Comments 53
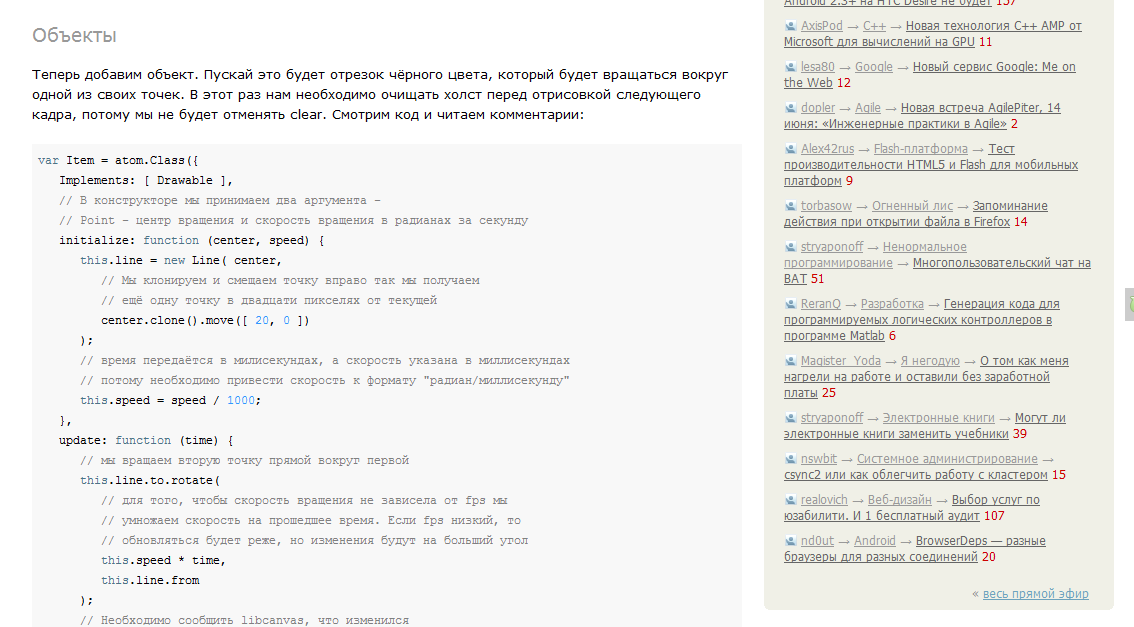
Как то не привычно когда исходный код в статье в виде картинок, по привычке попытался выделить кусок кода, когда изучал его и не получилось. А чем собственно плох тот же Source Code Highlighter?
Ну скажем так, с картинкой проще. Она лежит на официальном хостинге хабра — значит никуда не пропадёт. Форматирование и подсветка в коде именно такие как «я задумал» — и так будет на любом устройстве. Картинки оптимизированы по объёму (все порядка 5-15Кб).
Видимо, Вы решили это продвигать в массы)
Линк
Линк
Но их нельзя скопировать, на моём Andoid Wildfire они — нечитабельные. При этом есть отличный тег
Код в этом теге подсветится, будет в стиле Хабра, везде легко читаться и легко копироваться.
<source lang="cpp">
<!-- Исходник -->
</source>Код в этом теге подсветится, будет в стиле Хабра, везде легко читаться и легко копироваться.
Ну текст то тоже на официальном хостинге)
Если что, то Карацуба — это не суровый японский самурай, как может показаться, а известный советский математик.
Звали его Анатолий Алексеевич Карацуба.
Звали его Анатолий Алексеевич Карацуба.
Я думаю это стоит добавить к статье. Спасибо, плюсую)
> Если что, то Карацуба — это не суровый японский самурай, как может показаться
А почему самурай? Фамилия же не похожа на японскую.
Я почему-то при прочтении этой фамилии представил колоритного хохла лысого и с чубом.
А почему самурай? Фамилия же не похожа на японскую.
Я почему-то при прочтении этой фамилии представил колоритного хохла лысого и с чубом.
А я, почему-то, прочитал фамилию как Курацаба, и подумал что японец)
Суровый хохол からつば :)
По-моему, хорошая такая японская фамилия. Так как половина, если не больше, японских фамилий — географического происхождения (некие аналоги «имярек с высокой горы», «имярек из далекой деревни, что в топких северных болотах»), «цуба» (場) — одно из наиболее часто встречающихся окончаний, означающих «место». «Кара-цуба» — в зависимости от прочтения, это будет либо «ореховое место», либо «пустое место», либо «китайское место» или «сложное, напряженное место» :)
Впрочем, это все фантазии, ни в одном справочнике японских имен-фамилий «Карацуба» нет :) Есть «Камацуба» и «Кавацуба».
Впрочем, это все фантазии, ни в одном справочнике японских имен-фамилий «Карацуба» нет :) Есть «Камацуба» и «Кавацуба».
Почему-то пограничника Карацупа все знают и никто не сомневается, а вот одной буквой отличается — и всё…
Видимо, Вы решили это продвигать в массы)
Линк
Линк
Не в ту ветку
Прямо как тут :)
Следующую статью обязательно оформлю текстом. Просто я не могу смириться, когда код выглядит непотребно. Надеюсь будет не очень жутко.
У меня есть статьи с огромным количеством кода. Как Вам кажется, смотрится ли он непотребно?
Вот снимок экрана с айфона: http://img830.imageshack.us/i/imagexqh.jpg/. Скажете это нормальные отступы? Или у вас так и есть в коде? Не могу сейчас с компа посмотреть.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
код не смотрел внимательно, но бросилось в глаза то, что нет #undef'a после того как ваш утилитарный макрос стал не нужен.
Я возможно не прав, но по-моему это не алгоритм Карацубы. Приведенный вами алгоритм не имеет никакой ценности казалось бы — для умножения двух чисел длины N он использует 4 умножения чисел длины N/2. То есть по сути ваш алгоритм работает за N^2. Алгоритм перемножения «влоб» тоже будет иметь такую ассимптотику.
Алгоритм Карацубы имеет такой же первый шаг, но использует следующую оптимизацию: рассмотрим (a+b)*(x+y) = (ay+bx) + ax + by.
Вычислим 3 (!) произведения чисел длины N/2 — (a+b)*(x+y), ax, by. Вычтем из первого второе и третье и получим ay+bx. Подсчитаем T^2(ax)+T(ay+bx)+by.
Как-то так.
Алгоритм Карацубы имеет такой же первый шаг, но использует следующую оптимизацию: рассмотрим (a+b)*(x+y) = (ay+bx) + ax + by.
Вычислим 3 (!) произведения чисел длины N/2 — (a+b)*(x+y), ax, by. Вычтем из первого второе и третье и получим ay+bx. Подсчитаем T^2(ax)+T(ay+bx)+by.
Как-то так.
Похоже вы правы. Сейчас перепишу статью. Спасибо!
Посмотрел ещё раз. Да Вы правы, но и я в некотором смысле прав)) Я не могу умножать 128-битные числа, только 64-хбитные. Допишу в статье о возможности сокращения объёма вычислений. Ещё раз Спасибо!
Так и не надо умножать 128-битные.
a = ah * 2^64 + al
b = bh * 2^64 + bl
тогда
a * b = (ah * 2^64 + al) * (bh * 2^64 + bl) = 2^128 * ah * bh + 2^64 * (ah * bl + bh * al) + al * bl
но ah * bl + bh * al = (ah + al) * (bh + bl) — (ah *bh + al * bl)
поэтому вычисляем 3 64-битные умножения: (ah + al) * (bh + bl), ah *bh и al *bl
и радуемся :)
Кстати, алгоритм из статьи (оригинальный) можно найти в «Алгоритмических Трюках для Программиста», там целая глава про умножения была, если мне память не изменяет.
a = ah * 2^64 + al
b = bh * 2^64 + bl
тогда
a * b = (ah * 2^64 + al) * (bh * 2^64 + bl) = 2^128 * ah * bh + 2^64 * (ah * bl + bh * al) + al * bl
но ah * bl + bh * al = (ah + al) * (bh + bl) — (ah *bh + al * bl)
поэтому вычисляем 3 64-битные умножения: (ah + al) * (bh + bl), ah *bh и al *bl
и радуемся :)
Кстати, алгоритм из статьи (оригинальный) можно найти в «Алгоритмических Трюках для Программиста», там целая глава про умножения была, если мне память не изменяет.
Спасибо, поправил статью!
Если бы кто для деления чисел 128-битных через 64-битные алгоритм подсказал.
Быстрое деление делается через быстрое нахождение обратного и быстрое умножение. Быстрое нахождение обратного делается через метод Ньютона решения уравнения 1/x=a, для чего используется быстрое умножение (точнее возведение в квадрат). Практически вы никакого выигрыша для 128-битных чисел не получите.
Медленное деление вполне через 64-битные числа делается — нужно выделять старшие биты, делить их друг на друга, вычитать и повторять снова с уменьшенным делимым.
Медленное деление вполне через 64-битные числа делается — нужно выделять старшие биты, делить их друг на друга, вычитать и повторять снова с уменьшенным делимым.
я помню только тупой «в столбик» :) реализуется через сдвиги и вычитания в цикле.
делить 256 бит на 128 (ну или 128 на 128) с помощью деления на 128 на 64 бита я не уверен что можно… надо думать :)
делить 256 бит на 128 (ну или 128 на 128) с помощью деления на 128 на 64 бита я не уверен что можно… надо думать :)
Отличная книга. По английки зовётся Hacker's Delight, тут можно скачать исходники алгоритмов из книги.
Это ведь нужно для умножение очень преочень больших чисел, как я понимаю? А как можно попробовать умножить реально большие числа, а не 1000 на 2000? я что-то не очень понял. Пробовал так:
Но Dev-C++, например, говорит, что константа слишком велика. Не подскажите каким образом можно использовать такое большое число?
...
typedef unsigned __int64 u8;
typedef unsigned __int64 u16;
typedef unsigned __int64 u32;
u16 a = 17446744073709551615;
...
Но Dev-C++, например, говорит, что константа слишком велика. Не подскажите каким образом можно использовать такое большое число?
Попробуйте так: 17446744073709551615L
И потом непонятно как вы будете печатать 128-битное число на экран…
И потом непонятно как вы будете печатать 128-битное число на экран…
Вы с типами что-то не то сделали напишите 1 строку:
typedef unsigned __int64 u64;ммм, да. Спасибо большое за помощь
А зачем вообще все эти typedef? В стандартном заголовочном файле inttypes.h есть типы данных intX_t/uintX_t, включая int64_t/uint64_t.
Это если код только под Linux.
С моим typedef в Visual Studio тоже работает.
С моим typedef в Visual Studio тоже работает.
Вообще-то, по стандарту C99 положено иметь этот заголовочный файл на любой платформе, равно как и stdint.h. Тем более, по приведённой вами ссылке даже написано, откуда взять файлы для Visual Studio: stdint.h и inttypes.h.
Не берите пример с Microsoft, она как всегда — на стандарты положила болт, а в результате уже понаписаны тонны непортабельного говнокода, килограммы которого я разгребал на предыдущей работе.
Не берите пример с Microsoft, она как всегда — на стандарты положила болт, а в результате уже понаписаны тонны непортабельного говнокода, килограммы которого я разгребал на предыдущей работе.
Спасибо. К сожалению, не работает с L. Как выводить это другой вопрос. Просто хотел попробовать использовать реализованный вами алгоритм.
Следует учесть, что когда берётся разность, то промежуточно надо на 1 бит больше для хранения. То есть получается что-то типа 128*128 => 255 бит, а не 256.
Проверьте на предельные значения.
Проверьте на предельные значения.
Также для данной задачи можно использовать FFT. А используя для хранения чисел массивы, можно получить числа любой длины (ограниченной только объемом свободной памяти). Причем, операции выполняются довольно быстро — перемножение двух 100К значных чисел без оптимизации у меня выполнялось примерно 7с ( данное время можно уменьшить до 1.5 — 2 с).
Интересный факт: при использовании BigDecimal и BigInteger платформы Java, потребовалось около 3 минут (скорее всего, там реализовано просто вычитание/сложение «в столбик»).
Интересный факт: при использовании BigDecimal и BigInteger платформы Java, потребовалось около 3 минут (скорее всего, там реализовано просто вычитание/сложение «в столбик»).
При первом же взгляде на статью бросается в глаза картинка с большой буквой «Х».
Мысль — что статья про проект XNeur.
Мысль — что статья про проект XNeur.
Sign up to leave a comment.
Алгоритм Карацубы для умножения двух чисел