Вы переносите свое приложение (надеюсь, что у него нет нативной части, иначе придется его рекомпилировать), на Arm-сервер, проверяете производительность и в большинстве случаев — радуетесь. Недавно вышла статья, где мы сравниваем производительность Arm-сервера с Intel-сервером. Статья вышла в Java Magazine.
Oracle позволили вам, по сути, прорекламироваться в собственном журнале? Серьезно.
Видимо, есть спрос. Получается, что Java Arm-сервера для Java-ворклоадов вполне хорошо себя показывают. Они такие же, или даже лучше по сравнению со своими аналогами у Intel.
Кому стоит прочитать вашу статью?
Тому, кто хочет посмотреть, протестировать новую архитектуру, подходит ли она для его нагрузок. Попробовать и Java, и те самые Arm-сервера. В Google вбиваете Arm Server Cloud, и вам выпадает несколько облачных провайдеров, можно провести карточкой и попробовать то, что вам нужно.
Там уже предустановлена Java?
Да. Обычная OpenJDK.
А обычная OpenJDK и ваш дистрибутив Liberica — это одно и то же? Я видел, что там есть ваши коммиты — это оно или что-то другое?
Вообще, история Arm-портов и OpenJDK достаточно интересная и витиеватая. Изначально в Oracle развивали Arm-порт и, когда Arm выпустил архитектуру ARMv8, к этому Arm-порту был добавлен дополнительный порт, который позволял запускать Java на ARMv8. Параллельно с этим Red Hat тоже работал в этом направлении и в OpenJDK влил свой порт для этой архитектуры. Так получилось, что коммьюнити сосредоточилось именно на порте Red Hat. Поэтому сейчас тот довесочек, который был в OpenJDK для порта ARM32, который фактически дублировал функциональность порта aarch64 — мы его волевым решением оттуда уберем в JDK 12. Для этого есть JEP 340.
Надо сказать, что Oracle влил в OpenJDK все свои наработки от embedded, все Arm-порты перед тем, как прекратить поддержку. Сейчас влиты все фичи для Arm, которые делались в Oracle.
Это логично, потому что именно производители железа и производители спецификации должны быть в первую очередь заинтересованы, чтобы софтовая экосистема работала на их железе и была совместима с их спецификациями. Для этого нужно, чтобы код был открытым.
Я видел инфографику, на которой нарисованы поразительные цифры о том, что некая компания BellSoft, расположенная в Санкт-Петербурге, залила огромное количество коммитов.
Да, мы входим в топ-5 коммитеров OpenJDK. Естественно Oracle вне конкуренции находится, там около 4 тысяч коммитов за год.
Дальше идет Red Hat, SAP, Google и BellSoft. Мы немножко не дотянулись до Google. А сразу за нами — IBM.
Какой процент ваших сотрудников раньше работал в Oracle?
100 процентов. BellSoft состоит из бывших сотрудников Oracle.
Это нечестная конкуренция, потому что Google не состоит из 100 процентов сотрудников Oracle. Что за комммиты, расскажите? Как достичь такого успеха? Как попасть в топ-5 коммитеров?
Мы работаем в нескольких направлениях. Сейчас основное направление, куда идут наши коммиты, — это порт ARM64, который тот самый серверный порт. Он интересен производителям железа. Им интересно, чтобы Java быстро работала на их железе, справлялась с нагрузками. Второе, куда коммитим, — это порт ARM32, который нами поддерживается, это embedded-порт. Третье — это коммиты, направленные на поддержку, исправление и улучшение общего функционала Java.
Мы говорили только что о 64 битах на серверах. Почему 32-битный порт еще живой?
Потому что он используется в embedded.
Потому что очень много компаний реализовало CPU для архитекутры ARMv7 для встроенных применений. У них на складах лежит большое количество чипов. Если мне не изменяет память, то из всего многообразия этих чипов ARM32, самый популярный — ARMv5. Этой архитектуре уже очень много лет, но тем не менее, CPU достаточно дешевые, и производители до сих пор рассматривают создание новых устройств именно на этой архитектуре
О каких суммах мы говорим, когда говорим о встройке? Может обычный человек себе купить что-нибудь и поэкспериментировать?
Самое популярное из платформы ARM32 — это Raspberry Pi, начиная со второй версии — вторая и третья версии, плюс все это поддерживается ARM32-портом. Один из наших дистрибутивов — тот, который для ARM32, тестируется и работает именно на Raspberry Pi. Мы видим, что это самая распространенная платформа для широкой аудитории, и поэтому выпускаем порт именно для Raspberry Pi. У нас есть более специфические порты для узкоспециализированного железа, но это другая история.
Может, и покупать не надо. Можно посмотреть, что у вас стоит в домашнем роутере. Очень вероятно, что там что-нибудь такое.
Насколько там должны скиллы разработчика соответствовать?
Нужно быть Java-разработчиком.
Нужны ли хитрые способы, закон Кирхгофа знать, чтобы закодить?
У вас просто компьютер, к которому вы можете подключиться по SSH. Никакого умения его прошивать не нужно. Вы берете MicroSD-карточку с образом линукса для Raspberry Pi, вставляете ее, и все запускается. В этом основной плюс Raspberry Pi по сравнению со всеми другими single board computers. Простота его настройки, получение работоспособной системы.
А как с датчиками работать? Мы же все это ради внешних систем делаем, так?
У Raspberry Pi есть система GPIO и пины, к которым вы можете подключать все что угодно. На чем обычно все энтузиасты всякую периферию к Raspberry Pi и подключают.
Как API выглядит? Что нужно написать, типа, «получи мне с термостата чиселку»?
Нужно прочесть даташит термостата, и понять, какие есть регистры, как его инициализировать, как его конфигурировать. Если I2C, вызвать метод для конфигурации, туда передать все параметры. Потом сказать ему i2c.open, и работать с ним как с Java-объектом.
А можно вокруг термостатов написать красивые объектные оберточки, чтобы потом работать в чисто объектной модели? Можно сделать так, чтобы не читать больше даташит, закрыть его фасадом?
Хорошо бы, чтобы производитель этого датчика сделал готовый конфиг, и мы как Java-программисты просто брали его и пользовались. Библиотека работает с одним датчиком, библиотека для работы с другим датчиком. Такая библиотека или что-то близкое к этому есть, называется Pi4J. Она развивается сейчас не так бурно, как во времена, когда Oracle двигал Java embedded, но она все равно не умерла, периодически выходят какие-то обновления. Здесь есть выбор: либо работать с вещью, которая в OpenJDK — GPIO, либо работать с библиотечкой Pi4J.
Если я производитель железяки, ничего не знаю о Java, но хотел бы, чтобы Java-программисты могли пользоваться ей, к кому обратиться? К вам обратиться? Или есть специалисты, которые этим занимаются?
Да, мы и есть такие специалисты.
Пока мы далеко не убежали. Помню, что у вас были какие-то свои JEP, да?
В 11 версию OpenJDK вошло 17 JEP. 14 было сделано Oracle, 1— Google, 1 — Red Hat, 1 — BellSoft совместно с Cavium. Наш JEP — сборная солянка улучшений производительности Java на платформе ARM64 под конкретные ворклоады. JEP, соответственно, называется Improve Aarch64 Intrinsics. Если кратко, то мы улучшили производительность операций со String, с массивами и немного с математикой и тригонометрией.
Что такое интринсики? Не все знают.
Когда виртуальная машина считает синус, вместо того, чтобы выполнять непосредственный Java-код, может подставить оптимизированную ассемблерную вставку под конкретную архитектуру.
Которая напрямую зовёт процессор, который имеет команду «синус»?
Которая вычислит его по сложному алгоритму. Есть интринсики, которые вызывают какую-то команду ассемблера. Например, интринсики, связанные с вычислением чексумм. Такие ассемблерные инструкции есть практически для всех архитектур. Есть более сложные интринсики, когда для получения хорошего прироста производительности писать много страниц ассемблера.
А шифрование, оно есть в железе?
Да, обычно это вызов существующих инструкций конкретного процессора. Иногда — работа с расширениями на тех чипах, где они есть.
Возвращаясь к вашему JEP: как определить, какой код является настолько горячим, что его стоит так хардкодить?
Отличный вопрос. Когда мы начали оптимизировать что-то под платформы ARM64, большого количества тулов у нас не было, помимо perf. Да и тот работал не везде. Реализация JFR для ARM64-порта отсутствовала, Oracle к тому моменту еще не выложила в Open Source. Различные тулы для измерения перформанса, которыми мы привыкли пользоваться, например, async-profiler, honest-profiler — они для платформ ARM64 тоже не работали. Первое, что мы сделали — завели все эти тулы на этой архитектуре.
Почему не работают из коробки?
Потому что там есть какая-то CPU-специфичная часть.
Дальше запускаешь эти тулы на том ворклоаде, который ты пытаешься оптимизировать, долго смотришь в экран, пытаешься понять, какие методы там горячие, какие места в них горячие. Есть простые случаи, когда какие-то ассемблерные вставки под конкретную архитектуру не реализованы. В этом случае происходит fallback в Java код. Просто реализовав эти ассемблерные вставки можно получить увеличение производительности. Есть более сложные места, когда нужно понять какую новую ассемблерную вставку нужно в Java создать для всех архитектур. Такая работа.
Сам датасет откуда взять? Выкачать весь гитхаб и запустить под JIT?
Понятно, что происходит оптимизация каких-то бенчмарков или ворклоадов. Бенчмарки известные — SpecJBB, SpecJVM. Есть конкретные ворклоады, которые интересуют конкретных заказчиков. Просто запускаете эти ворклоады и смотрите на узкие места.
Все эти SpecJVM — очень старые тесты, да? Что насчет новых лямбд, стримов, биг даты?
Ничего. Там этого нет.
И где это достать?
Новые ворклоады.
Например, апачевский стек?
Да. У Hadoop есть стандартный бенчмарк TeraSort, которым производители железок любят мериться. Тоже одна из интересных задач для оптимизации.
Какой сейчас топ функций, которые стоит оптимизировать? Например, топ из того самого JEP.
Основные проблемные места для этой архитектуры, которые там были, мы закрыли. Там, разумеется, есть еще непаханое поле того, что мы не сделали и что будем продолжать делать. Будем продолжать работать с тригонометрией, будем смотреть на новые интринсики, которые будут появляться. Их еще нет, но мы понимаем, что они в скором времени появятся. Придется смотреть в проект Panama, в который сейчас очень активно контрибьюит Intel.
Как компилятор увидит, что ты делаешь? Условно, магическим образом поймет, что ты считаешь какую-то известную формулу и заоптимизирует?
Если вы вызываете Math.sin, то вместо Java-реализации этого sin вполне возможно подставить ассемблерную вставку.
Там где-то стоит регулярка, которая ищет все sin и заменяет на это?
Да. Это обычно делается даже не в компиляторе, а начиная с интерпретатора.
Что-то более сложное может ловить, например, операции в счетных циклах?
Обычно такие задачи решаются в рамках C2, и писать и поддерживать специализированные интрински не имеет смысла.
Для этого нужно иметь какого-то специалиста. Например, Иванова или Чуйко?
Чуйко работает у нас.
Он сейчас уехал в Канаду, будет рассказывать на конференции Linaro Connect о наших достижениях в улучшении OpenJDK на архитектуре ARM64. Linaro Foundation занимается разработкой экосистемы для Arm-платформ.
Откуда у них деньги на это?
От Arm, в первую очередь. И от производителей железа.
Какие самые сложные или интересные челленджи у вас были?
Сложно так сказать. Пришлось прокачать свои познания в математике немножко. Приходите на Joker, расскажем.
Программистам нужна математика!
Да, внезапно. Не просто так разобраться с арифметикой floating point. Пришлось прокачать способность понимать, какие тут инструкции, какие у них веса, сколько они времени занимают. Эти ассемблерные вставки — очень сложный и трудоемкий процесс, их потом их сложно поддерживать. Представьт, что у вас меняется спецификация, у вас появляется новые более оптимальные инструкции — вам приходится их переписывать. Но оказывается, что с точки зрения получения мгновенной выгоды это достаточно выгодно.
Ты про веса сказал. Правильно понимаю, что есть набор оптимизаций, которые запускаются в порядке увеличения веса?
Да. Поскольку Arm предоставляет спецификацию… Они делают свои Кортексы, но основной бизнес — это предоставление лицензий на спецификацию. Дальше различные производители делаю, кто во что горазд. У кого-то инструкция будет сколько-то времени занимать, а другого производителя — другое время. Вся эта сложность, с который приходится сталкиваться, когда ты пишешь этот ассемблерный код. Вам нужно очень аккуратно понимать, что для одного типа процессоров будет оптимальна одна последовательность, для другого типа будет оптимальна другая. Разумеется, обычному Java-программисту беспокоиться нечего, за него уже про это побеспокоились.
Допустим, у какого-то корпоративного инженера оптимизации работают немного не так, как хочется. Что ему нужно сделать?
Контрибьютить в OpenJDK или идти в компанию BellSoft.
Расскажите, что нужно сделать, чтобы попасть в вашу компанию в качестве разработчика? Что нужно знать? Если ты не работник Oracle, тут все понятно. Какой набор знаний нужен JVM-инженеру?
Наверное, нужно быть контрибьютором в OpenJDK. (смеется)
Хорошо, я изменил 250 комментариев и стал контрибьютором. Подойдет?
Ты не станешь значимым контрибьютором, изменив 250 комментариев. Так не выйдет.
А если человек часто меняет библиотеки — это тоже не сильно про то? Это же сама виртуальная машина.
Главное, чтобы человек был хороший. Чтобы хорошо разбирался в алгоритмах. Понимал, как работает процессор — поскольку мы в основном работаем с достаточно низкоуровневыми вещами. Даже необязательно знать какие-то недра.
Сколько времени проходит до того, как человек в первый раз может сделать осмысленный комит?
Обычно это несколько месяцев.
И что он делает эти месяцы?
Сначала учится собирать проект. Потом учится понимать. Допустим, ему дали какую-то простую багу, и он учится понимать, в какой области всего этого многообразия ему нужно делать изменения. Потом он пытается сделать это изменение, и у него все валится, он бежит к своему соседу, тормошит его. Потом у него что-то начинает работать и он учится запускать тесты. Затем учится понимать, какие именно тесты нужно запускать. Затем учится понимать, на скольких архитектурах нужно запускать тесты, чтобы этот патч нормально протестировать. Потом учится общаться, потому что в рамках OpenJDK общение является достаточно важной составляющей.
А как вы общаетесь?
Mailing list. Если чего-то нет в mailing list, то его нет.
А баг-трекер?
Jira. В OpenJDK открытая Jira, в которую все люди, которые стали авторами, получают доступ.
У вас нет своей Jira для Jira, которая будет джирить, пока джиришь?
Для OpenJDK такого нет. Естественно есть другие проекты, в которых у нас есть своя Jira.
Сколько у вас архитектур? Я иду по списку, который ты назвал, и все понятно насчет общения, но непонятно, зачем запускать на нескольких архитектурах, если у вас только Arm?
Если только Arm, то, может, и не надо запускать на других архитектурах. Но если вы делаете изменение в shared-части, которое даже выглядит абсолютно безобидно, это может аукнуться много где. Вначале нужно понять, где оно может аукнуться. А потом нужно тестировать.
Как выглядит матрица тестов, совместимости. Потому что у меня есть подозрение, что она очень большая.
Есть тесты, а есть конфигурации. Мы считали количество комбинаций флажков HotSpot, архитектур, тестов, и получили число десять в пятидесятой. Понять, где нужно запустить тесты, чтобы что-то протестировать — не такая тривиальная задача.
У вас есть какой-то стандартный набор конфигураций?
Да. В том же HotSpot тесты организованы по tiers. Начиная с обычных smoke-тестов и заканчивая достаточно серьезными тестами. Тестируя различные тиры и получая всю картинку, вы понимаете, как оно выглядит. Разумеется, performance-тестирование, stress-тестирование.
Более общий вопрос. Представь, что вчера случилось ещё одно чудо, и в Питере выпустили не только свою JDK, но и свой процессор. Надо на него быстренько спортировать JDK, и вы этим занялись. Из каких крупных блоков состоит портирование на новый процессор, кроме тестирования?
Основным компонентом JDK, который нужно будет портировать, является JVM. JVM можно условно разбить на 4 части: runtime, serviceability, garbage collector, compiler. Практически во всех четырех компонентах нужно будет произвести какие-то изменения. Если у вас будет собственная новая операционная система под этот процессор, то скорее всего нужно будет изменять и runtime. Если у этого процессора какие-то не очень понятные взаимоотношения с памятью и с out of order execution, то скорее всего, вам придется и в GC залезть. Если у вас просто новая архитектура, то в основном это будут JIT, в которые вам нужно будет вкладываться. Основной вклад community и производителей железа в OpenJDK — это именно в JIT.
Если посмотреть не на создание, а на поддержку, где больше всего изменений?
Все меняется, все течет. Этого не видно извне, но очень много изменений происходит в библиотеках. Большая работа проходит по оптимизации библиотек. Но в компиляторе наибольшее количество изменений. И новые компиляторы появляются, и старые начинают работать по-другому, и новые архитектуры появляются, для которых нужно писать новые оптимизации.
Какая часть вашей работы по созданию этой штуки связана именно с поддержкой? Десять процентов? Девяносто? Если постоянно все меняется, значит, надо за этим следить и что-то изменять?
Сложно посчитать процент работы. Разумеется, это очень заметный процент.
Александр, я вижу, что ты уже долгое время хочешь что-то интересное рассказать, а мы тут про компиляторы. Твой ход.
Расскажу про статью. Спрашивали, кому стоит прочесть статью Алексея про OpenJDK на Arm. Я считаю, что ее нужно прочесть всем людям, которые имеют отношение к IT. Во-первых, Алексей в статье рассказывает о том ландшафте, который в экосистеме Arm сейчас есть. О том, как эволюционировала спецификация Arm, как Arm дошел до такой жизни, что оказался на серверах. Дальше Алексей рассказывает о том, что происходит в OpenJDK, в приложении к экосистеме Arm. И показывает, как работают бенчмарки, какие результаты имеются. Сравниваются производители Arm процессоров с аналогичными процессорами Intel на SPEC-ах. Поэтому мне кажется, что эта информация должна быть полезна всем. Мир меняется у нас на глазах прямо сейчас. И никто об этом не знает практически!
У меня уши не покраснели, пока Александр рассказывал?
Нет, а почему должны были?
Мне должно быть стать стыдно за то, что я сделал.
Всё мы делаем правильно. Алексей ведет просветительскую работу сообщества. Кто сегодня знает о том, что выпускается серверы на архитектуре ARM64? Единицы людей. А на самом деле у нас есть информация о том, что в штатах на процессорах Arm строятся вычислительные центры и суперкомпьютеры.
Очень большие компании смотрят именно на эту альтернативу.
Но сейчас суперкомпьютеры — это, грубо говоря, некий дата-центр, в котором куча юнитов соединена между собой. Вы про это говорите? Или это какие-то большие блоки, в которых миллиарды ядер Arm?
Из публичных источников можно увидеть, что обычно это суперкластеры.
Какое будущее у этого дела?
Сейчас восход Arm на рынке серверов. Все еще находится в зачаточном состоянии и на широкий рынок пока это не выходит. Кто сейчас главный потребитель всей этой истории процессоров, памяти, железа? Это облачные провайдеры. Они очень серьезно смотрят на эту архитектуру.
Саш, я позволю себе тут с тобой не согласиться. То, что они серьезно смотрят, уже является индикатором, что это уже в достаточно серьезном состоянии. Если бы вам кто-нибудь 10 лет назад сказал, что вы будете на GPU что-нибудь считать, вы бы удивились. А сейчас все Cloud-провайдеры предоставляют такую возможность. Если посмотреть на это чуть более глобально, есть определенные нагрузки, под них производители делаю что-то. Есть нагрузка которую оптимально считать на GPU, есть нагрузка для CPU. Есть нагрузка просто ответить в Интернет что-нибудь, HTTP 404. Это разные нагрузки, под них нужно разное железо. Все эти облачные провайдеры становятся либо более специализированными, либо начинают предлагать продукты под конкретные нагрузки.
Как понять, что какая-то из технологий достаточно зрелая, чтобы на нее был смысл смотреть? Есть ли какие-то индикаторы основные?
Все начинается с нагрузки. С того, что нужно данному конкретному потребителю. Ему нужно получить ответ за 30 миллисекунд на любой запрос или ему нужно считать тяжелую математическую задачу наиболее быстро или ему нужно посчитать эту математическую задачу наиболее дешево? Под все эти разнообразные нагрзуки будет оптимально использовать разное железо. Нельзя сказать, что под конкретную задачу всё уже готово или нет. Просто какое-то решение становится в определенный момент более конкурентоспособным, чем нечто, что было раньше. И вы начинаете по нескольким параметрам перебирать: по этому параметру стало на 20% лучше, по этому тоже на 20%, а по этому — на 10%, дай-ка попробую эту технологию. Мне кажется, что для серверов на Arm такой момент настал.
То есть у нас есть довольно хорошая технология, у нас есть Java, и у нас есть люди, которые все это поддерживают так или иначе. Жаль, что рядом с нами нет производителей железа сейчас, чтобы был полный комплект.
Мы все время говорим про Arm и может сложиться впечатление, что BellSoft — это исключительно Arm, но это не так. Мы контрибьютим во все порты OpenJDK, если у нас возникают какие-то проблемы с портом. И Liberica сегодня уже не только Liberica на Arm 32 и 64, Liberica сегодня доступна на Linux (64 бита), на Windows и в ближайшее время мы выпустим Liberica для Mac. И еще у нас есть Liberica для Solaris Sparc. Это для очень специфичных заказчиков.
Зачем Liberica на Mac? На нем же нет дата-центров.
Ну ведь на маке джава нужна? Сейчас Oracle перестанет выпускать патчи, буквально уже немного времени осталось… До января. И что произойдет?
Что с патчами происходит?
В другой раз можем рассказать подробно про то, что происходит с патчами в Oracle. Если совсем коротко, то Java-мир больше никогда не будет прежним.
Но зато в Java-мире теперь появятся сборки других производителей.
Да, и это хорошо. Чем больше производителей будут работать в одном проекте, тем лучше.
Появится конкуренция.
Да. Во-первых, конкуренция будет за support заказчиков. Кому-то нужна поддержка — банкам, платежным системам, Cloud-провайдерам. Им важно, чтобы в случае, если возникает какая-то проблема, она была решена в короткие сроки.
Раньше я работал в банке, многие инженеры поддержки всегда ставили Oracle JDK не из соображений, что там есть дополнительные API. Никто на моей памяти не писал -XX:+UnlockCommercialFeatures. Я сейчас не про конкретный банк, а вообще про поддержку на проде. Но люди считают, что только в Oracle точно знают, как правильно это готовить.
Так ты абсолютно прав, потому что мы всегда рассчитывали на Oracle и на апдейт-релизы Oracle, которые выходили регулярно. Ими все пользовались. Даже на десктопах Java апдейтилась сама, ничего делать не надо было.
По статистике, которую мы видим, все больше внешних контрибьюторов приходит в OpenJDK и все больше и больше новых фич разрабатывается внешними контрибьюторами. Больше и больше саппорта предоставляется этими котрибьюторами. BellSoft в этом отношении находимся в очень интересном положении, потому что мы тоже знаем, как готовить.
Мы обсудили много различных направлений и вы, похоже, во всех них разбираетесь. Давайте потом отдельно по каждому направлению поговорим. Например, про то, как внутри устроена OpenJDK — это отличная большая тема.
С удовольствием!
Хорошо. Мы приближаемся к концу этого увлекательного разговора, и поэтому — последний вопрос. Можете что-нибудь посоветовать нашим читателям на Хабре?
Советую прочесть статью Алексея. Ваш кругозор расширится пониманием того, что есть еще одна архитектура, альтернативная той, к которой мы привыкли. И у нее есть своя экосистема программного обеспечения.
Возьмите какой-нибудь простой баг и попробуйте его исправить в OpenJDK.
Звучит как огромный квест. Что еще?
Скачайте Liberica, запустите. Не обязательно на Raspberi Pi, можно на Linux-сервере. Расскажите друзьям о том, что есть русская Java, которая делается в Санкт-Петербурге.
А еще можно прийти к нам на Joker, на котором у тебя будет доклад, а у BellSoft — стенд в демозоне.
Приходите с нами пообщаться. Будем я, Алексей, Дмитрий Чуйко. Дмитрий не уедет, мы его зарезервировали :-) Joker — очень важное для нас событие.
Спасибо вам, было очень круто. Ждем вас в следующий раз!
Минутка рекламы. Александр и Алексей приедут на конференцию Joker 2018 с докладом «Дорогая, попробуем ARM? Теория, приложения и рабочие нагрузки». Приобрести билеты можно на официальном сайте конференции.
