Здравствуй, Хабр!
В этой статье я хочу поделиться опытом распознавания рукописных математических выражений. Хотя уже и существуют такие средства распознавания рукописных формул как «Панель математического ввода» mip.exe в Windows7, разнообразие подходов к решению данной проблемы не может не впечатлять. Об одном из таких подходов я и собираюсь рассказать.

Распознавание математических выражений является более сложным видом распознавания, нежели распознавание символов, так как кроме распознавания непосредственно математического символа необходимо также распознать структуру математического выражения.
В он-лайн распознавании рукописного математического выражения обычно выделяют следующие стадии:
За десятилетия иследований в области распознавания математических выражений придумано огромное количество алгоритмов и теории. Я же расскажу о простом подходе, который, тем не менее, дает хороший результат. Он предполагает, что стадии 1, 2 и 3 работают вместе, и на выходе дают список символов, который распознается как математическое выражение на стадии 4.
Первым шагом является сбор и предварительная обработка данных. Обучающее множество для конкретного класса символов состоит из множества символов. Символ является упорядоченным набором росчерков, а росчерк является упорядоченным набором пар (x,y), где первая пара соответствует точке касания пера, а последняя — точке отрыва. Каждый символ рисуется определенным количеством росчерков в определенном порядке.
Целью предварительной обработки данных является преобразование «сырых» данных росчерков в формат, который позволяет создать модель символа с целью его дальнейшей классификации. Для упрощения модели необходимо удалить ту информацию, которая не нужна при классификации. Начальное множество росчерков преобразуется в вектор определенной и жестко фиксированной размерности.
Масштабирование, сдвиг и изменение количества опорных точек
Каждая точка каждого росчерка сдвигается так, что начальная точка является верхним левым углом ограничивающей рамки символа. После этого все точки масштабируются с сохранением отношения ширины к высоте так, что символ помещается внутри квадрата. Далее, набор точек каждого росчерка изменяется так, чтобы точки располагались равноудаленно (передискретизация по длине дуги методом линейной интерполяции). Количество точек фиксировано и равно 36/N, где N – количество росчерков в символе (36 делится на 1, 2, 3 и 4, где 4 — максимальное количество росчерков в одном символе).
В завершение, координаты точек собираются в единый вектор из 72 элементов, где первые 36 элементов представляют координаты по x, а последние — координаты по y.

Что мы получили?
А получили мы набор векторов одной размерности, где каждому классу символов соответствует определенное количество векторов. Эту информацию можно использовать, например, для обучения нейронной сети, или для распознавания символа по алгоритму k-ближайших соседей.
На самом деле, размерность вектора можно уменьшить в несколько раз, при этом не потеряв практически никакой информации. Алгоритм этот назвается «Метод главных компонент».
В итоге было создано следующее нечто для обучения классификатора:

Классификатор распознает символы по отдельности. Однако, когда необходимо распознавать потоковый ввод, он не может заранее знать, какие росчерки составляют символ, и сколько символов всего введено. Следовательно, возможности классификатора необходимо дополнить определением количества и расположения символов выражения. Решение этой проблемы эквивалентно наилучшей группировке росчерков в символы, называемой сегментацией выражения.
Предположим, что введенные росчерки упорядочены по времени, то есть при вводе символа, состоящего из трех росчерков, последовательно вводятся росчерки данного символа. Например, не допускается ставить точку над символом i после написания символов, которые следуют после i. С учетом данного предположения, для определения символов, состоящих из нескольких росчерков, необходимо последовательно рассматривать группы росчерков, размером от 1 до N (N в нашем случае равно 4). Если символ из нескольких росчерков распознается классификатором с ошибкой, меньшей определенного порога, то отдается предпочтение данному символу. При этом количество рассматриваемых комбинаций равняется F(N)=O(kN). В случае, если ни один из результатов классификации не превосходит порогового значения, пороговое значение увеличивается и шаг повторяется, либо возникает ошибка распознавания.
Необходимо отметить, что некоторые символы, которые невозможно распознать как различные (например, знаки минуса и дроби), обозначаются как один символ (горизонтальная черта), который переименуется в ходе структурного анализа.
Алгоритм сегментации можно улучшить, если для каждого количества росчерков определить допустимые символы. Так, два росчерка не могут быть распознаны как символ, состоящий из одного или трех росчерков.

Также при реализации данного алгоритма для того, чтобы предотвратить возможные ошибки сегментации, необходим интерфейс, позволяющий мгновенно исправить некорректный результат, или отменить ввод последнего символа.
Разрешение неоднозначностей
Классификатор не может знать, ввели ли мы символ «минус» или символ «дробь». Для этого необходима дополнительная проверка. Так, на определенном расстоянии вверх и вниз от черты символа «минус» не будет расположено никаких росчерков, а у символа «дробь» — будут. На основании этого производится переименование символа «черта» в символ «минус» или «дробь» соответственно. Практически аналогично — с десятичной точкой и знаком умножения.
Теперь, наконец, перейдем к распознаванию структуры выражения :-)
Области и атрибуты символов
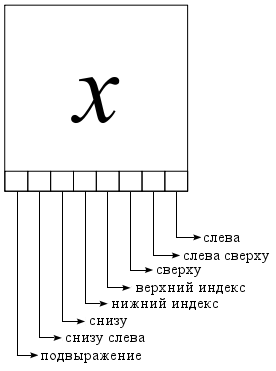
Отношения математических операторов определяются в зависимости от позиции и относительного размера символа в выражении. Для определения отношений используются пространственные области «сверху слева», «сверху», «верхний индекс», «нижний индекс», «снизу», «снизу слева» и «подвыражение». Например, ожидается, что операнды (числитель и знаменатель) горизонтальной линии (оператора дроби) будут лежать в областях «сверху» и «снизу» относительно горизонтальной линии

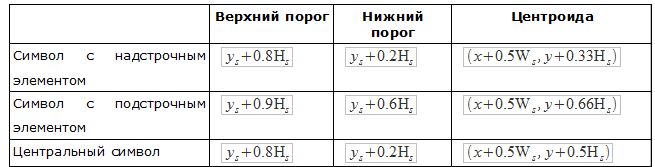
Исходя из простых атрибутов (верхняя граница, правая граница, и т.д.), можно определить порог верхнего индекса, порог нижнего индекса и прочие атрибуты. Это численные атрибуты, которые используются для отделения областей вокруг символа. Также исходя из простых атрибутов можно определить центральную точку.
Центральная точка — это точка, которая определяет расположение символа в какой-либо из областей. Для определения атрибутов символа, символ классифицируется как с надстрочным элементом, с подстрочным элементом или центральный.

Каждый класс символов имеет по-разному определяемые атрибуты. Это необходимо для того, чтобы избежать неоднозначностей при структурном анализе:

Базовая линия выражения
Базовая линия — это список, который представляет горизонтальное расположение символов в выражении. Каждый символ имеет ссылки на другие базовые линии, которые удовлетворяют различным пространственным отношениям.

Доминирование символов и доминирующая базовая линия
Доминирование определяется следующим образом: символ s доминирует над символом a, если a лежит в области s, а s не лежит в области a. Однако, оба символа могут лежать в областях друг друга. В итоге, вычисление функции
Если имеется упорядоченный список символов L, то можно определить крайний левый доминирующий символ в списке путем выполнения следующей рекурсивной процедуры:
Доминирующая базовая линия выражения — это базовая линия, на которую не ссылается никакой символ. Во время чтения математического выражения обычно сначала производится поиск крайнего левого доминирующего символа, затем следующего за ним доминирующего символа, и так далее, пока не будут найдены все символы базовой линии.
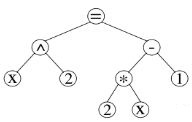
Структура данных, которая представляет выражение, называется деревом базовых линий. Предположим, у нас есть выражение

Тогда дерево базовых линий этого выражения будет иметь следующий вид:

Доминирующую базовую линию Db конструируем с помощью следующей функции:
Дерево базовых линий создается рекурсивным нахождением доминирующих базовых линий в выражении, описанном упорядоченным списком символов L.
Полученное дерево представляет собой структуру математического выражения, и ее, распарсив, можно преобразовать в код формульного редактора. В моем случае это редактор OpenOffice.
Аполучилась GLaDOS получилось из этого алгоритма приложение, которое, хоть и не лишено способности совершать ошибки в распознавании отдельных символов, но может на лету распознать достаточно сложные математические выражения. Вот так оно выглядит:
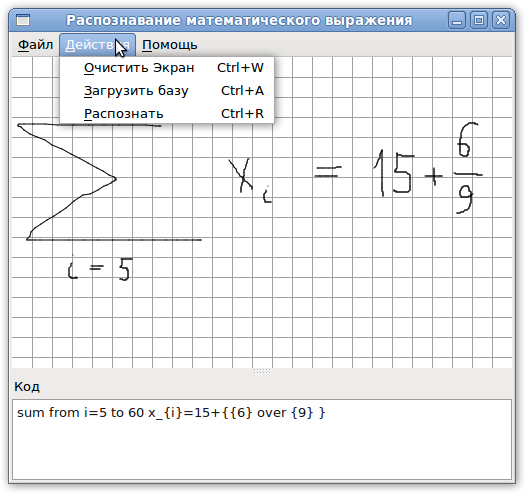
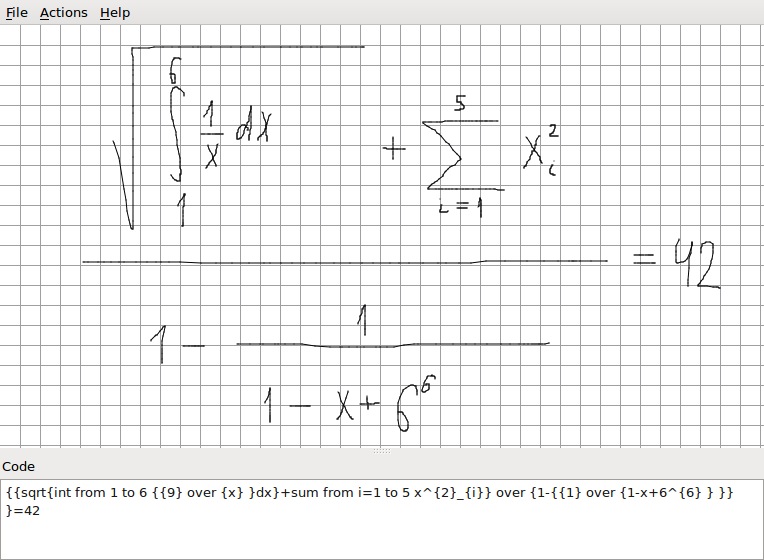
И может распознавать, хоть иногда и не без ошибок, вот такие формулы (а кто первый найдет ошибку распознавания символа — тот молодец :-)

Вот и закончилась моя первая статья на Хабре. Надеюсь, она не была очень занудной, и будет кому-то полезной! Благодарю за внимание!
Литература:
В этой статье я хочу поделиться опытом распознавания рукописных математических выражений. Хотя уже и существуют такие средства распознавания рукописных формул как «Панель математического ввода» mip.exe в Windows7, разнообразие подходов к решению данной проблемы не может не впечатлять. Об одном из таких подходов я и собираюсь рассказать.

Небольшое введение
Распознавание математических выражений является более сложным видом распознавания, нежели распознавание символов, так как кроме распознавания непосредственно математического символа необходимо также распознать структуру математического выражения.
В он-лайн распознавании рукописного математического выражения обычно выделяют следующие стадии:
- Сбор и предварительная обработка данных:

- Разделение выражения на символы (сегментация выражения):

- Рапознавание отдельных символов:

- Распознавание структуры математического выражения:

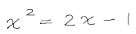
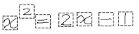

За десятилетия иследований в области распознавания математических выражений придумано огромное количество алгоритмов и теории. Я же расскажу о простом подходе, который, тем не менее, дает хороший результат. Он предполагает, что стадии 1, 2 и 3 работают вместе, и на выходе дают список символов, который распознается как математическое выражение на стадии 4.
Сбор и предварительная обработка данных
Первым шагом является сбор и предварительная обработка данных. Обучающее множество для конкретного класса символов состоит из множества символов. Символ является упорядоченным набором росчерков, а росчерк является упорядоченным набором пар (x,y), где первая пара соответствует точке касания пера, а последняя — точке отрыва. Каждый символ рисуется определенным количеством росчерков в определенном порядке.
Целью предварительной обработки данных является преобразование «сырых» данных росчерков в формат, который позволяет создать модель символа с целью его дальнейшей классификации. Для упрощения модели необходимо удалить ту информацию, которая не нужна при классификации. Начальное множество росчерков преобразуется в вектор определенной и жестко фиксированной размерности.
Масштабирование, сдвиг и изменение количества опорных точек
Каждая точка каждого росчерка сдвигается так, что начальная точка является верхним левым углом ограничивающей рамки символа. После этого все точки масштабируются с сохранением отношения ширины к высоте так, что символ помещается внутри квадрата. Далее, набор точек каждого росчерка изменяется так, чтобы точки располагались равноудаленно (передискретизация по длине дуги методом линейной интерполяции). Количество точек фиксировано и равно 36/N, где N – количество росчерков в символе (36 делится на 1, 2, 3 и 4, где 4 — максимальное количество росчерков в одном символе).
В завершение, координаты точек собираются в единый вектор из 72 элементов, где первые 36 элементов представляют координаты по x, а последние — координаты по y.
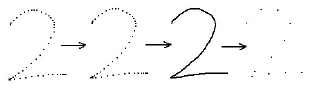
Что мы получили?
А получили мы набор векторов одной размерности, где каждому классу символов соответствует определенное количество векторов. Эту информацию можно использовать, например, для обучения нейронной сети, или для распознавания символа по алгоритму k-ближайших соседей.
На самом деле, размерность вектора можно уменьшить в несколько раз, при этом не потеряв практически никакой информации. Алгоритм этот назвается «Метод главных компонент».
В итоге было создано следующее нечто для обучения классификатора:
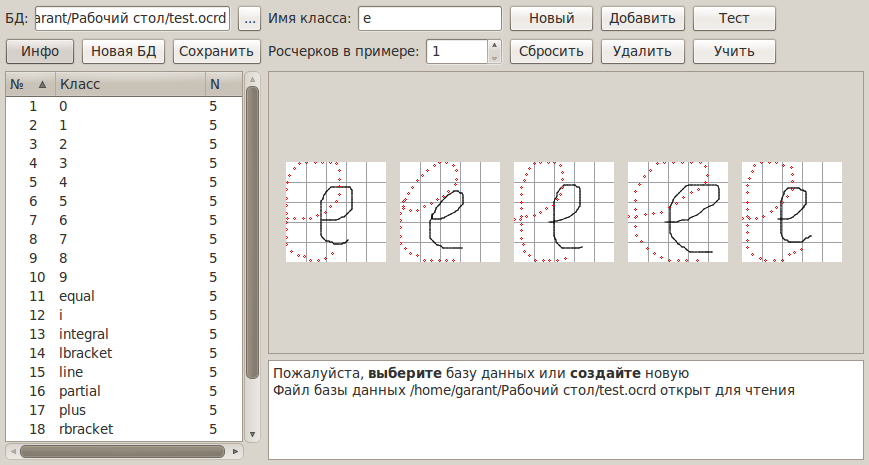
Сегментация и распознавание отдельных символов
Классификатор распознает символы по отдельности. Однако, когда необходимо распознавать потоковый ввод, он не может заранее знать, какие росчерки составляют символ, и сколько символов всего введено. Следовательно, возможности классификатора необходимо дополнить определением количества и расположения символов выражения. Решение этой проблемы эквивалентно наилучшей группировке росчерков в символы, называемой сегментацией выражения.
Предположим, что введенные росчерки упорядочены по времени, то есть при вводе символа, состоящего из трех росчерков, последовательно вводятся росчерки данного символа. Например, не допускается ставить точку над символом i после написания символов, которые следуют после i. С учетом данного предположения, для определения символов, состоящих из нескольких росчерков, необходимо последовательно рассматривать группы росчерков, размером от 1 до N (N в нашем случае равно 4). Если символ из нескольких росчерков распознается классификатором с ошибкой, меньшей определенного порога, то отдается предпочтение данному символу. При этом количество рассматриваемых комбинаций равняется F(N)=O(kN). В случае, если ни один из результатов классификации не превосходит порогового значения, пороговое значение увеличивается и шаг повторяется, либо возникает ошибка распознавания.
Необходимо отметить, что некоторые символы, которые невозможно распознать как различные (например, знаки минуса и дроби), обозначаются как один символ (горизонтальная черта), который переименуется в ходе структурного анализа.
Алгоритм сегментации можно улучшить, если для каждого количества росчерков определить допустимые символы. Так, два росчерка не могут быть распознаны как символ, состоящий из одного или трех росчерков.
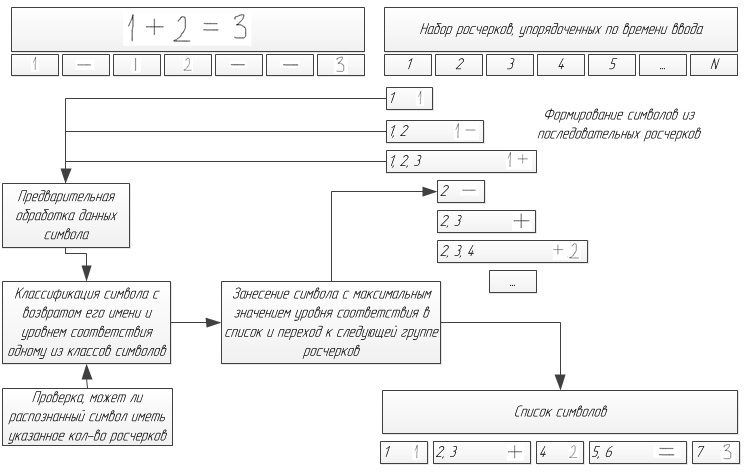
Также при реализации данного алгоритма для того, чтобы предотвратить возможные ошибки сегментации, необходим интерфейс, позволяющий мгновенно исправить некорректный результат, или отменить ввод последнего символа.
Разрешение неоднозначностей
Классификатор не может знать, ввели ли мы символ «минус» или символ «дробь». Для этого необходима дополнительная проверка. Так, на определенном расстоянии вверх и вниз от черты символа «минус» не будет расположено никаких росчерков, а у символа «дробь» — будут. На основании этого производится переименование символа «черта» в символ «минус» или «дробь» соответственно. Практически аналогично — с десятичной точкой и знаком умножения.
Теперь, наконец, перейдем к распознаванию структуры выражения :-)
Распознавание структуры выражения
Области и атрибуты символов
Отношения математических операторов определяются в зависимости от позиции и относительного размера символа в выражении. Для определения отношений используются пространственные области «сверху слева», «сверху», «верхний индекс», «нижний индекс», «снизу», «снизу слева» и «подвыражение». Например, ожидается, что операнды (числитель и знаменатель) горизонтальной линии (оператора дроби) будут лежать в областях «сверху» и «снизу» относительно горизонтальной линии
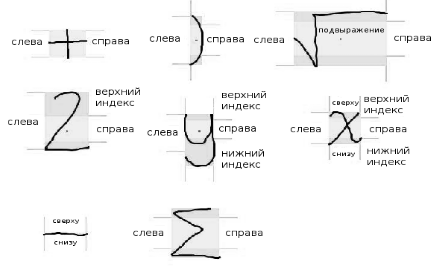
Исходя из простых атрибутов (верхняя граница, правая граница, и т.д.), можно определить порог верхнего индекса, порог нижнего индекса и прочие атрибуты. Это численные атрибуты, которые используются для отделения областей вокруг символа. Также исходя из простых атрибутов можно определить центральную точку.
Центральная точка — это точка, которая определяет расположение символа в какой-либо из областей. Для определения атрибутов символа, символ классифицируется как с надстрочным элементом, с подстрочным элементом или центральный.
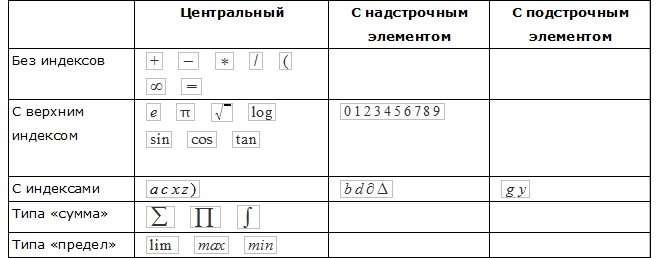
Каждый класс символов имеет по-разному определяемые атрибуты. Это необходимо для того, чтобы избежать неоднозначностей при структурном анализе:
Базовая линия выражения
Базовая линия — это список, который представляет горизонтальное расположение символов в выражении. Каждый символ имеет ссылки на другие базовые линии, которые удовлетворяют различным пространственным отношениям.
Доминирование символов и доминирующая базовая линия
Доминирование определяется следующим образом: символ s доминирует над символом a, если a лежит в области s, а s не лежит в области a. Однако, оба символа могут лежать в областях друг друга. В итоге, вычисление функции
dominates(s,a) производится следующим образом (каждый последующий шаг выполняется, если на предыдущем не удалось определить, какой символ доминирует над каким):- Проверка геометрического расположения символов.
- Проверка класса символа. Например, символ дроби будет доминировать над символом цифры.
- Проверка относительных размеров символа
Если имеется упорядоченный список символов L, то можно определить крайний левый доминирующий символ в списке путем выполнения следующей рекурсивной процедуры:
getDominantSymbol(L):
- Пусть n = length(L) — количество символов в списке.
- Если n==1, вернуть s(n)
- Если s(n) доминирует над s(n-1) , удалить s(n-1) из L, иначе удалить s(n)
- Вернуть getDominantSymbol(L).
Доминирующая базовая линия выражения — это базовая линия, на которую не ссылается никакой символ. Во время чтения математического выражения обычно сначала производится поиск крайнего левого доминирующего символа, затем следующего за ним доминирующего символа, и так далее, пока не будут найдены все символы базовой линии.
Структура данных, которая представляет выражение, называется деревом базовых линий. Предположим, у нас есть выражение

Тогда дерево базовых линий этого выражения будет иметь следующий вид:
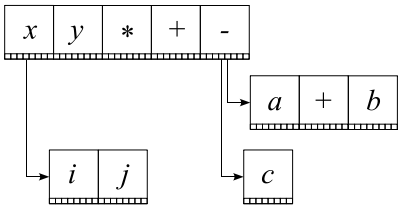
Доминирующую базовую линию Db конструируем с помощью следующей функции:
constructDominantBaseline(Db,L):
- Если Db пусто, то Db = addSymbol(Db,getDomninantSymbol(L))
- s = getLastSymbol(Db)
- Создать список Hs = getRightNeighbors(s,L) символов из L, которые являются правыми горизонтальными соседями символа s
- Если Hs пуст, выйти
- Найти доминирующий символ среди символов из Hs, sd = getDominantSymbol(Hs)
- Db = addSymbol(Db,sd)
- Рекурсия: constructDominantBaseline(Db,L)
Дерево базовых линий создается рекурсивным нахождением доминирующих базовых линий в выражении, описанном упорядоченным списком символов L.
ConstructBaselineTree(L):
- Если L пуст, выход
- Инициализация Db
- constructDominantBaseline(Db,L)
- Обновить Db, сгруппировав символы, определяющие имена функций и операторов
- Для каждого символа s из Db создать новые списки символов с потомками, в зависимости от того, каким пространственным отношениям они удовлетворяют, и создать ссылки на эти списки
- L = Db
- Для каждого символа использовать рекурсию, применяя процедуру constructBaselineTree к каждому из списков-потомков, полученных на шаге 5
Полученное дерево представляет собой структуру математического выражения, и ее, распарсив, можно преобразовать в код формульного редактора. В моем случае это редактор OpenOffice.
Что из этого всего получилось
А

И может распознавать, хоть иногда и не без ошибок, вот такие формулы (а кто первый найдет ошибку распознавания символа — тот молодец :-)
Эпилог
Вот и закончилась моя первая статья на Хабре. Надеюсь, она не была очень занудной, и будет кому-то полезной! Благодарю за внимание!
Литература:
- Nicholas Matsakis. Recognition of handwritten mathematical expressions. Master’s thesis, Massachusetts Institute of Technology, Cambridge, MA, May 1999.
- Ernesto Tapia: Understanding Mathematics: A System for the Recognition of On-Line Handwritten Mathematical Expressions, Berlin, 2004
- Eva Gallardo Perez: 2D Grammar Extension of the CMP Mathematical Formulae On-line Recognition System, Research Reports of CMP, Czech Technical University in Prague, No. 3, 2009
